总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。
- 有状态的流数据处理;
- Flink中的状态接口;
- 状态管理和容错机制实现;
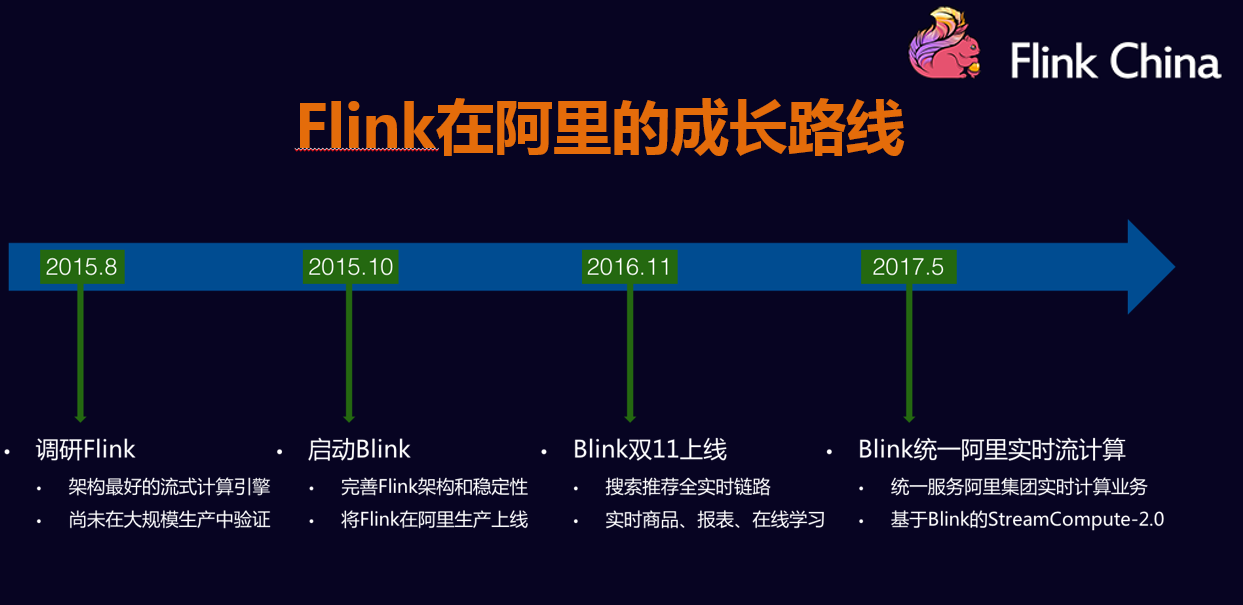
- 阿里相关工作介绍;
- 状态数据的存储和访问;
- 状态数据的备份和恢复;
- 状态数据的划分和动态扩容;

- 流计算系统的任务和Hbase的数据存储有可能不在同一台机器上,导致性能会很差。这样经常会做远端的访问,走网络和存储;
