sklearn-woe/iv-乳腺癌分类器实战

医药统计项目联系QQ:231469242
如果样本量太小,数据必须做分段化处理,否则会有很多空缺数据,woe效果不能有效发挥
随机森林结果

iv》0.02的因子在随机森林结果里都属于有效因子,但是随机森林重要性最强的因子没有出现在有效iv参数里,说明这些缺失重要变量没有做分段处理,数据离散造成。
数据文件
脚本备份
step1_customers_split_goodOrBad.py
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 14 21:45:43 2018 @author QQ:231469242 把数据源分类为两个Excel,好客户Excel数据和坏客户Excel数据
""" import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #读取文件
readFileName="breast_cancer_总.xlsx" #保存文件
saveFileName_good="result_good.xlsx"
saveFileName_bad="result_bad.xlsx" #读取excel
df=pd.read_excel(readFileName)
#帅选数据
df_good=df[df.diagnosis=="B"]
df_bad=df[df.diagnosis=="M"] #保存数据
df_good.to_excel(saveFileName_good, sheet_name='Sheet1')
df_bad.to_excel(saveFileName_bad, sheet_name='Sheet1')
step2_automate_find_informative_variables.py
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 14 22:13:30 2018 @author: QQ:231469242
woe负数,好客户<坏客户
woe正数,好客户>坏客户
""" import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os #创建save文件
newFile=os.mkdir("save/") #读取文件
FileName_good="result_good.xlsx"
FileName_bad="result_bad.xlsx" #保存文件
saveFileName="result_woe_iv.xlsx" #读取excel
df_good=pd.read_excel(FileName_good)
df_bad=pd.read_excel(FileName_bad) #所有变量列表
list_columns=list(df_good.columns[:-1]) index=0 def Ratio_goodDevideBad(index):
#第一列字段名(好客户属性)
columnName=list(df_good.columns)[index] #第一列好客户内容和第二列坏客户内容
column_goodCustomers=df_good[columnName]
column_badCustomers=df_bad[columnName] #去掉NAN
num_goodCustomers=column_goodCustomers.dropna()
#统计数量
num_goodCustomers=num_goodCustomers.size #去掉NAN
num_badCustomers=column_badCustomers.dropna()
#统计数量
num_badCustomers=num_badCustomers.size #第一列频率分析
frenquency_goodCustomers=column_goodCustomers.value_counts()
#第二列频率分析
frenquency_badCustomers=column_badCustomers.value_counts() #各个元素占比
ratio_goodCustomers=frenquency_goodCustomers/num_goodCustomers
ratio_badCustomers=frenquency_badCustomers/num_badCustomers
#最终好坏比例
ratio_goodDevideBad=ratio_goodCustomers/ratio_badCustomers
return (columnName,num_goodCustomers,num_badCustomers,frenquency_goodCustomers,frenquency_badCustomers,ratio_goodCustomers,ratio_badCustomers,ratio_goodDevideBad) #woe函数,阵列计算
def Woe(ratio_goodDevideBad):
woe=np.log(ratio_goodDevideBad)
return woe '''
#iv函数,阵列计算
def Iv(woe):
iv=(ratio_goodCustomers-ratio_badCustomers)*woe
return iv
''' #iv参数评估,参数iv_sum(变量iv总值)
def Iv_estimate(iv_sum):
#如果iv值大于0.02,为有效因子
if iv_sum>0.02:
print("informative")
return "A"
#评估能力一般
else:
print("not informative")
return "B" '''
#详细参数输出
def Print():
print ("columnName:",columnName)
Iv_estimate(iv_sum)
print("iv_sum",iv_sum)
#print("",)
#print("",)
''' #详细参数保存到excel,save文件里
def Write_singleVariable_to_Excel(index):
#index为变量索引,第一个变量,index=0
ratio=Ratio_goodDevideBad(index)
columnName,num_goodCustomers,num_badCustomers,frenquency_goodCustomers,frenquency_badCustomers,ratio_goodCustomers,ratio_badCustomers,ratio_goodDevideBad=ratio[0],ratio[1],ratio[2],ratio[3],ratio[4],ratio[5],ratio[6],ratio[7] woe=Woe(ratio_goodDevideBad)
iv=(ratio_goodCustomers-ratio_badCustomers)*woe df_woe_iv=pd.DataFrame({"num_goodCustomers":num_goodCustomers,"num_badCustomers":num_badCustomers,"frenquency_goodCustomers":frenquency_goodCustomers,
"frenquency_badCustomers":frenquency_badCustomers,"ratio_goodCustomers":ratio_goodCustomers,
"ratio_badCustomers":ratio_badCustomers,"ratio_goodDevideBad":ratio_goodDevideBad,
"woe":woe,"iv":iv},columns=["num_goodCustomers","num_badCustomers","frenquency_goodCustomers","frenquency_badCustomers",
"ratio_goodCustomers","ratio_badCustomers","ratio_goodDevideBad","woe","iv"]) #sort_values(by=...)用于对指定字段排序
df_sort=df_woe_iv.sort_values(by='iv',ascending=False) #ratio_badDevideGood数据写入到result_compare_badDevideGood.xlsx文件
df_sort.to_excel("save/"+columnName+".xlsx") #计算iv总和,评估整体变量
iv_sum=sum([i for i in iv if np.isnan(i)!=True]) print ("变量:",columnName)
#iv参数评估,参数iv_sum(变量iv总值)
iv_estimate=Iv_estimate(iv_sum)
print("iv_sum",iv_sum)
return iv_estimate,columnName #y\有价值变量列表存储器
list_Informative_variables=[] #写入所有变量参数,保存到excel里,save文件
for i in range(len(list_columns)):
status=Write_singleVariable_to_Excel(i)[0]
columnName=Write_singleVariable_to_Excel(i)[1] if status=="A":
list_Informative_variables.append(columnName)
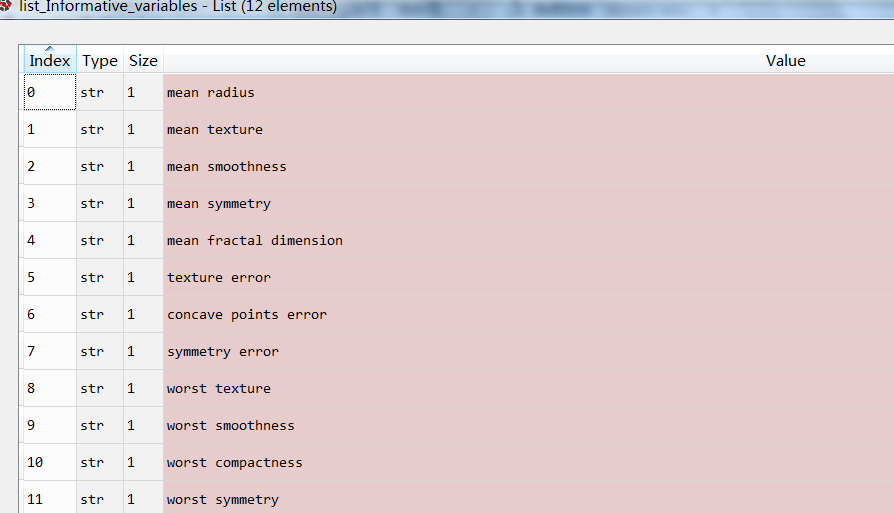
最终得到一部分有效因子,共12个,经过数据分段化处理,会得到更多有效因子。

