《从Paxos到ZooKeeper 分布式一致性原理与实践》读书笔记
一、分布式架构
1、分布式特点
- 分布性
- 对等性。分布式系统中的所有计算机节点都是对等的
- 并发性。多个节点并发的操作一些共享的资源
- 缺乏全局时钟。节点之间通过消息传递进行通信和协调,因为缺乏全局时钟,很难定义两个事件谁先谁后
- 故障总是会发生。系统设计时,需要考虑到任何异常情况
2、分布式环境的各种问题
- 通信异常。分布式系统中的某些节点之间无法正常通信
- 网络分区。这有部分节点可以正常通信,有些无法正常通信。这种现象称为网络分区,也称为“脑裂”
- 三态。节点之间的一次通信存在三种状态:成功、失败、超时
- 节点故障。节点机器宕机、失去回应
3、传统事务的ACID理论。
- 原子性(Atomicity)。事务内的所有操作要么全部成功,要么全部失败
- 一致性(Consistency)。事务的执行不能破坏数据库的一致性。如果事务执行一半停了,一部分的修改写入的数据库。这时候,数据库就处于一种不正确的状态,或者说不一致的状态
- 隔离性(Isolation)。多个事务并发执行,彼此不会受影响。事务的隔离级别:读未提交(可能发生脏读、重复读、幻象读)、读已提交(肯能发生重复读、幻象读)、可重复读(可能发生幻象读)、串行化。隔离级别越高,对并发的性能影响越大,越能保证数据库的一致性。
- 持久性(Durablility)。一旦事务成功提交,它对于数据的修改就被永久保存下来
4、分布式事务的CAP理论和BASE理论
- CAP理论。一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance),在分布式系统中,最多只能满足其中的两项。
- BASE理论。基本可用(Basically Available)、软状态(Soft state)、最终一致性(Eventually consistent)。基本可用指系统出现故障时,允许损失部分可用性,包括响应时间的损失和功能上的系统降级;软状态指允许节点间的通讯出现中间状态;最终一致指系统的所有的数据副本,在一定时间的同步后,最终能够达到一致的状态
二、一致性协议
1、2PC。二阶段提交协议
阶段一,执行事务
- 事务询问。协调者向所有参与者发送事务内容,等待参与者回应
- 执行事务。参与者执行事务,记录Undo和Redo日志
- 反馈事务询问响应,参与者返回给协调者Yes或No响应。全部返回Yes,进入提交事务阶段;存在No返回或者超时,进入中断事务阶段
阶段二,提交事务
- 发送事务提交请求
- 各个参与者提交事务
- 参与者反馈事务提交结果
- 如果参与者全部返回Yes,完成事务;存在返回No,进入中断事务阶段
中断事务阶段
- 发送回滚请求
- 事务回滚
- 反馈事务回滚结果
- 完成中断事务
2PC的缺点
- 同步阻塞。各个参与者在等待其他参与者响应的同时,无法进行任何操作,处于阻塞状态
- 单点问题。过度依赖协调者,一旦协调者出现问题,系统将无法正常运转
- 数据不一致。同上一条,一旦协调者出现问题,就可能出现各个参与者数据不一致的问题
- 太过保守。一旦参与者出现故障,协调者只能通过自己的超时机制发现。
2、3PC。三阶段提交协议
阶段一,CanCommit,事务询问
- 事务询问,询问各个参与者能否完成事务
- 各个参与者返回响应,全部返回Yes,进入PreCommit阶段
阶段二,PreCommit,事务预提交
- 发送预提交请求
- 事务预提交。参与者执行事务操作,记录Undo和Redo日志
- 参与者返回响应。全部返回Yes,继续三阶段;返回No,进入中断事务阶段
阶段三,DoCommit,真正的事务提交
- 发送提交请求
- 参与者正式执行事务提交操作
- 返回协调者事务执行结果
- 协调者完成事务。如果存在返回No或者返回超时,进入中断事务阶段
中断事务阶段
- 发送回滚请求
- 事务回滚
- 反馈事务回滚结果
- 完成中断事务
3PC优缺点
- 相较于2PC,3PC最大优点就是降低了参与者的阻塞范围
- 缺点是,还是避免不了出现数据不一致的情况
3、Paxos算法
拜占庭将军问题,拜占庭帝国的不同军队处于不同的地理问题,他们之间只能通过通讯员进行通讯,但是通讯员是不可靠的,可能篡改消息
由于加密算法和校验算法的出现,所有实际的分布式系统之间的通讯,不存在数据被篡改的可能。
四、ZooKeeper和ZAB协议介绍
1、初识ZeeKeeper
ZooKeeper可以做什么
可以基于它实现负载均衡、集群管理、Master选举、分布式队列、分布式锁、命名服务、数据发布/订阅等功能
Zookeeper能保证的分布式一致性特性
- 顺序一致性。同一个客户端发起的请求,会严格按照发起顺序执行
- 原子性。对于一个事务请求,集群中的所有机器的执行情况是一致的
- 可靠性。一旦服务端成功的应用了一个事务,并完成了对客户端的响应。服务端的状态会一直保存下来
- 实时性。保证在一段时间内的实时性
- 单一视图。无论客户端连接的是哪一个服务器,看到的服务端的数据模型都是一致的
Zookeeper的设计目标
- 简单的数据模型。Zookeeper将去数据存储在内存中,采用树形结构存储,树由ZNode节点构成
- 可以构建集群。只有集群中超过一半机器能够正常运作,整个集群就可以正常对外提供服务。
- 顺序访问。每个来自客户端的请求,都会分配一个全局唯一的递增编号
- 高性能。全量数据存储在内存中,3台3.4.3的Zookeeper集群,100%读请求场景的压测结果是12-13W的QPS
Zookeeper的基本概念
- 集群角色。存在Leader、Follower、Observer三种角色。Leader服务器提供读和写服务,Follower和Observer提供读服务,但是Observer不参与选举过程,也不参与写操作的“过半写”策略,因此,Observer可以在不影响写性能的情况下提高读性能
- 客户端会话。客户端通过TCP长连接和服务端相连,第一次建立连接就代表客户单会话开始了。客户端能够通过心跳检测与服务器保持有效的会话。Session的SessionTimeout值用来设置会话的超时时间,连接断开后,只要在超时时间之内重新连接上了集群中的任何一台服务器,那么之前创建的会话仍然有效
- 节点。一方面只集群中的每一台机器,称为机器节点;另一方面指数据模型中的数据单元,称为数据节点Znode。Znode又分为持久节点和临时节点,临时节点的生命周期和会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