- 备份和恢复是比较困难,因为Hbase是没有回滚的,要做到Exactly onces很困难。在分布式环境下,如果程序出现故障,只能重启Storm,那么Hbase的数据也就无法回滚到之前的状态。比如广告计费的这种场景,Storm+Hbase是是行不通的,出现的问题是钱可能就会多算,解决以上的办法是Storm+mysql,通过mysql的回滚解决一致性的问题。但是架构会变得非常复杂。性能也会很差,要commit确保数据的一致性。
- 对于storm而言状态数据的划分和动态扩容也是非常难做,一个很严重的问题是所有用户都会在strom上重复的做这些工作,比如搜索,广告都要在做一遍,由此限制了部门的业务发展。

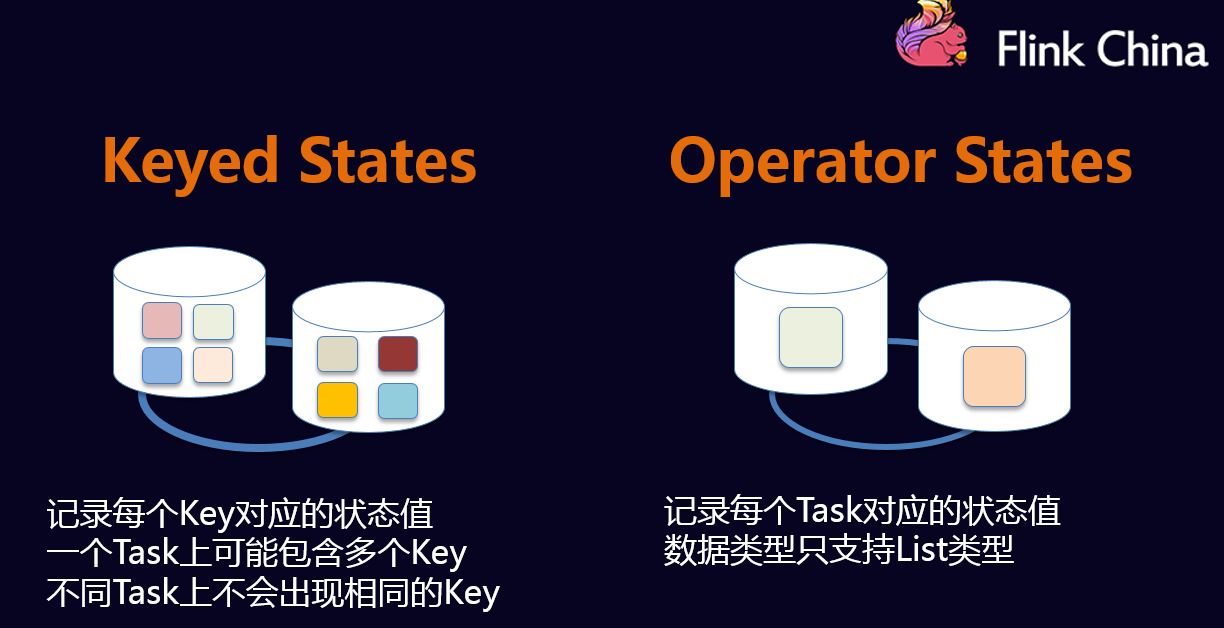
- Keyed States
- Operator States




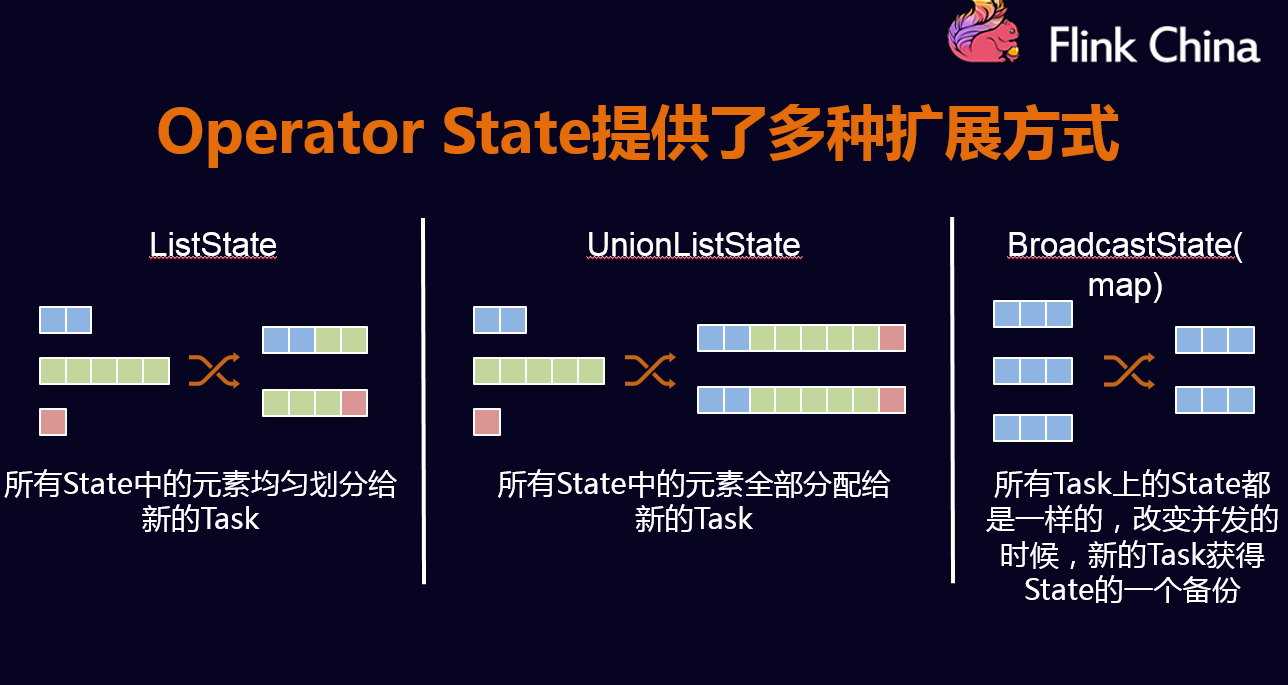
- ListState:并发度在改变的时候,会将并发上的每个List都取出,然后把这些List合并到一个新的List,然后根据元素的个数在均匀分配给新的Task;
- UnionListState:相比于ListState更加灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来的List拼接起来。然后不做划分,直接交给用户;
