Java集合源码学习(四)HashMap
一、数组、链表和哈希表结构
数据结构中有数组和链表来实现对数据的存储,这两者有不同的应用场景,
数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,插入和删除容易;
哈希表的实现结合了这两点,哈希表的实现方式有多种,在HashMap中使用的是链地址法,也就是拉链法。

拉链法实际上是一种链表数组的结构,由数组加链表组成,在这个长度为16的数组中(HashMap默认初始化大小就是16),每个元素存储的是一个链表的头结点。
通过元素的key的hash值对数组长度取模,将这个元素插入到数组对应位置的链表中。
例如在图中,337%16=1,353%16=1,于是将其插入到数组位置1的链表头结点中。
二、关于HashMap
(1)继承和实现
继承AbstractMap抽象类,Map的一些操作在AbstractMap里已经提供了默认实现,
实现Map接口,可以应用Map接口定义的一些操作,明确HashMap属于Map体系,
Cloneable接口,表明HashMap对象会重写java.lang.Object#clone()方法,HashMap实现的是浅拷贝(shallow copy),
Serializable接口,表明HashMap对象可以被序列化
(2)内部数据结构
HashMap的实际数据存储在Entry类的数组中,
上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[]。
/**
* 内部实际的存储数组,如果需要调整,容量必须是2的幂
*/
transient Entry[] table;
再来看一下Entry这个内部静态类,
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;//Key-value结构的key
V value;//存储值
Entry<K,V> next;//指向下一个链表节点
final int hash;//哈希值
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
......
}
(3)线程安全
HashMap是非同步的,即线程不安全,在多线程条件下,可能出现很多问题,
1.多线程put后可能导致get死循环,具体表现为CPU使用率100%(put的时候transfer方法循环将旧数组中的链表移动到新数组)
2.多线程put的时候可能导致元素丢失(在addEntry方法的new Entry<K,V>(hash, key, value, e),如果两个线程都同时取得了e,则他们下一个元素都是e,然后赋值给table元素的时候有一个成功有一个丢失)
关于HashMap线程安全性更多的了解参考相关的网上资源,这里不多叙述。
需要线程安全的哈希表结构,可以考虑以下的方式:
使用Hashtable 类,Hashtable 是线程安全的;
使用并发包下的java.util.concurrent.ConcurrentHashMap,ConcurrentHashMap实现了更高级的线程安全;
或者使用synchronizedMap() 同步方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作。
如:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
三、常用方法
(1)Map接口定义的方法
HashMap可以应用所有Map接口定义的方法:
public interface Map<K,V> {
public static interface Entry<K,V> {
//获取该Entry的key
public abstract Object getKey();
//获取该Entry的value
public abstract Object getValue();
//设置Entry的value
public abstract Object setValue(Object obj);
public abstract boolean equals(Object obj);
public abstract int hashCode();
}
//返回键值对的数目
int size();
//判断容器是否为空
boolean isEmpty();
//判断容器是否包含关键字key
boolean containsKey(Object key);
//判断容器是否包含值value
boolean containsValue(Object value);
//根据key获取value
Object get(Object key);
//向容器中加入新的key-value对
Object put(Object key, Object value);
//根据key移除相应的键值对
Object remove(Object key);
//将另一个Map中的所有键值对都添加进去
void putAll(Map<? extends K, ? extends V> m);
//清除容器中的所有键值对
void clear();
//返回容器中所有的key组成的Set集合
Set keySet();
//返回所有的value组成的集合
Collection values();
//返回所有的键值对
Set<Map.Entry<K, V>> entrySet();
//继承自Object的方法
boolean equals(Object obj);
int hashCode();
}
(2)构造方法
HashMap使用Entry[] 数组存储数据,
另外维护了两个非常重要的变量:initialCapacity(初始容量)、loadFactor(加载因子)。
初始容量就是初始构造数组的大小,可以指定任何值,
但最后HashMap内部都会将其转成一个大于指定值的最小的2的幂,比如指定初始容量12,但最后会变成16,指定16,最后就是16。
加载因子是控制数组table的饱和度的,默认的加载因子是0.75,
DEFAULT_LOAD_FACTOR = 0.75f;
也就是数组达到容量的75%,就会自动的扩容。
另外,HashMap的最大容量是2^30,
static final int MAXIMUM_CAPACITY = 1 << 30;
默认的初始化大小是16,
static final int DEFAULT_INITIAL_CAPACITY = 16;
HashMap提供了四种构造方法,可以使用默认的容量等进行初始化,
也可以显式制定大小和加载因子,还可以使用另外的map进行构造和初始化。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
putAllForCreate(m);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
......
}
四、解决哈希冲突的办法
(1)什么是哈希冲突
理论上哈希函数的输入域是无限的,优秀的哈希函数可以将冲突减少到最低,但是却不能避免,下面是一个典型的哈希冲突的例子:
用班级同学做比喻,现有如下同学数据
张三,李四,王五,赵刚,吴露.....
假如我们编址规则为取姓氏中姓的开头字母在字母表的相对位置作为地址,则会产生如下的哈希表
位置 字母 姓名 0 a 1 b 2 c ...
