Hadoop 历史服务配置启动查看
历史服务配置启动查看
1)配置mapred-site.xml
|
<property> <name>mapreduce.jobhistory.address</name> <value>hadoop-001:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-001:19888</value> </property> |
2)查看启动历史服务器文件目录:
[hadoop@hadoop-001 hadoop-2.7.2]# ls sbin/ |grep mr
mr-jobhistory-daemon.sh
3)启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
4)查看历史服务器是否启动
jps
5)查看jobhistory
http://hadoop-001:19888/jobhistory
日志的聚集
日志聚集概念:应用运行完成以后,将日志信息上传到HDFS系统上
开启日志聚集功能步骤:
(1)配置yarn-site.xml
|
<!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
(2)关闭nodemanager 、resourcemanager和historymanager
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
sbin/mr-jobhistory-daemon.sh stop historyserver
(3)启动nodemanager 、resourcemanager和historymanager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
(4)删除hdfs上已经存在的hdfs文件
bin/hdfs dfs -rm -R /gec/mapreduce/wordcount/output
(5)执行wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /gec/mapreduce/wordcount/input /gec/mapreduce/wordcount/output
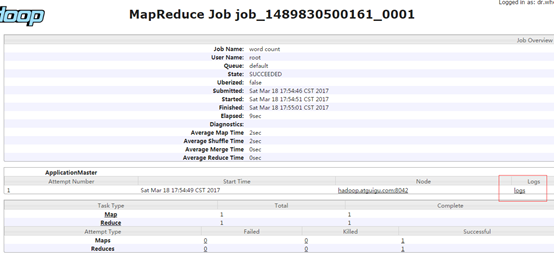
(6)查看日志
http://hadoop-001:19888/jobhistory


Hadoop 历史服务配置启动查看的更多相关文章
- Mapreduce 历史服务 配置启动查看
如果没有进行配置的话,那个History是不可以进行点击的,点击进去就会报错!所以需要进行配置一下 使用命令启动HistoryServer 就可以查看任务执行的进度了 命令: sbin/mr-jobh ...
- hadoop历史服务的启动与停止
a.配置项(在分布式环境中配置) 1.RPC访问地址 mapreduce.jobhistory.address 2.HTTP访问地址 mapreduce.jobhistory.webapp.addre ...
- 配置spark历史服务(spark二)
1. 编辑spark-defaults.conf位置文件 添加spark.eventLog.enabled和spark.eventLog.dir的配置修改spark.eventLog.dir为我们之前 ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
- 初识Hadoop一,配置及启动服务
一.Hadoop简介: Hadoop是由Apache基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS:Hadoo ...
- hadoop配置历史服务器&&配置日志聚集
配置历史服务器 1.在mapred-site.xml中写入一下配置 <property> <name>mapreduce.jobhistory.address</name ...
- linux服务创建及jq配置服务列表查看
1.应用背景 随着业务需求,后台处理服务不断增多,对于这些服务或后台程序的查看.更新操作越来越凌乱,所以我们首先需要一个服务列表查看工具,方便查看各 服务的端口.运行状态.jar包路径等等. 2.创建 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
随机推荐
- Spring Boot项目中使用Swagger2
Swagger2是一款restful接口文档在线生成和在线接口调试工具,Swagger2在Swagger1.x版本的基础上做了些改进,下面是在一个Spring Boot项目中引入Swagger2的简要 ...
- mysql三范式
第一范式:有主键,具有原子性,字段不可分割. 第二范式:完全依赖,没有部分依赖. 第三范式:没有传递依赖. 总结:数据库设计尽量遵循三范式,但是还是根据实际情况进行取舍,有时候会拿冗余还速度,最总用的 ...
- python DRF获取参数介绍
DRF获取参数的方式 例如url url(r'^demo/(?P<word>.*)/$', DemoView.as_view()) 在类视图中获取参数 url:http://127.0.0 ...
- Day8作业及默写
1,有如下文件,a1.txt,里面的内容为: 老男孩是最好的培训机构, 全心全意为学生服务, 只为学生未来,不为牟利. 我说的都是真的.哈哈 分别完成以下的功能: 将原文件全部读出来并打印. with ...
- python day16--面向对象(01)
一.概念 类:具有相同属性的一类事物 比如人类是类,人类中的某个人是对象.食物是一类,米饭是一个对象 class Person: '''类体:两部分:变量部分,方法(函数)部分''' mind = ' ...
- 莫烦tensorflow(2)-Session
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' import tensorflow as tfmatrix1 = tf.constant([[3,3] ...
- 【Python】unittest-2-断言
Unittest中的断言 1. python unintest单元测试框架提供了一整套内置的断言方法. (1)如果断言失败,则抛出一个AssertionError,并标识该测试为失败状态 (2)如果 ...
- GCC内置函数
在C语言写的程序中,有时候没有包含头文件,直接调用一些函数,如printf,也不会报错,因为GCC内置和一些函数.如果包含了头文件,则去第三方库中链接这个函数,不再使用GCC内置的函数.每个编译器的内 ...
- python list和numpy互换
http://blog.csdn.net/baiyu9821179/article/details/53365476
- Factor Graph因子图
参考链接1: 参考链接2: 参考ppt3: Factor Graph 是概率图的一种,概率图有很多种,最常见的就是Bayesian Network (贝叶斯网络)和Markov Random Fiel ...