- BroadcastState:如大表和小表做Join时,小表可以直接广播给大表的分区,在每个并发上的数据都是完全一致的。做的更新也相同,当改变并发的时候,把这些数据COPY到新的Task即可
- AT LEAST ONCE;
- Exactly once;

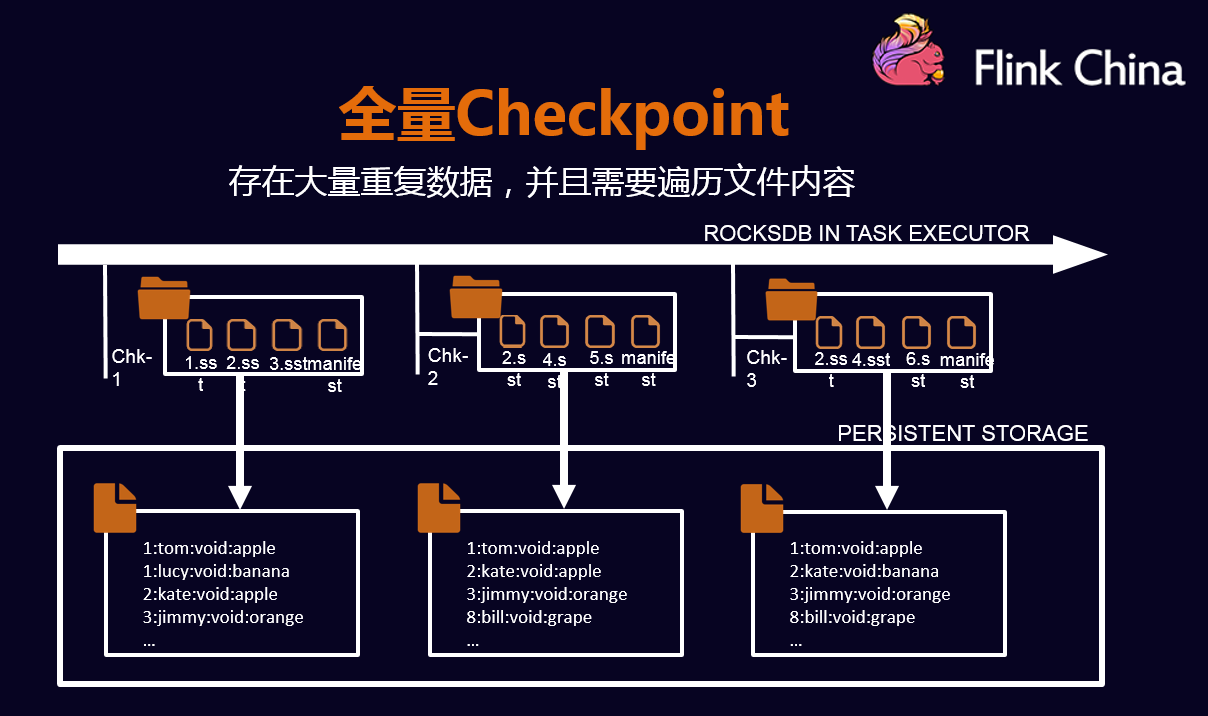
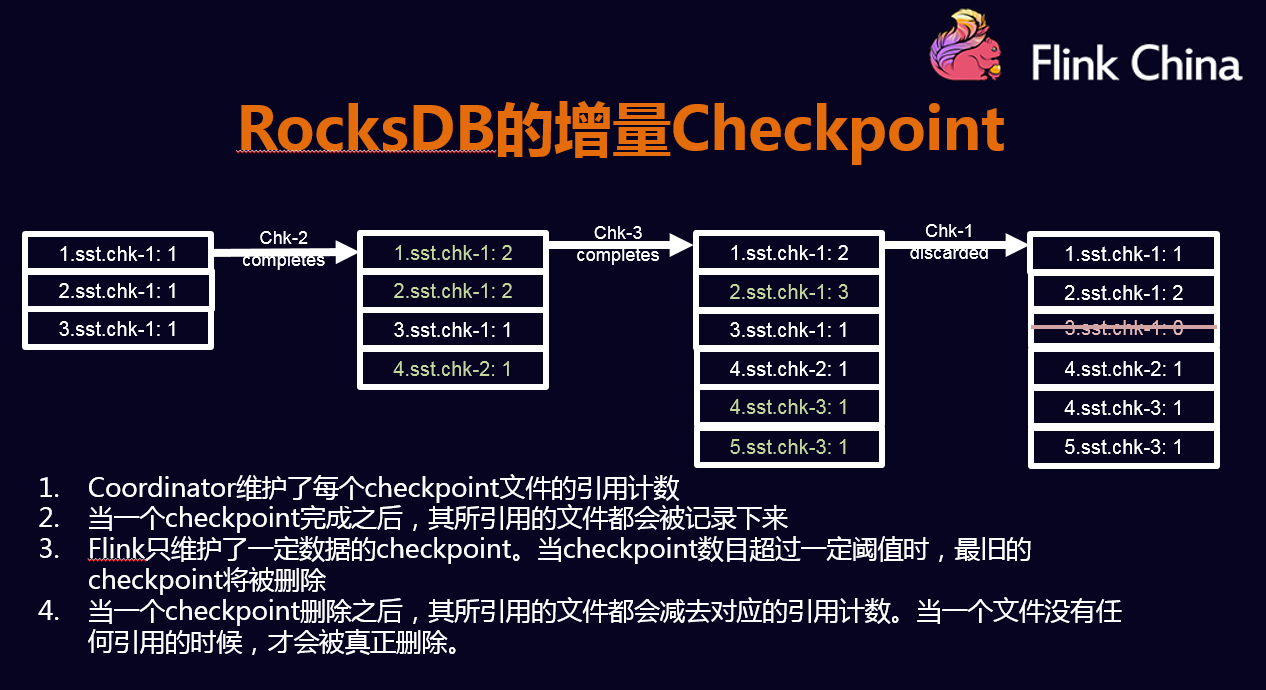
