Python HTML操作(HTMLParser)
HTML操作是编程中很重要的一块,下面用Python3.x中的html.parser中的HTMLParser类来进行HTML的解析。
HTMLParser类定义及常用方法
标准库中的定义
class html.parser.HTMLParser(*, convert_charrefs=True)
- HTMLParser主要是用来解析HTML文件(包括HTML中无效的标记)
- 参数convert_charrefs表示是否将所有的字符引用自动转化为Unicode形式,Python3.5以后默认是True
- HTMLParser可以接收相应的HTML内容,并进行解析,遇到HTML的标签会自动调用相应的handler(处理方法)来处理,用户需要自己创建相应的子类来继承HTMLParser,并且复写相应的handler方法
- HTMLParser不会检查开始标签和结束标签是否是一对
常用方法
- HTMLParser.feed(data):接收一个字符串类型的HTML内容,并进行解析
HTMLParser.close():当遇到文件结束标签后进行的处理方法。如果子类要复写该方法,需要首先调用HTMLParser累的close()HTMLParser.reset():重置HTMLParser实例,该方法会丢掉未处理的html内容HTMLParser.getpos():返回当前行和相应的偏移量HTMLParser.handle_starttag(tag, attrs):对开始标签的处理方法。例如<div id="main">,参数tag指的是div,attrs指的是一个(name,Value)的列表HTMLParser.handle_endtag(tag):对结束标签的处理方法。例如</div>,参数tag指的是divHTMLParser.handle_data(data):对标签之间的数据的处理方法。<tag>test</tag>,data指的是“test”HTMLParser.handle_comment(data):对HTML中注释的处理方法。
实例应用
- 待处理文件: http://files.cnblogs.com/files/AlwinXu/Scan_TFS.zip
- 代码
__author__ = 'xua' import json #For python 3.x
from html.parser import HTMLParser #定义HTMLParser的子类,用以复写HTMLParser中的方法
class MyHTMLParser(HTMLParser): #构造方法,定义data数组用来存储html中的数据
def __init__(self):
HTMLParser.__init__(self)
self.data = [] #覆盖starttag方法,可以进行一些打印操作
def handle_starttag(self, tag, attrs):
pass
#print("Start Tag: ",tag)
#for attr in attrs:
# print(attr) #覆盖endtag方法
def handle_endtag(self, tag):
pass #覆盖handle_data方法,用来处理获取的html数据,这里保存在data数组
def handle_data(self, data):
if data.count('\n') == 0:
self.data.append(data) #读取本地html文件.(当然也可以用urllib.request中的urlopen来打开网页数据并读取,这里不做介绍)
htmlFile = open(r"/Users/xualvin/Downloads/TFS.htm",'r')
content = htmlFile.read() #创建子类实例
parser = MyHTMLParser() #将html数据传给解析器进行解析
parser.feed(content) #对解析后的数据进行相应操作并打印
for item in parser.data:
if item.startswith("{\"columns\""):
payloadDict = json.loads(item)
list = payloadDict["payload"]["rows"]
for backlog in list:
if backlog[1] == "Product Backlog Item" or backlog[1] == "Bug":
print(backlog[2]," Point: ",backlog[3])
- 输出结果
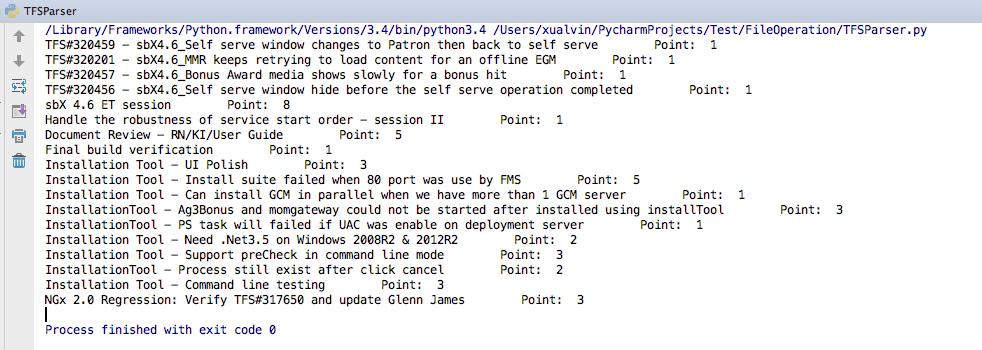
Python HTML操作(HTMLParser)的更多相关文章
- Python中操作mysql的pymysql模块详解
Python中操作mysql的pymysql模块详解 前言 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持 ...