- 版本。每个Znode,会维护一个叫做Stat的数据结构,记录了Znode的三个版本:version(当期版本)、cversion(当前Znode子节点的版本)、aversion(当前Znode的ACL版本)。
- Watcher。事件监听器,允许用户在一些节点上注册一些watcher。特性事件触发的时候,服务器会将事件通知到感兴趣的客户端上去。
- ACL。权限控制策略(Access Control Lists)。定义了五种权限:Create(创建子节点)、Delete(删除子节点)、read(读取节点数据和子节点列表)、write(更新节点数据)、admin(设置节点ACL的权限)
2、ZAB协议(Zookeeper Atomic Broadcast,原子消息广播协议)
所有事务请求都由Leader服务器来处理分发,如果集群中的其他服务器收到了来自客户端的请求,这些非Leader服务器会首先将这个事务请求转发给Leader服务器,Leader负责将请求封装成Proposal(提议)分发给集群中所有Follower,一旦收到超过半数的正确反馈,Leader就会再次向所有的Follower分发Commit消息,要求他们将前一个Prosocal提交
两种基本模式:崩溃恢复模式和消息广播模式
- 消息广播模式。类似于二阶段提交,去掉了中断逻辑,当Leader服务器收到了超过半数的Follower的ACK响应后,就会广播一个Commit消息给所有的Follower进行事务提交。
- 崩溃恢复。一旦Leader服务器出现崩溃,或者由于网络原因失去了一半Follower服务器的联系,就会进入崩溃恢复模式。
- 崩溃恢复需要确保已经被Leader提交的Proposal也能被所有Follower提交
- 确保丢弃只在Leader服务器上提出的事务。(此处的提出指的是二阶段第一阶段)。重新选举出来的Leader拥有集群中所有服务器最高编号的事务Proposal
- 正常情况的数据同步:Leader服务器为每一个Follower服务器准备一个队列,将那些没有被Follower服务器同步的事务以Proposal消息的形式逐个发送给Follower,等待所有事务都同步到了Follower并成功应用到了Follower的本地数据库中后,Leader服务器就将该Follower服务器加入到真正的可用列表中
- 事务编号ZXID,是一个64位的数字。前32位存储Leader届数,后32位记录本届Leader处理的消息数。
3、深入ZAB协议
运行分析,每一个进程都有可能处于以下三种状态之一
- LOOKING:leader选举阶段
- FOLLOWING:Follower服务器和Leader服务器保持同步状态
- LEADING:Leader服务器作为主进程领导状态
五、使用Zookeeper
1、服务端部署与运行
- 初次使用,需要把/conf目录下的zoo_sample.cfg文件重命名为zoo.cfg。配置如下:

- server.1=IP1:2888:3888,每一行这样的配置代表一个集群中的一个机器,server.1中的1代表ServerID,同时在每台机器上需要在数据目录(dataDir指定的目录)下创建一个myid文件,文件内容就是ServerID,id范围是1~255
- 集群中每个机器的zoo.cfg文件都应该是相同的,最好使用git或者svn把配置管理起来
- 启动服务。/bin/zhServer.sh start
- 停止服务。/bin/zkServer.sh stop
2、客户端脚本
- 启动。/bin/zkCli.sh -server ip:port(不加server参数,默认连接本机)
- 创建节点。create 【-s】【-e】path data acl。acl用来进行权限控制
- 读取节点下子节点。ls path。例如:ls / 查看根节点下的所有子节点
- 读取节点数据。get path
- 更新节点数据。set path data 【version】
- 删除节点。delete path 【version】。无法删除一个包含子节点的节点
3、开源客户端Curator的使用
直接看我的github代码:https://github.com/leon66666/zookeeper-client
六、Zookeeper的典型应用场景
1、典型应用场景及实现
(1)数据发布和订阅
分为推(push)模式和拉(pull)模式,push模式服务端主动把数据更新推送给所有订阅的客户端,而拉模式是由客户端定时轮询拉取的方式来获取最新数据
应用场景:分布式系统统一配置,例如机器列表信息、运行时的开关配置、数据库配置信息等,这些全局配置交给Zookeeper统一管理
这些配置具有以下特点:
- 数据量通常比较小
- 数据内容在运行时动态变化
- 集群中各机器共享,配置一致
(2)负载均衡
DDNS,动态DNS解析。局域网内部一般采用host绑定的方式来进行ip和域名的映射。一旦机器规模变大,这种做法就会相当的不方便。
通过Zookeeper实现,每个应用都可以创建一个属于自己的数据节点作为域名配置的根节点,在这个节点上,每个应用都可以将自己的域名配置上去。通过注册Watcher实现域名变更通知功能。
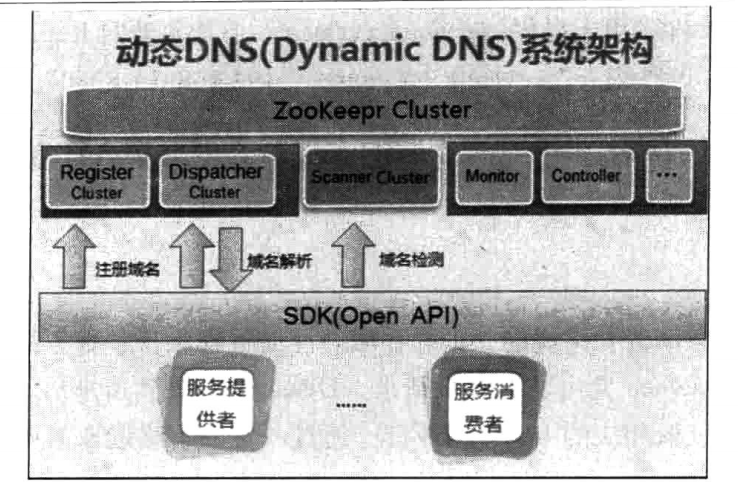
上图为整体的DDNS系统架构。
- Register集群负责域名的动态注册。每个服务者启动的时候,都会把自己的域名信息注册到Register集群中去。
- Dispatcher集群负责域名的解析。服务消费者在使用域名的时候,会向Dispatcher集群发出请求,获取相应的IP:PORT信息。
- Scanner集群负责检测及维护服务状态(探测服务可用性、屏蔽异常服务节点)。(一种是心跳检测,需要客户端和服务端建立起tcp长连接。另一种是服务端主动进行状态汇报,一旦超过5秒没有收到汇报,就认为该IP地址不可用,进行域名清理)
- SDK,提供各个语言的系统接入
- Monitor负责收集集群信息以及对DDNS自身的监控
- Controller是一个后台管理,负责授权管理、流量控制、服务配置和手动屏蔽服务等功能。
(3)命名服务