- Savepoint:是一种特殊的checkpoint,只不过不像checkpoint定期的从系统中去触发的,它是用户通过命令触发,存储格式和checkpoint也是不相同的,会将数据按照一个标准的格式存储,不管配置什么样,Flink都会从这个checkpoint恢复,是用来做版本升级一个非常好的工具;
- External Checkpoint:对已有checkpoint的一种扩展,就是说做完一次内部的一次Checkpoint后,还会在用户给定的一个目录中,多存储一份checkpoint的数据;

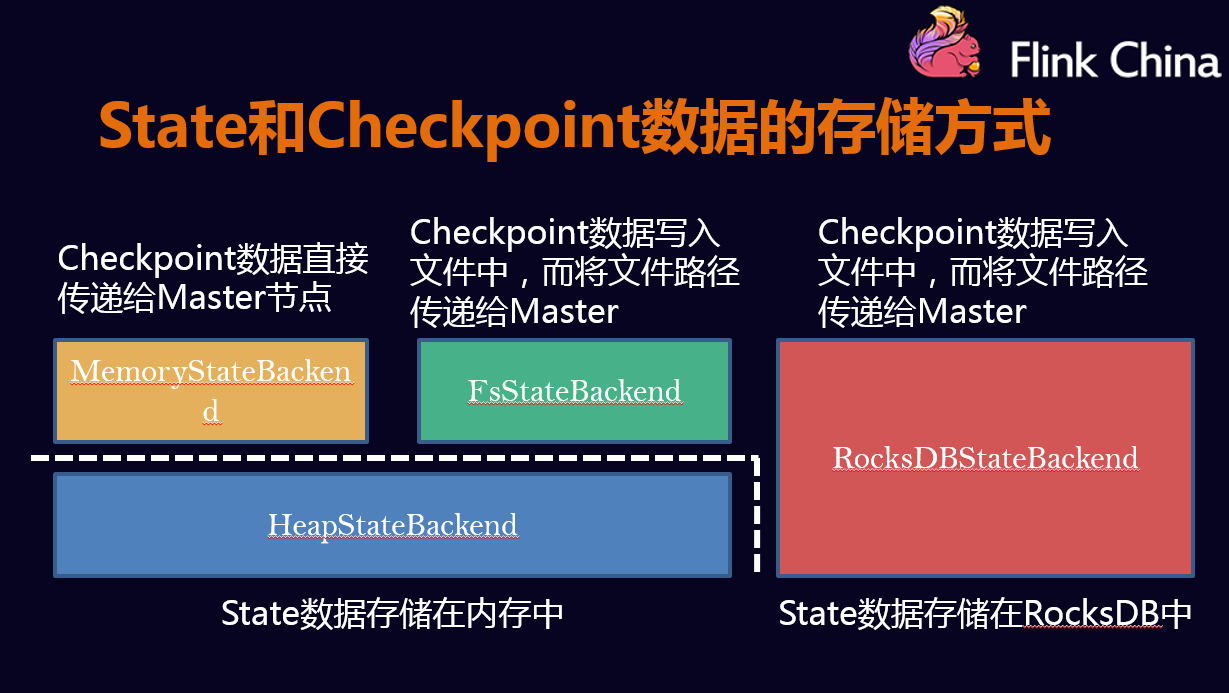
