Sqoop与HDFS、Hive、Hbase等系统的数据同步操作
Sqoop与HDFS结合
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出。
Sqoop import
它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示。
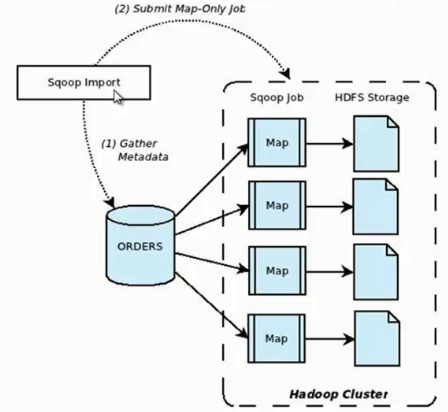
我们来分析一下 Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
下面我们看一下 Sqoop 如何使用命令行来导入数据的,其命令行语法如下所示
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --target-dir /junior/sqoop/ \ //可选,不指定目录,数据默认导入到/user下 --where "sex='female'" \ //可选 --as-sequencefile \ //可选,不指定格式,数据格式默认为 Text 文本格式 --num-mappers 10 \ //可选,这个数值不宜太大 --null-string '\\N' \ //可选 --null-non-string '\\N' \ //可选
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名。
--table:要读取的数据库表。
--target-dir:将数据导入到指定的 HDFS 目录下,文件名称如果不指定的话,会默认数据库的表名称。
--where:过滤从数据库中要导入的数据。
--as-sequencefile:指定数据导入数据格式。
--num-mappers:指定 Map 任务的并发度。
--null-string,--null-non-string:同时使用可以将数据库中的空字段转化为'\N',因为数据库中字段为 null,会占用很大的空间。
下面我们介绍几种 Sqoop 数据导入的特殊应用。
1、Sqoop 每次导入数据的时候,不需要把以往的所有数据重新导入 HDFS,只需要把新增的数据导入 HDFS 即可,下面我们来看看如何导入新增数据。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --incremental append \ //代表只导入增量数据 --check-column id \ //以主键id作为判断条件 --last-value 999 //导入id大于999的新增数据
上述三个组合使用,可以实现数据的增量导入。
2、Sqoop 数据导入过程中,直接输入明码存在安全隐患,我们可以通过下面两种方式规避这种风险。
1)-P:sqoop 命令行最后使用 -P,此时提示用户输入密码,而且用户输入的密码是看不见的,起到安全保护作用。密码输入正确后,才会执行 sqoop 命令。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --table user \ -P
2)--password-file:指定一个密码保存文件,读取密码。我们可以将这个文件设置为只有自己可读的文件,防止密码泄露。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --table user \ --password-file my-sqoop-password
Sqoop export
它的功能是将数据从 HDFS 导入关系型数据库表中,其流程图如下所示。

我们来分析一下 Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。
下面我们看一下 Sqoop 如何使用命令行来导出数据的,其命令行语法如下所示。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名和密码。
--table:要导入的数据库表。
--export-dir:数据在 HDFS 上的存放目录。
下面我们介绍几种 Sqoop 数据导出的特殊应用。
1、Sqoop export 将数据导入数据库,一般情况下是一条一条导入的,这样导入的效率非常低。这时我们可以使用 Sqoop export 的批量导入提高效率,其具体语法如下。
sqoop export \ --Dsqoop.export.records.per.statement=10 \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --export-dir user \ --batch
--Dsqoop.export.records.per.statement:指定每次导入10条数据,--batch:指定是批量导入。
2、在实际应用中还存在这样一个问题,比如导入数据的时候,Map Task 执行失败, 那么该 Map 任务会转移到另外一个节点执行重新运行,这时候之前导入的数据又要重新导入一份,造成数据重复导入。 因为 Map Task 没有回滚策略,一旦运行失败,已经导入数据库中的数据就无法恢复。Sqoop export 提供了一种机制能保证原子性, 使用--staging-table 选项指定临时导入的表。Sqoop export 导出数据的时候会分为两步:第一步,将数据导入数据库中的临时表,如果导入期间 Map Task 失败,会删除临时表数据重新导入;第二步,确认所有 Map Task 任务成功后,会将临时表名称为指定的表名称。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --staging-table staging_user
3、在 Sqoop 导出数据过程中,如果我们想更新已有数据,可以采取以下两种方式。
1)通过 --update-key id 更新已有数据。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --update-key id
2)使用 --update-key id和--update-mode allowinsert 两个选项的情况下,如果数据已经存在,则更新数据,如果数据不存在,则插入新数据记录。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --update-key id \ --update-mode allowinsert
4、如果 HDFS 中的数据量比较大,很多字段并不需要,我们可以使用 --columns 来指定插入某几列数据。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --column username,sex
5、当导入的字段数据不存在或者为null的时候,我们使用--input-null-string和--input-null-non-string 来处理。
sqoop export \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --input-null-string '\\N' \ --input-null-non-string '\\N'
Sqoop与其它系统结合
Sqoop 也可以与Hive、HBase等系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME、HIVE_HOME等环境变量。
1、Sqoop与Hive结合比较简单,使用 --hive-import 选项就可以实现。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --hive-import
2、Sqoop与HBase结合稍微麻烦一些,需要使用 --hbase-table 指定表名称,使用 --column-family 指定列名称。
sqoop import \ --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \ --username sqoop \ --password sqoop \ --table user \ --hbase-table user \ --column-family city
参考资料:https://www.cnblogs.com/qiaoyihang/p/6229714.html
Sqoop与HDFS、Hive、Hbase等系统的数据同步操作的更多相关文章
- Sqoop_具体总结 使用Sqoop将HDFS/Hive/HBase与MySQL/Oracle中的数据相互导入、导出
一.使用Sqoop将MySQL中的数据导入到HDFS/Hive/HBase watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvYWFyb25oYWRvb3A=/ ...