即分布式环境下,生成全局唯一ID的方法。大家一般会联想到UUID,是通用唯一识别码的简称。主流ORM框架HIbernate就有对UUID的直接支持。
但是,UUID有如下缺点:
- 长度过长,需要更多的存储空间
- 含义不明,根据字符串开发人员从字面上根本看不出他的含义
利用Zookeeper来实现这类全局唯一ID的生成。当客户端创建一个顺序子节点的时候,zookeeper会自动以后缀的形式在其子节点上添加一个序号,利用了zookeeper顺序节点的特性
(4)分布式协调/通知
Zookeeper实现分布式协调通知,通常的做法是不同的客户端都对Zookeeper上同一个数据节点进行Watcher注册。监听节点数据的变化。
(5)通用的分布式系统机器间通信方法
分布西系统机器间通信包括:心跳检测、工作进度报告、系统调度
- 心跳检测。不同机器之间需要检测到彼此是否正常运行。传统方法通过机器之间能否互相ping通来判断;更复杂的通过机器之间建立起Tcp长连接,通过tcp固有的心跳检测机制来实现上层机器的心跳检测;基于Zookeeper的临时节点特性也可以实现心跳检测,不同的机器在指定节点下创建临时节点,不同机器可以通过判断临时节点是否存在来判断客户端机器是否存活。减少了系统耦合
- 工作进度报告。每个客户端创建临时子节点,各个任务机器会实时的将自己的执行进度存储到对应的子节点上,也可以判断子节点是否存在判断机器是否存活
- 系统调度。一个分布式系统由控制台和客户端组成。后台管理人员在控制台做一些操作(实际上就是修改Zookeeper上某些节点的数据),Zookeeper以事件通知的形式发送给对应的订阅客户端
(6)集群管理
集群管理需求点
- 知道集群中工作的机器数量
- 对集群中每台机器的运行状态进行收集
- 对集群中的机器进行上下线操作
传统的基于agent的管理方式,集群中每台机器部署一个agent,负责本机器的监控和向中心系统汇报
- 大规模升级困难
- 统一的agent无法满足多样的需求。无法深入应用内部,对一些业务状态进行监控
- 编程语言多样性。不同机器需要提供不同语言的agent
利用zookeeper监控集群
- 客户端可以对zookeeper节点进行监听,节点变更会受到通知
- 在zookeeper上创建临时节点,一旦会话失效,改临时节点会被自动删除
- 监控系统在/clusterServers节点上注册一个Watcher监听,添加机器会在监听节点下创建临时子节点。
zookeeper监控应用:分布式日志收集系统
- 注册收集器机器。以/logs/controller作为收集器的根节点,每个收集器启动的时候都会在收集器节点下创建自己的节点
- 任务分发。收集系统把日志源机器按照一定策略分配给注册的收集器机器,将机器列表写入到对应的收集器节点上
- 状态汇报。收集器节点下面创建状态子节点,每个注册的收集器机器定时向该节点写入自己的状态信息和日志收集进度信息(可以看做是一种心跳检测),根据更新时间来判断是否存活
- 动态分配。检测到收集器的减少或者增加之后,需要进行重新分配。通常有两种做法:全局分配(影响面大);局部动态分配(低负载优先分配)
- 节点类型。收集器节点,需使用持久节点,需要保存该节点上的日志源机器列表
- 收集器节点监听。放弃监听设置,采用定期轮询,节省网卡流量,但是具有一些延时,考虑到日志收集需求,延时是可以接受的
(7)Master选举
在集群的所有机器中选举出一台机器作为master
- 可以通过数据库的主键唯一特性来实现。但是当选举出的master挂了之后,数据库无法通知我们这个事件
- 利用zookeeper的强一致性,客户端无法创建一个已经存在的节点。其他没有成功创建这个节点的客户端会在这个节点上注册一个子节点变更的watcher,一旦发现当前的master挂了,其余客户端会重新进行选举
(8)分布式锁
最常见的是用数据库实现。例如行锁,表锁,事务处理,乐观锁等等。但是往往分布式系统的性能瓶颈都集中在数据库的操作上。
- 排它锁。选择一个节点作为锁节点,客户端加锁的时候会在锁节点先创建临时子节点,利用zookeeper特性,只有一个客户端能够创建成功,其余客户端注册锁节点的子节点变更的Watcher监听,在持有锁的客户端主动删除临时节点或者由于宕机导致会话超时导致临时节点被移除,都表示锁被释放了。其他监听的客户端会再次发起分布式锁获取
- 共享锁。在锁节点下创建临时顺序节点。读节点为R+序号,写节点为W+序号。创建完节点后,获取所有子节点,对锁节点注册子节点变更的watcher监听,确定自己的序号在所有子节点中的位置。对于读请求,没有比自己序号小的写节点,就表示获得了共享锁,执行读取逻辑。对于写请求,如果自己不是序号最小的子节点,就需要进入等待。接收到watcher通知后,重复获取锁。
- 共享锁羊群效应。大量的watcher通知和子节点列表获取,两个操作重复运行。集群规模比较大的情况下,会对zookeeper服务器造成巨大的性能影响和网络冲击
- 改进后的共享锁。读请求,监听比自己小的写节点。写请求,监听比自己小的最后一个节点。
- 具体选用哪种实现的共享锁,视集群规模而定
(9)分布式队列
- 常规的先入先出队列。通过临时顺序节点实现。【2】通过getChildren()接口获取队列节点下的所有子节点,如果自己不是序号最小的子节点,进入等待,向比自己序号小的最后一个节点注册watcher监听。收集通知后,重复步骤【2】
- Barrier模型。屏障节点的数据内容存储n代表Barrier值。所有的客户端都会在屏障节点下创建临时节点,创建完毕获取屏障节点内容,【2】获取所有子节点,注册对子节点列表变更的watcher监听,统计子节点个数,不足barrier值,进入等待,收到watcher通知,重复步骤【2】
2、zookeeper在大型分布式系统中的应用
(1)hadoop。大型分布式计算框架
- 核心包括HDFS和MapReduce,分别提供了对海量数据的存储和计算能力。0.23.0版本开始,Hadoop又引入了全新一代MapReduce框架YARN。
- YARN是为了提高计算节点Master的扩展性,引入的全新一代分布式调度框架。支持多个计算引擎,包括MapReduce、Spark、Storm等
- YARN中最核心的ResourceManager,作为全局的资源管理器,负责整个系统的资源管理和分配。存在单点问题,使用Active/Standby模式,解决单点问题。只有一台处理Active状态,其他处于Standby状态,当Active节点挂掉之后,其余Standby节点会通过竞争选举产生新的Active节点