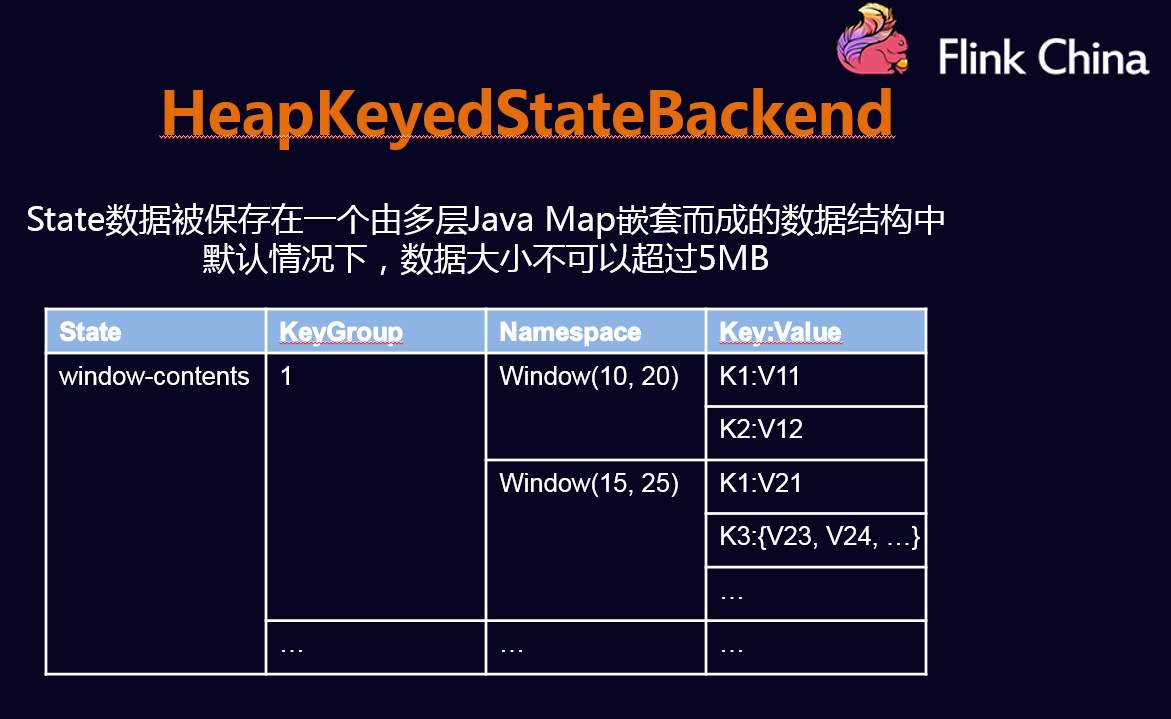
- MemoryStateBackend
- FsStateBackend
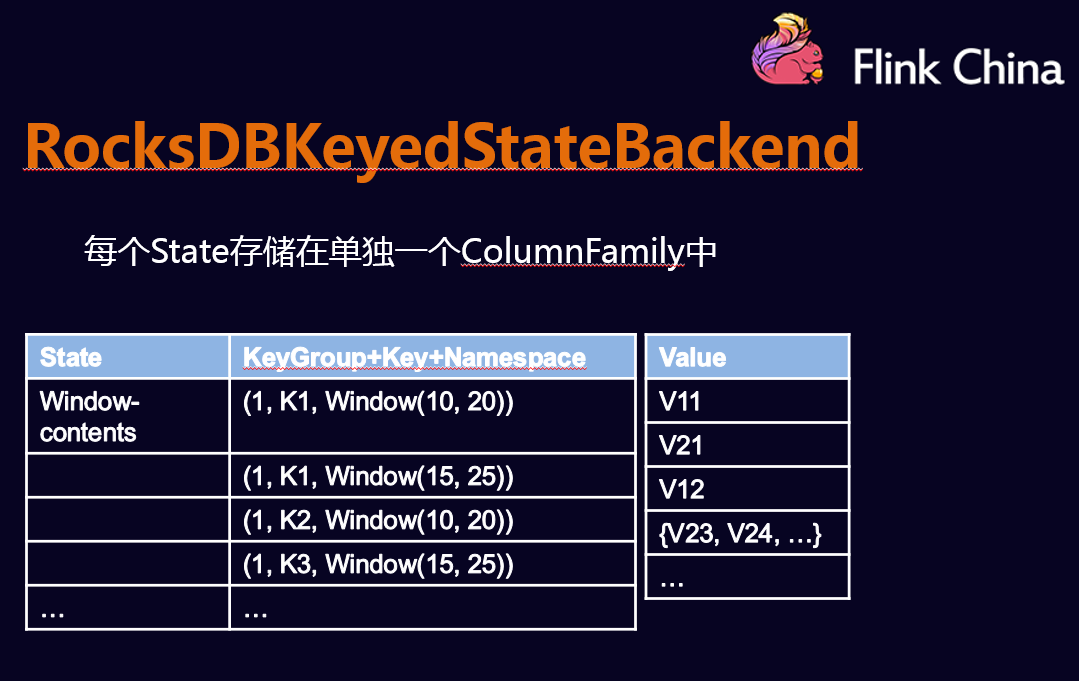
- RockDBStateBackend




总结Flink状态管理和容错机制的更多相关文章
- Flink状态管理和容错机制介绍
本文主要内容如下: 有状态的流数据处理: Flink中的状态接口: 状态管理和容错机制实现: 阿里相关工作介绍: 一.有状态的流数据处理# 1.1.什么是有状态的计算# 计算任务的结果不仅仅依赖于输入 ...
