python - 中文编码/ASCII
Python 中文编码
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5.
GB2312(1980年)一共收录了7445个字符,包括6763个汉子和682个其他符号。汉字区的内码范围高字节从B0-E7,低字节A1-FE,占用的码位是72*94=6768.其中5个空位是D7FA-D7EF。
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字去和图形符号区。汉字区包括21003个字符,2000年的GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文扥更主要的少数名族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不做要求。所以手机、MP3一般支持GB2312.
从ASCII、GB2312、GBK到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。这些编码中,英文和中文可以统一地处理,区分中文编码的方法是高字节的最高位不为0.按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集(DBCS)
有的中文windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB118030,不过GB18030相对GBK增加的字符,普通人很难用到,通常我们还是用GBK只带中文windows内码。
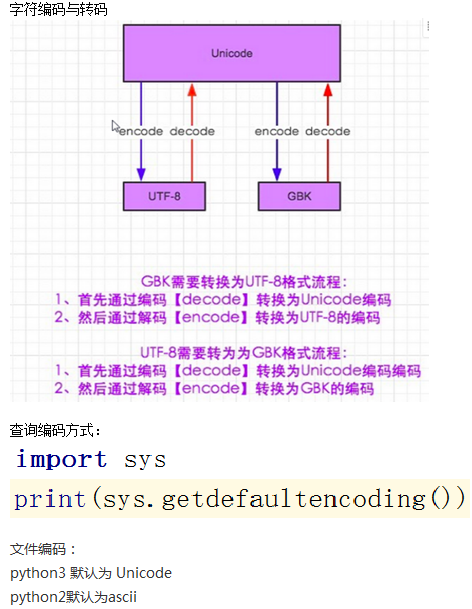
关于ASCII码/unicode/utf-8
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代码所有字符和符号的编码即:Unicode
unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码、unicode是为了解决传统的字符编码方法的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由16位表示(2个字节)即2**16 = 65536
UTF-8 是对unicode编码的压缩和优化,他不在使用最少使用2个字节,而是将所有的字符和符号进行分类ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
所以,python解释器在加载.py文件中的代码时,会对内容进行编码(默认ascill)
时间节点:
ASCII 255 1bytes
————1980 GB2312 7XXX
------------1995 GBK1.0 2w+
-------------2000 GB18030 27xxxx
-------------UNICODE 2bytes
-------------utf-8 en:1byte, zh :3btes
python - 中文编码/ASCII的更多相关文章
- [Python] 中文编码问题:raw_input输入、文件读取、变量比较等str、unicode、utf-8转换问题
最近研究搜索引擎.知识图谱和Python爬虫比较多,中文乱码问题再次浮现于眼前.虽然市面上讲述中文编码问题的文章数不胜数,同时以前我也讲述过PHP处理数据库服务器中文乱码问题,但是此处还是准备简单做下 ...
- python中文编码问题深入分析(一):字符编码基础
背景:笔者作为一名刚接触python语言的新手,在实际的项目中,遇到过一些中文编码问题,初次遇到这些问题的时候,刚开始显得有些手足无措,也不知从何查起.常言道:有问题,找度娘!当我打开www.baid ...
- 转:解决Python中文编码问题
Python 文本挖掘:解决Python中文编码问题 转于:http://rzcoding.blog.163.com/blog/static/2222810172013101785738166/ ...
- 使用Python生成ASCII字符画
使用Python生成ASCII字符画 在很多的网站主页中或者程序的注释中会有一些好看的字符注释画.显得很牛逼的样子 例如: 知乎 _____ _____ _____ _____ /\ \ /\ \ / ...
- python中文编码 - python基础入门(5)
python到目前为止,一共有两个版本,分别是2.x和3.x版本,根据官方正式通知2020年停止对python更新和维护,距离今天还有110天左右,所以正在学习python的小伙伴应该暗中庆幸一波. ...
- ascii codec can't decode byte 0xe8 in position 0:ordinal not in range(128)---python中文编码问题
解决方案一:将如下部分加在报错的py文件里 import sys reload(sys) sys.setdefaultencoding('utf-8')
- python中文编码
前面章节中我们已经学会了如何用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题 ...
- 【转】【Python】Python 中文编码报错
用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题. Python 文件中如果 ...
- 【原创】python中文编码问题深入分析(三):python2.7文件读写中文编码问题
上一篇文章介绍和分析了python2.7中使用print遇到的中文编码问题的原因和解决方案,本篇主要介绍一下python2.7中执行文件读写可能遇到的编码问题. 1.文件读取 假如我们读取一个文件,文 ...
随机推荐
- Codeforces Round #524 (Div. 2) C. Masha and two friends(思维+计算几何?)
传送门 https://www.cnblogs.com/violet-acmer/p/10146350.html 题意: 有一块 n*m 的棋盘,初始,黑白块相间排列,且左下角为白块. 给出两个区间[ ...
- Linux(centos7)如何安装Zend Optimizer Zend Guard Loader
下载地址:http://www.zend.com/en/products/loader/downloads#Linux 1.解压 wget http://downloads.zend.com/guar ...
- jquery的checked以及disabled
下面只提到checked,其实disabled在jquery里的用法和checked是一模一样的 下边两种写法没有任何区别 只是少了些代码而已... ------------------------- ...
- Luogu P3355 骑士共存问题
题目链接 \(Click\) \(Here\) 二分图最大独立集.对任意两个可以相互攻击的点,我们可以选其中一个.对于不会互相攻击的,可以全部选中.所以我们只需要求出最大匹配,根据定理,二分图最大独立 ...
- Luogu P2463 [SDOI2008]Sandy的卡片
题目链接 \(Click\) \(Here\) 真的好麻烦啊..事实证明,理解是理解,一定要认认真真把板子打牢,不然调锅的时候真的会很痛苦..(最好是八分钟能无脑把\(SA\)码对的程度\(QAQ\) ...
- Linux如何查看机器的配置信息
Linux如何查看机器的配置信息 1.查看内存信息 cat /proc/meminfo [root@web ~]# cat /proc/meminfo MemTotal: kB MemFree: kB ...
- eclipse新建maven项目默认jre为1.5的问题
在maven的settings.xml中添加如下内容解决 <profiles> <profile> <id>jdk-1.8</id> <activ ...
- centos之Too many open files问题-修改linux最大文件句柄数
linux服务器大并发调优时,往往需要预先调优linux参数,其中修改linux最大文件句柄数是最常修改的参数之一. 在linux中执行ulimit -a 即可查询linux相关的参数,如下所示: [ ...
- 清理sql2012数据库日志
--1.先把数据库设置为简单模式(右击数据库名->点'属性'->点'选项'->恢复模式改成'简单'->点'确定'按钮,--2.再执行下面的语句(或者右击数据库点'任务'-> ...
- 如何比较一个类型【模板使用】【sizeof用法】
#include <iostream> using namespace std; void testEmptyClass(); struct Empty { }; struct Dummy ...