- zookeeper实现Active/Standby模式。类似于master选举,启动的时候都会去创建一个临时子节点,只要一个能够创建成功,成功的机器作为Active,其他的作为Standby,并注册子节点的watcher监听。一旦Active挂点,会话断开链接,临时节点自动删除,触发watcher,再次进行master选举出新的Active。
- HDFS的NameNode和ResourceManager模块都是使用该组件实现的HA
- 脑裂问题。选举出新的Active机器后,以前的Active恢复正常了,出现了脑裂现象。使用ACL权限控制来进行隔离,创建节点的同时增加修改这个节点的权限。当之前的Active机器恢复正常,尝试去修改节点数据的时候,发现已经没有了权限。
(2)HBase。是一个面向海量数据的高可靠性、高性能、面向列、可伸缩的分布式存储系统
- 与大多数分布式NoSQL数据库不同的是,HBase针对数据写入具有强一致性、甚至包括索引列也都实现了强一致性
- HBase采用zookeeper服务来完成对整个系统的分布式协调工作
- 系统冗错。每个RegionServer服务器都会信息节点,Hmaster对这个节点注册监听,当RegionServer挂掉之后,会话断开,节点被删除,Hmaster接收到删除通知,会将挂掉的RegionServer所处理的数据分片(Region)重新路由到其他的节点上。随着系统容量的不断增加,Hmaster管理的负担会越来越重,所以使用zookeeper来完成这部分工作,减轻Hmaster负担。
- RootRegion管理。数据存储的位置信息记录在元数据分片(RootRegion)上。客户端每次发起请求,需要知道数据的位置,就会去查询RootRegion。而RootRegion的位置存储在zookeeper上,当RootRegion发生变化或者发生故障时,就能够通过zookeeper感知到这一变化做出一系列响应的容灾措施。
- Region状态管理。Region是HBase中数据的物理切片,每个Region中记录了全局数据的一小部分,不同的Region之间数据不相互不重复的。对于一个分布式系统来说,Region会经常变更,变更原因来自于系统故障、负载均衡、配置修改、Region分裂和合并等。一旦Region发生移动,需要做上线和下线处理。状态管理需要Zookeeper来实现。对于Hbase集群来说,Region的数量会达到10万级别。
- 分布式SplitLog任务管理。
(3)Kafka。开源的分布式消息系统,是一个吞吐量极高的分布式消息系统。主要用于实现低延迟的发送和收集大量的事件和日志数据。
- 每个broker服务器启动的时候,都会向Zookeeper注册。zookeeper作为注册中心
- 使用zookeeper作为他的分布式协调框架,实现了生产者和消费者的负载均衡
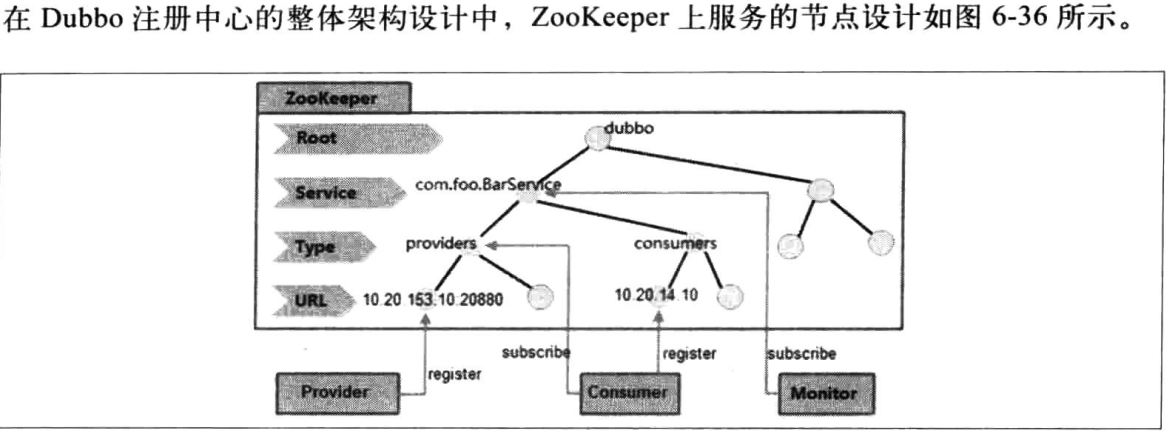
(4)dubbo

七、Zookeeper技术内幕
1、系统模型
- 数据模型。由数据节点Znode组成树型结构。每一个事务操作(节点的创建和删除、数据节点内容变更、客户端会话的创建和失效)zookeeper会分配一个全局唯一的事务ID,ZXID,64位数字。前32位表示leader选举的届数,后32位表示事务序号
- 节点特性。持久节点,持久顺序节点,临时节点,临时顺序节点。节点除了存储数据,子节点之外,还存储了节点本身的一些状态信息,用Stat类来表示。
- 版本。版本信息也是存储在stat中的。version(当前节点数据内容的版本号)、cversion(当前节点子节点的版本号)、aversion(当前节点ACL变更版本号)。通过版本号来实现乐观锁,会从客户端请求中获取到版本号,和节点状态数据中存储的版本号对比,如果不匹配,就抛出异常。
- Watcher,数据变更的通知。客户端注册watcher的时候,会将watcher对象存储在客户端的watchManager中,当服务端触发watcher事件后,会向客户端发送通知,客户端线程从watchManager中取出对应的watcher对象来执行回调逻辑。watcher机制具有如下特点:一次性(无论是客户端还是服务端,一旦一个watcher被触发,zookeeper就会从相应的存储中移除,所以需要反复注册);客户端串行执行(客户端watcher的回调处理,是一个串行同步的过程,保证了顺序性,也需要注意watcher回调方法的处理,避免长时间执行而影响到其他的watcher回调);轻量(只会告诉客户端发生了事件,不会说明事件的具体内容,另外,客户端注册的时候,也不会把客户端真实的watcher对象传递给服务器。如此轻量的设计,在网络开销和服务器内存开销上都是非常廉价的)
- ACL,权限控制。分为权限模式(Scheme)、授权对象(ID)、权限(Permission),使用scheme:id:permission来识别一个有效的acl信息
- Scheme说明。IP模式:“IP:192.168.1.24”,“IP:192.168.1.1/24”;Digest模式:username:password,会进行两次编码处理,分别是SHA-1算法和BASE64编码
- 授权对象(ID)。IP模式下是一个ip或一个ip段;Digest模式下,是username:password;World模型下,是“anyone”
- 权限(Permission)。create(C)创建子节点;delete(D)删除子节点;read(R)读取节点数据和子节点列表;write(W)更新节点数据;admin(A)节点管理权限,acl操作
2、序列化和协议
- jute介绍。是zookeeper的序列化组件,也是早期Hadoop中的默认序列化组件。后来由于Apache Avro具有出众的跨语言特性、丰富的数据结构和对MapReduce的天生支持,并且能非常方便的用于RPC调用,所以后来的Hadoop就抛弃了Jute。但是zookeeper由于新老版本兼容、性能瓶颈并不在jute上、其他需求优先级更高等原因,一直使用着jute这个古老的序列化组件
- 通讯协议。基于tcp/ip协议,zookeeper实现了自己的通讯协议来完成客户端与服务端、服务端与服务端之间的网络通信。请求包括请求头和请求体,响应包括响应头和响应体