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- 「Flink」Flink的状态管理与容错
在Flink中的每个函数和运算符都是有状态的.在处理过程中可以用状态来存储数据,这样可以利用状态来构建复杂操作.为了让状态容错,Flink需要设置checkpoint状态.Flink程序是通过chec ...
- Flink状态管理与状态一致性(长文)
目录 一.前言 二.状态类型 2.1.Keyed State 2.2.Operator State 三.状态横向扩展 四.检查点机制 4.1.开启检查点 (checkpoint) 4.2.保存点机制 ...
- Flink的状态管理与恢复机制
参考地址:https://www.cnblogs.com/airnew/p/9544683.html 问题一.什么是状态? 问题二.Flink状态类型有哪几种? 问题三.状态有什么作用? 问题四.如何 ...
- Flink的状态编程和容错机制(四)
一.状态编程 Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据.例如 : ProcessWi ...
- Flutter 对状态管理的认知与思考
前言 由 编程技术交流圣地[-Flutter群-] 发起的 状态管理研究小组,将就 状态管理 相关话题进行为期 两个月 的讨论. 目前只有内定的 5 个人参与讨论,如果你对 状态管理 有什么独特的见解 ...
- Flink 容错机制与状态
简介 Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态. 该机制确保即使出现故障,经过恢复,程序的状态也会回到以前的状态. Flink 主持 at least once 语 ...
- 关于 Flink 状态与容错机制
Flink 作为新一代基于事件流的.真正意义上的流批一体的大数据处理引擎,正在逐渐得到广大开发者们的青睐.就从我自身的视角看,最近也是在数据团队把一些原本由 Flume.SparkStreaming. ...
随机推荐
- HDU contest808 ACM多校第7场 Problem - 1008: Traffic Network in Numazu
首先嘚瑟一下这场比赛的排名:59 (第一次看到这么多 √ emmmm) 好了进入正文QAQ ...这道题啊,思路很清晰啊. 首先你看到树上路径边权和,然后还带修改,不是显然可以想到 树剖+线段树 维护 ...
- sugarCRM文档翻译1
2018-3-9 14:42:14 星期五 本文分两部分: 第一部分是从index.php入口开始的代码执行的部分流程 第二部分是对官方文档的翻译 第一部分: 流程: 入口文件: index.php ...
- configure.*和Makefile.*之间的关系
现在很多项目都在使用GUI编译器,Kdevelop\Eclipse等等,诚然它给我们提供了极大地便利,但我们仍需要简单了解编译的过程.本文旨在简单叙述由源码(*.cpp & *.h)经过编译得 ...
- hive学习02-累加
求出当月的访问次数,截至当月前的每个月最大访问次数.截至当月前每个用户总的访问次数. 数据表如下 A,-, A,-, B,-, A,-, B,-, A,-, A,-, A,-, B,-, B,-, A ...
- layui前端框架
项目中需要弹出层效果,使用了layui前端框架,主要使用了里面的弹出层特效(可以移动) html代码 要给这个标签绑定click方法 <a href='javascript:;' data-me ...
- C# 制作向导
1.FormBase界面:有“帮助,上一步,下一步,取消”按钮,这些按钮放置在一个Panel上. namespace DataBase { public partial class FormB ...
- poj2817状态压缩 升维
/* 两两求出字符串之间最大可以匹配的值 由已知状态推导出位置状态 状态s表示已经加入到集合中的字符串,0表示串i不存在,1存在 由于字符串的加入顺序会影响结果,所以增加一维来表示 dp[S][i]表 ...
- re模块(正则)
一, 什么是正则? 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法. 在python中,正则内嵌在python中,并通过re模块实现,正则表达模式被编译成一系列 ...
- springboot+mybatis+springMVC基础框架搭建
项目结构概览 pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http: ...
- jenkins原理
原理:Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能. 直白的说:这个jenkins是CI ...