- Flume + HDFS + Hive日志收集系统
最近一段时间,负责公司的产品日志埋点与收集工作,搭建了基于Flume+HDFS+Hive日志搜集系统. 一.日志搜集系统架构: 简单画了一下日志搜集系统的架构图,可以看出,flume承担了agent与 ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
- sqoop1.4.6从mysql导入hdfs\hive\hbase实例
//验证sqoop是否连接到mysql数据库sqoop list-tables --connect 'jdbc:mysql://n1/guizhou_test?useUnicode=true& ...
- sqoop的导入|Hive|Hbase
导入数据(集群为对象) 在Sqoop中“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字. 1 RDBMS到HD ...
- 利用Sqoop将MySQL海量测试数据导入HDFS和HBase
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.安装Sqoop 1.下载sqoop,解压.文件夹重命名 wget http://mirror.bit.edu.cn/apache/sqoop/1 ...
- sqoop命令,mysql导入到hdfs、hbase、hive
1.测试MySQL连接 bin/sqoop list-databases --connect jdbc:mysql://192.168.1.187:3306/trade_dev --username ...
- Centos搭建mysql/Hadoop/Hive/Hbase/Sqoop/Pig
目录: 准备工作 Centos安装 mysql Centos安装Hadoop Centos安装hive JDBC远程连接Hive Hbase和hive整合 Centos安装Hbase 准备工作: 配置 ...
- Hive/hbase/sqoop的基本使用教程~
Hive/hbase/sqoop的基本使用教程~ ###Hbase基本命令start-hbase.sh #启动hbasehbase shell #进入hbase编辑命令 list ...
随机推荐
- MyEclipse下创建的项目 导入eclipse
1.导入在MyEclipse下创建的项目 2.把项目变成Web项目,在项目上右键-->Properties-->选择Project Facets-->点击Convert to fac ...
- Linux I/O重定向
所谓I/O重定向简单来说就是一个过程,这个过程捕捉一个文件,或者命令,程序,脚本,甚至脚本中的代码块的输出,然后把捕捉到的输出,作为输入 发送给另外一个文件,命令,程序,或者脚本.谈到I/O重定向,就 ...
- 3.1-uC/OS-III的特点:
1.C/OS-III是一个可扩展的, 可固化的, 抢占式的实时内核, 它管理的任务个数不受限制. 它是第三代内核, 提供了现代实时内核所期望的所有功能包括资源管理.同步.内部任务交流等. uC/OS- ...
- Linux软件包的安装(rpm+yum)
概述: 1.rpm软件包管理命令软件包的获取a.光盘镜像中有很多软件包可以使用:先挂载光盘,再查看软件包b.从软件的官网获取 .rpm 安装rpm包 ipm -ivh 软件包名称删除rpm包 ipm ...
- 前端框架之Vue(2)-模板语法
Vue.js 使用了基于 HTML 的模板语法,允许开发者声明式地将 DOM 绑定至底层 Vue 实例的数据.所有 Vue.js 的模板都是合法的 HTML ,所以能被遵循规范的浏览器和 HTML 解 ...
- awesome vue
https://blog.csdn.net/caijunfen/article/details/78216868
- Spring boot 整合hive-jdbc导致无法启动的问题
使用Spring boot整合Hive,在启动Spring boot项目时,报出异常: 经过排查,是maven的包冲突引起的,具体做法,排除:jetty-all.hive-shims依赖包.对应的po ...
- mysql 1,2,3 关联查询出数字代表的具体意思
建表 TEST1 CREATE TABLE `TEST1` (`ID` int(11) NOT NULL,`IID` varchar(200) DEFAULT NULL,PRIMARY KEY (`I ...
- iot-hub物管理bug
物管理中,物绑定证书,如果证书被删除,将会出错 初始化用到 证书编码,证书为null时,null.code报错
- jenkins 的一个BUG
最近更新了一批jenkin插件,更新完问题来了全局设置无法保存了... 报错如下 Stack trace net.sf.json.JSONException: null object at net.s ...