3、客户端
(1)一次会话的创建过程
- 初始化zookeeper对象
- 设置会话默认watcher
- 构造zookeeper服务器地址列表管理器:HostProvider
- 创建并初始化客户端网络连接器:ClientCncx。内部有两个线程,SendThread(I/O线程,负责负责zookeeper客户端和服务端之间的网络I/O通信),ExentThread(事件线程,负责对服务器事件进行处理)。两个核心队列,outgoingQueue(客户端请求发送队列)、pendingQueue(服务端响应的等待队列),还会创建底层I/O处理器ClientCxcnSocket
- 初始化和启动SendThread,ExentThread
- 获取一个服务器地址,通过HostProvider获取
- 创建tcp长连接。ClientCxcnSocket负责创建一个tcp长连接
- SendThread负责构造一个ConnectRequest请求,放入到outgoingQueue请求队列中
- ClientCxcnSocket负责从outgoingQueue队列中取出一个待发送的对象,将其序列化成ByteBuffer后,发送给服务端
- ClientCxcnSocket接受服务器的响应,处理response,进行反序列化,
- 生成连接成功事件,交给ExentThread进行处理,从ClientWatcherManager查询watcher,将其放入到EventThread的waitingEvents队列中。
- 处理事件watcher,EventThread不断的从waitingEvents队列中取出待处理的watcher,调用watcher的process方法,执行回调逻辑。
(2)服务器地址列表
- 客户端隔离命名空间
- HostProvider,会把所有的地址列表打散成一个环形队列,不断的从这个队列中获取地址
- 自定义HostProvider,实现动态变更的地址列表管理器和同机房优先策略
4、会话
(1)会话状态。整个会话的运行期间,会在不同的状态之间进行切换。这些状态包括connecting,connected,reconnecting,reconnected,close。
- 客户端由于网路原因断开连接,会重连服务器。这个过程中状态会在connecting和connected之间切换
- 会话超时、权限检查失败、客户端主动退出程序。这些情况下,客户端状态直接变为close
(2)session是zookeeper的会话实体。包含以下属性
- 会话ID。全局唯一的sessionid。sessionid计算算法:((System.currentTimeMillis()<<24)>>>8)|(id<<56)。当前系统时间左移24位再无符号右移8位,保证前8位都是0,用于来后边的服务器唯一表示id<<56做位或运算。前8位表示服务器机器id,后56位表示时间毫秒。sessionid由服务器进行创建,基于顺序执行的特定,所以所有客户端的请求的时间毫秒都是不一样的。这样就保证了sessionid的全局唯一性。
- timeout。会话超时时间
- ticktime。下次会话超时时间点。用于分桶策略管理
- isclosing。标记一个会话是否已经关闭
(3)会话管理。由SessionTracker负责管理
- 分桶策略。按照ExpirationTime对会话进行分类,类似的会话放在同一区块中进行管理统一处理。ExpirationTime=((currentTime+SessionTimeout)/ExpirationInterval+1)*ExpirationInterval。ExpirationInterval是leader服务器进行定期检查会话超时的时间间隔,默认值是tickTime的值。ExpirationTime总是ExpirationInterval的整数倍。
- 会话激活。当客户端向服务端发起请求的时候,会进行会话激活。重新计算会话的ExpirationTime。根据新旧两个下次超时时间点,进行会话迁移,完成会话激活。有两种情况会发生会话激活:1 是只要客户端发送了请求,就会触发一次会话激活;2 是如果客户端在sessionTimeout/3时间内未和服务器进行过任何通信,就会主动向服务器发送ping请求(心跳检测),触发服务端的会话激活
- 会话超时检查,按照ExpirationTime时间线,对会话桶进行检查,留下的所有会话都是尚未被激活的,对他们进行批量清理
- 会话清理。标记会话状态为关闭,向集群中所有机器发起会话关闭请求,收集需要删除的临时节点,删除临时节点,移除会话,关闭连接
(4)会话重连
- 连接断开。connection_loss。客户端会自动从服务器地址列表中重新逐个选取新的地址尝试进行连接,直到最终成功连接上服务器。断开连接和重连成功,客户端都会受到服务端的事件通知
- 会话失效。session_expired。断开连接之后,重连期间耗时过长,超过了会话超时时间,服务器认为这个会话已经结束,进行会话清理。客户端不知道已经失效,如果之后客户端重新连接上了服务器,会受到会话已经失效的通知(session_expired)。
- 会话转移。session_moved。断开重新后,成功连接上了新的服务器,会话转移到了新的服务器上。
5、集群版服务器启动流程
(1)预启动
- 统一由QuorumPeerMain作为启动类
- 解析配置文件zoo.cfg
- 判断当前是集群模式还是单机模式启动(集群模式中,在zoo.cfg中配置了多个服务器地址)
(2)初始化
(3)leader选举
(4)leader和follower启动期交互过程
- 创建leader服务器,创建follower服务器
- follower服务器和leader建立连接,注册follower
- leader服务器和follower服务器同步数据
- 过半follower服务器完成数据同步。
- 启动leader服务器和follower服务器
6、leader选举
(1)选举概述。服务器启动时期的Leader选举
- 每个server发出一个投票。初始化阶段都会投给自己。投票以(myid,ZXID)表示。
- 接收来自各个服务器的投票。判断投票的有效性、检查是否是本轮投票、是否来自looking状态的服务器
- 处理投票。把自己的投票和其他服务器的投票进行PK。PK规则:ZXID比较大的优先成为leader;ZXID相同,myid比较大的优先。把pk结果重新发给其他服务器
