Hadoop 历史服务配置启动查看
历史服务配置启动查看
1)配置mapred-site.xml
|
<property> <name>mapreduce.jobhistory.address</name> <value>hadoop-001:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-001:19888</value> </property> |
2)查看启动历史服务器文件目录:
[hadoop@hadoop-001 hadoop-2.7.2]# ls sbin/ |grep mr
mr-jobhistory-daemon.sh
3)启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
4)查看历史服务器是否启动
jps
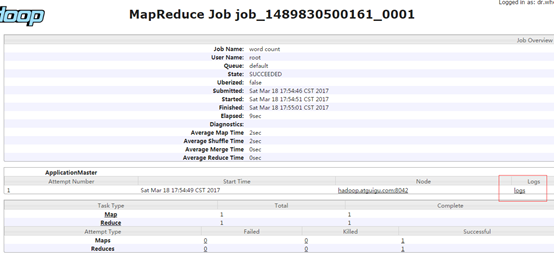
5)查看jobhistory
http://hadoop-001:19888/jobhistory
日志的聚集
日志聚集概念:应用运行完成以后,将日志信息上传到HDFS系统上
开启日志聚集功能步骤:
(1)配置yarn-site.xml
|
<!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
(2)关闭nodemanager 、resourcemanager和historymanager
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
sbin/mr-jobhistory-daemon.sh stop historyserver
(3)启动nodemanager 、resourcemanager和historymanager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
(4)删除hdfs上已经存在的hdfs文件
bin/hdfs dfs -rm -R /gec/mapreduce/wordcount/output
(5)执行wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /gec/mapreduce/wordcount/input /gec/mapreduce/wordcount/output
(6)查看日志
http://hadoop-001:19888/jobhistory


Hadoop 历史服务配置启动查看的更多相关文章
- Mapreduce 历史服务 配置启动查看
如果没有进行配置的话,那个History是不可以进行点击的,点击进去就会报错!所以需要进行配置一下 使用命令启动HistoryServer 就可以查看任务执行的进度了 命令: sbin/mr-jobh ...
- hadoop历史服务的启动与停止
a.配置项(在分布式环境中配置) 1.RPC访问地址 mapreduce.jobhistory.address 2.HTTP访问地址 mapreduce.jobhistory.webapp.addre ...
- 配置spark历史服务(spark二)
1. 编辑spark-defaults.conf位置文件 添加spark.eventLog.enabled和spark.eventLog.dir的配置修改spark.eventLog.dir为我们之前 ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
- 初识Hadoop一,配置及启动服务
一.Hadoop简介: Hadoop是由Apache基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS:Hadoo ...
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- linux服务创建及jq配置服务列表查看
1.应用背景 随着业务需求,后台处理服务不断增多,对于这些服务或后台程序的查看.更新操作越来越凌乱,所以我们首先需要一个服务列表查看工具,方便查看各 服务的端口.运行状态.jar包路径等等. 2.创建 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
随机推荐
- ios初识UITableView及简单用法二(模型数据)
// // ViewController.m // ZQRTableViewTest // // Created by zzqqrr on 17/8/24. // Copyright (c) 2017 ...
- memset memcpy
memset与memcpy的用法: void *memset(void *s,int c,size_t n)总的作用:将已开辟内存空间 s 的首 n 个字节的值设为值 cmemset可以方便的清空一个 ...
- 【Python】多线程-1
#练习:创建一个线程 from threading import Thread import time def run(a = None, b = None) : print a, b time.sl ...
- socket 映射服务器--(可处理多客户端连接(fork),显示退出信息)
server #include <stdio.h> #include <sys/types.h> /* See NOTES */ #include <sys/socket ...
- Spring Boot 揭秘与实战(五) 服务器篇 - Tomcat 代码配置
Spring Boot 内嵌的 Tomcat 服务器默认运行在 8080 端口.如果,我们需要修改Tomcat的端口,我们可以在 src/main/resources/application.prop ...
- PHP安全之Web攻击(转)
一.SQL注入攻击(SQL Injection) 攻击者把SQL命令插入到Web表单的输入域或页面请求的字符串,欺骗服务器执行恶意的SQL命令.在某些表单中,用户输入的内容直接用来构造(或者影响)动态 ...
- Linux批量解压文件
最近下载了Imagenet2012的数据文件,训练数据下有很多tar文件,这些tar文件都在一个目录内,所以想批量解压到该目录下每个单独的文件夹内 批量解压的步骤是, 1.列出所有的以tar为后缀的文 ...
- 九度OJ1111题-单词替换
题目1111:单词替换 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:6752 解决:1891 题目描述: 输入一个字符串,以回车结束(字符串长度<=100).该字符串由若干个单词组 ...
- mysql手动设置数据表的自增值
设置表tablename的自增值从1开始自增值 alter table tablename auto_increment=1;
- L1-009 N个数求和 (20 分)
本题的要求很简单,就是求N个数字的和.麻烦的是,这些数字是以有理数分子/分母的形式给出的,你输出的和也必须是有理数的形式. 输入格式: 输入第一行给出一个正整数N(≤100).随后一行按格式a1/b1 ...