sklearn-woe/iv-乳腺癌分类器实战的更多相关文章
- 基于sklearn的分类器实战
已迁移到我新博客,阅读体验更佳基于sklearn的分类器实战 完整代码实现见github:click me 一.实验说明 1.1 任务描述 1.2 数据说明 一共有十个数据集,数据集中的数据属性有全部 ...
- 【导包】使用Sklearn构建Logistic回归分类器
官方英文文档地址:http://scikit-learn.org/dev/modules/generated/sklearn.linear_model.LogisticRegression.html# ...
- sklearn_随机森林random forest原理_乳腺癌分类器建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 决策树decision tree原理介绍_python sklearn建模_乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 『Kaggle』Sklearn中几种分类器的调用&词袋建立
几种分类器的基本调用方法 本节的目的是基本的使用这些工具,达到熟悉sklearn的流程而已,既不会设计超参数的选择原理(后面会进行介绍),也不会介绍数学原理(应该不会涉及了,打公式超麻烦,而且近期也没 ...
- 线性Softmax分类器实战
1 概述 基础的理论知识参考线性SVM与Softmax分类器. 代码实现环境:python3 2 数据预处理 2.1 加载数据 将原始数据集放入"data/cifar10/"文件夹 ...
- 线性SVM分类器实战
1 概述 基础的理论知识参考线性SVM与Softmax分类器. 代码实现环境:python3 2 数据处理 2.1 加载数据集 将原始数据集放入"data/cifar10/"文件夹 ...
- 【转】风控中的特征评价指标(一)——IV和WOE
转自:https://zhuanlan.zhihu.com/p/78809853 1.IV值的用途 IV,即信息价值(Information Value),也称信息量. 目前还只是在对LR建模时用到过 ...
- 神经网络1_neuron network原理_python sklearn建模乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
随机推荐
- Nginx proxy_protocol协议
L:113
- HTTP协议那些事儿(Web开发补充知识点)
HTTP协议 超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式.协作式和超媒体信息系统的应用层协议.HTTP是万维网的数据通信的基础. H ...
- GitHub大佬:供计算机学习鉴黄功能的图片数据库
ps:学无止境 想要构建一套鉴黄系统,必须有大量的真实图片供计算机进行学习,以便于区分开正常图片和黄色图片. 近期有位加拿大程序员在Github上传了图片列表,里面包含了大量图片地址可以供计算机进行学 ...
- Android Spinner 绑定键值对
这里给大家提供下绑定 spinner键值对的方法. 首先创建绑定模型BaseItem public class BaseItem { public BaseItem(Integer id,String ...
- P1601 A+B Problem(高精)
原题链接 https://www.luogu.org/problemnew/show/P1601 这个题提示的很清楚,并非简单的A+B,单纯的long long型也不行(不要被样例所迷惑).因为lo ...
- 一个模拟——抢票部分功能的 简单版(主要实例化一下 Lock 的使用)
""" 抢票! 多个用户在同时读写同一个数据 """ from multiprocessing import Process,Lock im ...
- 使用docker部署springboot
首先创建一个简单的springboot web项目 创建一个 DockerController,在其中有一个index()方法,访问时返回:Hello Docker! @RestController ...
- python通过配置文件连接数据库
今天主要是通过读取配置文件(ini文件)获取数据库表的ip,端口,用户,密码,表名等,使用pysql来操作数据库,具体的ini配置文件的操作参见我另一篇博客:https://www.cnblogs.c ...
- windows 设置ipsec防火墙
windows server 推荐使用ipsec修改防火墙设置,默认防火墙需要手动导入导出.wfw文件,需要手动添加单条规则,维护麻烦,推荐关闭,使用ipsec管理 以下是线上防火墙配置,可参照业务环 ...
- LOJ#6284. 数列分块入门 8
分块的时候开一个数组标记这个区间是不是都是一样颜色的部分,如果是的话,我后面的查询,更新部分就可以直接整块操作,对于不是不全部都一样颜色的块在具体进到快里面去暴力. 在更新的时候对边上的两个不完整的块 ...