- 统计投票。每次投票后,都会统计是否有超过半数机器接收到相同的投票,大于等于n/2+1。
- 改变服务器状态。leader变为leading,follower变为following
(2)选举概述。服务器运行期间的leader选举
- 变更状态,当leader挂了之后,余下的非observer服务器都会讲自己的状态变为looking,开始进入选举过程。
- 选举过程同上。
(3)leader选举的算法分析。3.4.0版本开始,只保留了tcp版本的FastLeaderElection。废弃了LeaderElection和udp版本的FastLeaderElection
7、服务端请求处理
(1)会话创建请求
- 请求接收。I/O层接收请求,根据NIOServerCnxn是否初始化来判断是否是会话创建请求,反序列化请求,检查客户端Zxid(客户端Zxid需小于服务端Zxid),根据服务端的配置协商sessionTimeout
- 会话创建。为客户端生成sessionID,向sessionTracker中注册会话,会话激活,生成会话密码(作为会话在不同服务器中间转移的凭证)
- 预处理。采用责任链模式,创建请求事务头、请求事务体、注册与激活会话(为了处理非Leader服务器转发过来的会话创建请求)
- 事务处理。Sync流程:Leader服务器和follower服务器记录事务日志的过程
- 事务处理。Proposal流程:投票和统计投票过程。类似于二阶段提交协议的preCommit。生成提议Proposal,广播提议,收集投票
- 事务处理。Commit流程:超过半数提议通过,广播commit消息
- 事务应用。将事务变更应用到内存数据库中,对于会话创建需要特殊处理,会话的管理由sessionTracker负责,只需要再次向sessionTracker注册即可
- 会话响应。统计服务端处理所花费的时间,创建响应,序列化响应,I/O层发送响应给客户端
(2)setDate请求
- 预处理。接收请求,反序列化,会话检查、ACL权限检查、数据版本检查、生成事务
- 事务处理。同上
- 事务应用。将事务变更应用到内存数据库中
- 请求响应。同上
(3)事务请求转发。所有非Leader服务器收到了客户端发来的事务请求,都会将请求转发到Leader服务器来处理
(4)getData等非事务请求的流程
- 预处理。接收请求,判断是否为客户端会话创建请求,交给PrepRequestProcessor处理器进行处理,会话检查
- 非事务处理。反序列化请求,获取节点数据,ACL权限检查,注册Watcher
- 请求响应。同上
8、数据与存储
(1)内存数据
- DataTree。是内存数据存储的核心,是一个树的结构。底层是ConcurrentHashMap<String,DataNode> nodes。节点的路径(path)作为key,节点的数据内容DataNode作为value
- DataNode。是数据存储的最小单元。包括节点的数据内容data[]、acl列表、节点状态(stat)、还记录了父节点的引用和子节点列表
- ZKDatabase。是zookeeper的内存数据库,负责管理zookeeper的所有会话、DataTree存储、事务日志。
(2)事务日志
- 文件存储。配置中的dataDir目录,是用来存储日志文件的。每个日志文件的大小都是64M,以事务ID(ZXID)作为后缀,高32位代表Leader周期,低32位则是真正的操作序列号
- 日志内容存储格式。事务日志是二进制表示,无法直接看出信息。需使用事务日志格式化工具。org.apache.zookeeper.Server.LogFormatter。使用方法如下:Java LogFormatter 事务日志文件。需要注意的是,这是一个记录事务操作的日志文件,因此里面没有任务读操作的日志记录
- 日志写入。1.当前日志文件剩余空间不足4k,会进行预分配。文件的不断追加写入会触发底层磁盘I/O为文件开辟新的磁盘块(磁盘seek),为了避免磁盘seek的频率,提高磁盘I/O效率;2.事务序列化;3.写入事务日志文件流;4.事务日志刷入磁盘
- 日志截断。非leader机器上记录的zxid比leader服务器还要大,Leader会发送TRUNC命令,进行日志截断,删除所有包含或大于peerLastZxid的事务日志文件
(3)snapshot,数据快照。用来记录Zookeeper服务器某一个时刻的全量内存数据内容,并将其写入到指定的磁盘文件中
- 文件存储。 通过dataDir来配置,快照文件也是用事务ID(ZXID)的十六进制作为文件后缀,该后缀标记了本次数据快照开始时刻的服务器最新ZXID。和事务日志不同,快照日志没有采用预分配机制。
- 存储格式,和事务日志存储格式相同,需要使用格式化工具查看内容。会将数据节点逐个依次输出,这里输出的仅仅是数据节点的元数据(stat),并没有输出每个节点的数据内容
- 数据快照过程:1 判断是否需要进行数据快照(采用过半随机策略,避免所有机器同时进行数据快照,影响性能。logcount>(snapcount/2+randroll) snapcount是配置文件配置的数值,randroll是一个随机值);2 切换事务日志文件,计数清零;3 创建数据快照异步线程; 4 获取全量信息和会话信息 ;5 生成快照文件名 6 数据序列化,写入磁盘
(4)初始化。服务器启动期间,会进行数据初始化过程,将磁盘上的数据加载到内存中
- 处理快照文件,获取最新的100个快照文件
- 对快照文件进行解析和校验。如果最新的快照文件未通过解析和校验,会逐个往下进行解析校验。
- 获取最新的ZXID
- 处理事务日志,获取所有大于上一步ZXID的事务日志。把事务日志应用到内存数据库中
- 再次获取最新的ZXID
- 校验epoch(leader选举届数)
(5)数据同步
peerLastZxID:该learner服务器最后处理的Zxid
minComminttedLog :Leader服务器提议缓存队列ComminttedLog中最小的Zxid
maxComminttedLog:Leader服务器提议缓存队列ComminttedLog中最大的Zxid
- 直接差异化同步(DIFF同步)。peerLastZxID介于minComminttedLog和maxComminttedLog中间