- Python 字符串操作
Python 字符串操作(string替换.删除.截取.复制.连接.比较.查找.包含.大小写转换.分割等) 去空格及特殊符号 s.strip() .lstrip() .rstrip(',') 复制字符 ...
- Python目录操作
Python目录操作 os和os.path模块os.listdir(dirname):列出dirname下的目录和文件os.getcwd():获得当前工作目录os.curdir:返回但前目录('.') ...
- Python基础篇【第2篇】: Python文件操作
Python文件操作 在Python中一个文件,就是一个操作对象,通过不同属性即可对文件进行各种操作.Python中提供了许多的内置函数和方法能够对文件进行基本操作. Python对文件的操作概括来说 ...
- Python list 操作
创建列表sample_list = ['a',1,('a','b')] Python 列表操作sample_list = ['a','b',0,1,3] 得到列表中的某一个值value_start = ...
- Python Mongo操作
# -*- coding: utf-8 -*- ''' Python Mongo操作Demo Done: ''' from pymongo import MongoClient conn = None ...
- python数据库操作之pymysql模块和sqlalchemy模块(项目必备)
pymysql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同. 1.下载安装 pip3 install pymysql 2.操作数据库 (1).执行sql #! ...
- [Python学习笔记][第七章Python文件操作]
2016/1/30学习内容 第七章 Python文件操作 文本文件 文本文件存储的是常规字符串,通常每行以换行符'\n'结尾. 二进制文件 二进制文件把对象内容以字节串(bytes)进行存储,无法用笔 ...
- python模块介绍- HTMLParser 简单的HTML和XHTML解析器
python模块介绍- HTMLParser 简单的HTML和XHTML解析器 2013-09-11 磁针石 #承接软件自动化实施与培训等gtalk:ouyangchongwu#gmail.comqq ...
- python excel操作总结
1.openpyxl包的导入 Dos命令行输入 pip install openpyxl==2.3.3 这里注意一下openpyxl包的版本问题 版本装的太高有很多api不支持了,所以笔者这里用的是2 ...
随机推荐
- FICO基础知识(二)
FI中的maser data: COA (Chart Of Account) 科目表 Account 科目 Vendor master dada 供应商主数据 Customer master da ...
- error eslint@5.12.0: The engine "node" is incompatible with this module.
初始化 react项目时报错: error eslint@5.12.0: The engine "node" is incompatible with this module. E ...
- codeforces365B
The Fibonacci Segment CodeForces - 365B You have array a1, a2, ..., an. Segment [l, r] (1 ≤ l ≤ r ≤ ...
- TM数据
qatestjr_xuyue10@vipabc.comqatestjr_xuyue01@vipabc.com jrNHc2 jUBRTEqatestjr_nianyue@vipabc.com QE9E ...
- hadoop MapReduce 入门
原创播客,如需转载请注明出处.原文地址:http://www.cnblogs.com/crawl/p/7687120.html ------------------------------------ ...
- MT【240】6*6放黑白子
$6*6$的方格中放三个完全相同的黑子和三个完全相同的白子,要求每行每列都有一个棋子,且每一格只有一个棋子.问有多少不同放法? 解:$\dfrac{36*25*16*9*4*1}{3!*3!}=144 ...
- 04 Zabbix核心概念回顾
04 Zabbix核心概念回顾 1. 监控四大核心功能: 数据采集----数据储存----数据展示和数据分析-----告警 1.1. 数据采集方式: SNMP:被监控设备上面必须启用SNMP a ...
- 自学Zabbix2.5-客户端agentd安装过程
点击返回:自学Zabbix之路 ....
- 一个简单的mock server
在前后端分离的项目中, 前端无需等后端接口提供了才调试, 后端无需等第三方接口提供了才调试, 基于“契约”,可以通过mock server实现调试, 下面是一个简单的mock server,通过pyt ...
- ST表与树状数组
ST表 st表可以解决区间最值的问题.可以做到O(nlogn)预处理 ,O(1)查询,但是不支持修改. st表的大概思路就是用st[i][j]来表示从i开始的2的j次方个树中的最值,查询时就从左端点 ...