10 L 李四 ...
22 W 王五,吴露 ..
25 Z 张三,赵刚 我们注意到,灰色背景标示的两行里面,关键字王五,吴露被编到了同一个位置,关键字张三,赵刚也被编到了同一个位置。老师再拿号来找张三,座位上有两个人,"你们俩谁是张三?"(这段描述很形象,引用自hash是如何处理冲突的?)
(2)解决哈希冲突的方法
常见的办法开放定址法,再哈希法,链地址法以及建立一个公共溢出区等,这里只考察链地址法。
链地址法就是最开始我们提到的链表-数组结构,
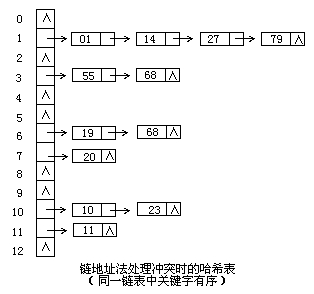
将所有关键字为同义词的记录存储在同一线性链表中。
五、源码分析
(1)HashMap的存取实现
HashMap的存取主要是put和get操作的实现。
执行put方法时根据key的hash值来计算放到table数组的下标,
如果hash到相同的下标,则新put进去的元素放到Entry链的头部。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
get操作的实现:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next)
{ Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
注意HashMap支持key=null的情况,看这个代码:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
......
}
(2)哈希函数
下面看一下HashMap使用的哈希函数,源码来自JDK1.6:
/**
* 哈希函数
* 看一下具体的操作,首先对h分别进行无符号右移20位和12位,
* 然后对两个值进行按位异或,最后再与h进行按位异或,
* 得到新的h后再进行一次同样的操作,分别右移7位和4位,具体的哈希函数优劣就不去研究了
* 这个方法可以尽量减少碰撞
*/
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
(3)再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。
当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一个新的table数组,将table数组的元素转移到新的table数组中。
/**
* 再散列过程
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
} Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
} /**
* 把当前Entry[]表的全部元素转移到新的table中
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
参考
Java集合源码学习(四)HashMap的更多相关文章
- Java集合源码学习(一)集合框架概览
>>集合框架 Java集合框架包含了大部分Java开发中用到的数据结构,主要包括List列表.Set集合.Map映射.迭代器(Iterator.Enumeration).工具类(Array ...
- Java集合源码学习(四)HashMap分析
ArrayList.LinkedList和HashMap的源码是一起看的,横向对比吧,感觉对这三种数据结构的理解加深了很多. >>数组.链表和哈希表结构 数据结构中有数组和链表来实现对数据 ...
- 转:【Java集合源码剖析】HashMap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36034955 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
- 【Java集合源码剖析】HashMap源码剖析
转载出处:http://blog.csdn.net/ns_code/article/details/36034955 HashMap简介 HashMap是基于哈希表实现的,每一个元素是一个key-va ...
- Java集合源码学习(五)几种常用集合类的比较
这篇笔记对几个常用的集合实现,从效率,线程安全和应用场景进行综合比较. >>ArrayList.LinkedList与Vector的对比 (1)相同和不同都实现了List接口,使用类似.V ...
- Java集合源码学习(三)LinkedList分析
前面学习了ArrayList的源码,数组是顺序存储结构,存储区间是连续的,占用内存严重,故空间复杂度很大.但数组的二分查找时间复杂度小,为O(1),数组的特点是寻址容易,插入和删除困难.今天学习另外的 ...
- Java集合源码学习(三)LinkedList
前面学习了ArrayList的源码,数组是顺序存储结构,存储区间是连续的,占用内存严重,故空间复杂度很大.但数组的二分查找时间复杂度小,为O(1),数组的特点是寻址容易,插入和删除困难.今天学习另外的 ...
- Java集合源码阅读之HashMap
基于jdk1.8的HashMap源码分析. 引用于:http://blog.stormma.me/2017/05/31/Java%E9%9B%86%E5%90%88%E6%BA%90%E7%A0%81 ...
- Java集合源码学习(二)ArrayList分析
>>关于ArrayList ArrayList直接继承AbstractList,实现了List. RandomAccess.Cloneable.Serializable接口,为什么叫&qu ...
随机推荐
- VB中的冒号——bug
关于VB中的冒号,给许多人的印象都是:“一行可书写几句语句”.这么说是对的,但是有一种情况是不对的,那就是在条件语句中.这也是做一个VB项目升级的时候遇到,因为这个问题我查了好长时间程序,一直在找VB ...
- 【转】Java并发编程:并发容器之ConcurrentHashMap
JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全性,所以这种方法的代价就是严重降低了 ...
- Unity3D游戏开发框架-资源管理类ResourceManage
新建文件夹:ResMgr.接着新建三个C#脚本.代码如下: IResLoadListener.cs AssetInfo.cs ResMgr.cs using UnityEngine; using Sy ...
- jquery $.trim()去除字符串空格
语法jQuery.trim()函数用于去除字符串两端的空白字符. 作用该函数可以去除字符串开始和末尾两端的空白字符(直到遇到第一个非空白字符串为止).它会清除包括换行符.空格.制表符等常见的空白字符. ...
- 在Centos7 上安装SVN
https://blog.csdn.net/crossangles_2017/article/details/78553266 1.安装 使用yum安装非常简单: yum install subver ...
- oracle 新增一条数据时设置id自增
CREATE SEQUENCE test_seq --创建一个test_seq序列INCREMENT BY 1 --每次加1START WITH 1 --从1开始NOMAXVALUE ...
- iOS -- Effective Objective-C 阅读笔记 (1)
1: 在类的头文件中尽量 少 的引用其他头文件,尽量用 @class xxxxxx; 理解: 当你创建了一个 A 类,这个类又 需要具有 B 类的实例, 你可以直接为 A 类添加 B 类类型的 属性, ...
- 查看MySQL版本的命令及常用命令
Windows / Linux 系统 前提是已经正确安装了 MySQL,打开 Windows 系统中的命令行工具(Win + R --> 输入 cmd 并按下回车键)--> 输入命令: m ...
- Confluence 6 管理 Atlassian 提供的 App
Confluence 用户可以使用桌面应用来编辑一个已经上传到 Confluence 的文件,然后这个文件自动保存回 Confluence. 这个下载和上传的过程是通过 Atlassian Compa ...
- vue的多选框