- 先回滚在差异化同步(TRUNC+DIFF同步)。peerLastZxID介于minComminttedLog和maxComminttedLog中间,但是leader发现了某个learner包含了一条自己没有的事务记录。
- 仅回滚同步(RTUNC)。peerLastZxID大于maxComminttedLog
- 全量同步(SNAP)。peerLastZxID小于minComminttedLog;Leader没有提议缓存队列,peerLastZxID不等于Leader服务器最大的Zxid。在这两种情况下,Leader服务器都无法直接使用提议缓存队列和learner进行同步,因此只能使用全量同步(SNAP)
八、Zookeeper运维
1、配置详解
(1)基本配置。必需配置
- clientPort:对外的服务端口,一般配置为2181、集群中的所有端口不需要保持一致
- dataDir:服务器存储快照文件的目录。dataLogDir,事务日志的存储目录
- tickTime:默认值3000毫秒,用于配置Zookeeper中最小时间单位的长度。会话的最小超时时间默认是2*tickTime
(2)高级配置
- dataLogDir:用于存储事务日志文件。应该将事务日志单独配置在一块磁盘上,事务日志写入的性能直接影响到zookeeper的性能和吞吐量。数据快照操作会极大的影响事务日志的写性能,尽量分开磁盘
- initLimit:默认值为10,即tickTime的十倍。Leader等待follower完成数据同步的时间。随着集群的数据量增大,同步时间变长,可以适当调大这个参数
- syncLimit:默认值5,leader服务器和follower进行心跳检测的最大延时时间。如果网络环境较差,可以适当调大此参数
- snapCount:默认值 100000。两次快照之间间隔的事务操作次数
- preAllocSize:默认值65536,即64M。事务日志预分配的空间大小。随着snapCount的变化而变化,同增同减
- minSessionTimeout。maxSessionTimeout:最大和最小超时时间。分别是tickTime的2倍和20倍。用于对客户端回话超时时间进行限制
- maxClientCnxns:默认值60。如果设置为0,则表示没有限制。单个客户端和服务端之间的最大并发连接数。
- jute.maxbuffer:单个数据节点上存储的最大数据量大小。zookeeper上不需要存储太多的数据,往往还需要将该参数设置的更小
- clientPortAddress:针对多网卡的机器,zookeeper允许为每个ip地址指定不同的监听端口
- server.id:host:port:port:配置组成集群的机器列表。第一个port用于leader和follower进行通信和数据同步的端口,第二个port用于leader选举过程中的投票通信
- autopurge.snapRetainCount:自动清理快照日志和事务日志时,需要保留的数量。最小值为3,默认值也是3
- autopurge.purgeInterval:自动清理的频率。默认值是0,单位是小时。配置为0或者负数,表示不开启自动清理功能。默认不开启此功能
- fsync.warningthresholdms:配置事务日志操作消耗时间的报警阈值,超过阈值,将在日志中打印出报警日志。
- forceSync:配置事务日志每次写入操作强制写入磁盘。默认值是yes。如果设置成no,在一定程度上能提高zookeeper的写性能,但存在断点的风险。
- globalOutStandingLimit:默认值1000,服务器最大请求堆积数量,防止服务器资源被大量的客户端请求耗尽。
- leaderServers:是否允许leader服务器向客户端提供服务。默认值yes。可以设置成no,让leader服务器专注的进行分布式协调
- SkipAcl:默认值 no。配置是否跳过acl权限检查。
- cnxTimeout:默认值5000毫秒。配置Leader选举过程中,个服务器间tcp连接创建的超时时间
- eletionAlg:leader选举策略。3.4.0版本之后,只留下了fastLeaderElection算法。
2、四字命令
- conf。输出服务器的配置信息
- cons。输出这台服务器上所有客户端连接的详细信息
- crst。重置所有客户端的连接统计信息
- dump。输出当前集群中的所有会话信息。只有leader服务器会进行会话超时检测,leader服务器执行此命令,还会打印出会话的超时时间
- envi。输出当前服务器运行时的环境信息
- ruok。输出当前服务器是否正在运行。
- stat。输出当前服务器运行时的状态信息,包括连接情况
- srvr。和stat命令功能相同,区别是srvr命令不会打印连接情况
- srst。重置所有服务器的统计信息
- wchs。输出当前服务器上的watcher概要信息
- wchc。输出当前服务器上管理的watcher详细信息。以会话单元进行归组
- wchp。输出当前服务器上管理的watcher详细信息。以节点路径为单位进行归组
- mntr。输出比stat更详细的服务器统计信息。
3、JMX。是一个为应用程序、设备、系统等植入管理功能的框架
(1)开启远程JMX

通过上述配置,就可以允许远程机器和zookeeper服务器进行jmx连接了
(2)通过JConsole连接zookeeper
JConsole是一个Java内置的基于JMX的图形化管理工具,是最常用的JXM连接器。
4、监控
TaoKeeper监控系统,可以在实时监控和数据统计两方面保障Zookeeper的稳定性。github地址:https://github.com/alibaba/taokeeper
5、构建一个高可用的集群
(1)集群组成。最好的数量是奇数,不过偶数可以的
(2)容灾。三机房部署,2机房部署
(3)扩容与缩容。Zookeeper集群扩容需要整个集群机器的重启。整体重启和逐台重启
九、相关资料
《从Paxos到ZooKeeper 分布式一致性原理与实践》读书笔记的更多相关文章
- csapp读书笔记-并发编程
这是基础,理解不能有偏差 如果线程/进程的逻辑控制流在时间上重叠,那么就是并发的.我们可以将并发看成是一种os内核用来运行多个应用程序的实例,但是并发不仅在内核,在应用程序中的角色也很重要. 在应用级 ...
- CSAPP 读书笔记 - 2.31练习题
根据等式(2-14) 假如w = 4 数值范围在-8 ~ 7之间 2^w = 16 x = 5, y = 4的情况下面 x + y = 9 >=2 ^(w-1) 属于第一种情况 sum = x ...
- CSAPP读书笔记--第八章 异常控制流
第八章 异常控制流 2017-11-14 概述 控制转移序列叫做控制流.目前为止,我们学过两种改变控制流的方式: 1)跳转和分支: 2)调用和返回. 但是上面的方法只能控制程序本身,发生以下系统状态的 ...
- CSAPP 并发编程读书笔记
CSAPP 并发编程笔记 并发和并行 并发:Concurrency,只要时间上重叠就算并发,可以是单处理器交替处理 并行:Parallel,属于并发的一种特殊情况(真子集),多核/多 CPU 同时处理 ...
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 读书笔记--SQL必知必会18--视图
读书笔记--SQL必知必会18--视图 18.1 视图 视图是虚拟的表,只包含使用时动态检索数据的查询. 也就是说作为视图,它不包含任何列和数据,包含的是一个查询. 18.1.1 为什么使用视图 重用 ...
- 《C#本质论》读书笔记(18)多线程处理
.NET Framework 4.0 看(本质论第3版) .NET Framework 4.5 看(本质论第4版) .NET 4.0为多线程引入了两组新API:TPL(Task Parallel Li ...
- C#温故知新:《C#图解教程》读书笔记系列
一.此书到底何方神圣? 本书是广受赞誉C#图解教程的最新版本.作者在本书中创造了一种全新的可视化叙述方式,以图文并茂的形式.朴实简洁的文字,并辅之以大量表格和代码示例,全面.直观地阐述了C#语言的各种 ...
- C#刨根究底:《你必须知道的.NET》读书笔记系列
一.此书到底何方神圣? <你必须知道的.NET>来自于微软MVP—王涛(网名:AnyTao,博客园大牛之一,其博客地址为:http://anytao.cnblogs.com/)的最新技术心 ...
- Web高级征程:《大型网站技术架构》读书笔记系列
一.此书到底何方神圣? <大型网站技术架构:核心原理与案例分析>通过梳理大型网站技术发展历程,剖析大型网站技术架构模式,深入讲述大型互联网架构设计的核心原理,并通过一组典型网站技术架构设计 ...
随机推荐
- Delphi XE2 新增 System.Zip 单元, 可用一句话压缩整个文件夹了
内主要就是 TZipFile 类, 最方便使用的是它的类方法: TZipFile.ExtractZipFile() //解压 Zip 文件到指定文件夹 TZipFile.IsValid() //判断指 ...
- git常用的命令行
git管理相关基础命令行,因为现在很多公司都用git管理代码,所以被问及的概率很大,可以用pycharm的git系统,也可以用git代码管理 $git init #初始化仓库$git branch 分 ...
- 《Java性能调优》学习笔记(1)
性能的参考指标 执行时间 -- 从代码开始运行到结束的时间 CPU时间 -- 函数或者线程占用CPU的时间 内存分配 -- 程序在运行时占用内存的情况 磁盘吞吐量 -- 描述IO的使用情况 网络吞吐量 ...
- iOS 数组问题
在iOS开发过程中,使用json抓取网络数据进行解析时,用tableview承载,发现数据已经抓取到,但是在cell里面使用却会导致程序崩溃 原因可能是初始化方法问题,将 _infoArray=[[N ...
- 轻松读懂IL
轻松读懂IL先说说学IL有什么用,有人可能觉得这玩意平常写代码又用不上,学了有个卵用.到底有没有卵用呢,暂且也不说什么学了可以看看一些语法糖的实现,或对.net理解更深一点这些虚头巴脑的东西.最重要的 ...
- Java学习图
- .net的服务转移
问题: 服务器换新,但是本来服务器部署了一些window服务,需要迁移过来 解决过程: 百度了估计几百页了,之前因为老机器挂了,写这个代码布服务的人也早就不在了,所以自己闷头苦找,一个java初级程序 ...
- 利用max-height适应多尺寸屏幕的下拉动画
移动设备的特点之一便是屏幕尺寸多种多样,所以我们在制作针对移动设备的动画时必须不同尺寸屏幕的兼容性.比如我们要制作以下动画:红框2为详细内容,默认收起:红框1处为事件响应热区,点击后展开或收起红框2的 ...
- Linux编程 18 安装软件程序(yum工具对软件包安装,删除,更新介绍)
一. 概述 本篇介绍在linux上见到的各种包管理系统(package management system,PMS)用来进行软件安装,管理,删除的命令行工具.PMS是利用一个数据库来记录各种相关内 ...
- 用dos命令导出一个文件夹里面所有文件的名字(装逼利器)
首先,当然是在相关的文件夹打开dos命令窗口. 然后,输入如下命令:dir/b >a.txt 如果你非常了解dos命令,那么你一定会觉得这个东西简单到爆,而且我的理解和猜想都有些无知. 但如果你 ...