Spark机器学习(10):ALS交替最小二乘算法
1. Alternating Least Square
ALS(Alternating Least Square),交替最小二乘法。在机器学习中,特指使用最小二乘法的一种协同推荐算法。如下图所示,u表示用户,v表示商品,用户给商品打分,但是并不是每一个用户都会给每一种商品打分。比如用户u6就没有给商品v3打分,需要我们推断出来,这就是机器学习的任务。
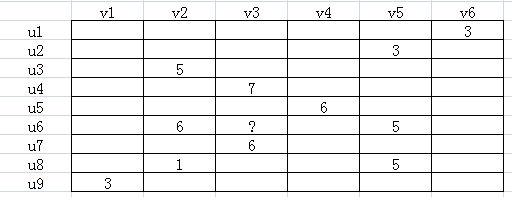
由于并不是每个用户给每种商品都打了分,可以假设ALS矩阵是低秩的,即一个m*n的矩阵,是由m*k和k*n两个矩阵相乘得到的,其中k<<m,n。
Am×n=Um×k×Vk×n
这种假设是合理的,因为用户和商品都包含了一些低维度的隐藏特征,比如我们只要知道某个人喜欢碳酸饮料,就可以推断出他喜欢百世可乐、可口可乐、芬达,而不需要明确指出他喜欢这三种饮料。这里的碳酸饮料就相当于一个隐藏特征。上面的公式中,Um×k表示用户对隐藏特征的偏好,Vk×n表示产品包含隐藏特征的程度。机器学习的任务就是求出Um×k和Vk×n。可知uiTvj是用户i对商品j的偏好,使用Frobenius范数来量化重构U和V产生的误差。由于矩阵中很多地方都是空白的,即用户没有对商品打分,对于这种情况我们就不用计算未知元了,只计算观察到的(用户,商品)集合R。
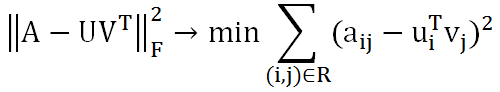
这样就将协同推荐问题转换成了一个优化问题。目标函数中U和V相互耦合,这就需要使用交替二乘算法。即先假设U的初始值U(0),这样就将问题转化成了一个最小二乘问题,可以根据U(0)可以计算出V(0),再根据V(0)计算出U(1),这样迭代下去,直到迭代了一定的次数,或者收敛为止。虽然不能保证收敛的全局最优解,但是影响不大。
2. MLlib的ALS实现
MLlib的ALS采用了数据分区结构,即将U分解成u1,u2,u3,...um,V分解成v1,v2,v3,...vn,相关的u和v存放在同一个分区,从而减少分区间数据交换的成本。比如通过U计算V时,存储u的分区是P1,P2...,存储v的分区是Q1,Q2...,需要将不同的u发送给不同的Q,存放这个关系的块称作OutBlock;在P中,计算v时需要哪些u,存放这个关系的块称作InBlock。
比如R中有a12,a13,a15,u1存放在P1,v2,v3存放在Q2,v5存放在Q3,则需要将P1中的u1发送给Q2和Q3,这个信息存储在OutBlock;R中有a12,a32,因此计算v2需要u1和u3,这个信息存储在InBlock。
直接上代码:
import org.apache.log4j.{ Level, Logger }
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
/**
* Created by Administrator on 2017/7/19.
*/
object ALSTest01 {
def main(args:Array[String]) ={
// 设置运行环境
val conf = new SparkConf().setAppName("ALS 01")
.setMaster("spark://master:7077").setJars(Seq("E:\\Intellij\\Projects\\MachineLearning\\MachineLearning.jar"))
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
// 读取样本数据并解析
val dataRDD = sc.textFile("hdfs://master:9000/ml/data/test.data")
val ratingRDD = dataRDD.map(_.split(',') match {
case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
})
// 拆分成训练集和测试集
val dataParts = ratingRDD.randomSplit(Array(0.8, 0.2))
val trainingRDD = dataParts(0)
val testRDD = dataParts(1)
// 建立ALS交替最小二乘算法模型并训练
val rank = 10
val numIterations = 10
val alsModel = ALS.train(trainingRDD, rank, numIterations, 0.01)
// 预测
val user_product = trainingRDD.map {
case Rating(user, product, rate) =>
(user, product)
}
val predictions =
alsModel.predict(user_product).map {
case Rating(user, product, rate) =>
((user, product), rate)
}
val ratesAndPredictions = trainingRDD.map {
case Rating(user, product, rate) =>
((user, product), rate)
}.join(predictions)
val MSE = ratesAndPredictions.map {
case ((user, product), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean()
println("Mean Squared Error = " + MSE)
println("User" + "\t" + "Products" + "\t" + "Rate" + "\t" + "Prediction")
ratesAndPredictions.collect.foreach(
rating => {
println(rating._1._1 + "\t" + rating._1._2 + "\t" + rating._2._1 + "\t" + rating._2._2)
}
)
}
}
其中ALS.train()函数的4个参数分别是训练用的数据集,特征数量,迭代次数,和正则因子。
运行结果:
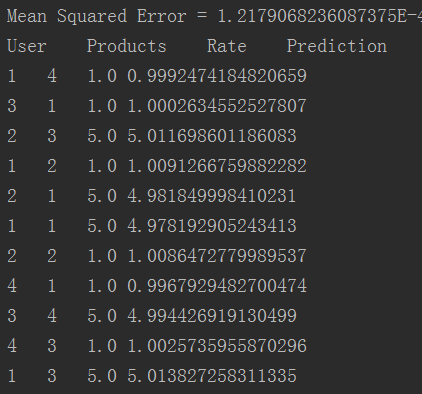
可见,预测结果还是非常准确的。
Spark机器学习(10):ALS交替最小二乘算法的更多相关文章
- Spark机器学习(11):协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是一种常用的推荐算法,它的思想就是找出相似的用户或产品,向用户推荐相似的物品,或者把物品推荐给相似的用户.怎样评价用户对商品的偏好? ...
- Spark机器学习(2):逻辑回归算法
逻辑回归本质上也是一种线性回归,和普通线性回归不同的是,普通线性回归特征到结果输出的是连续值,而逻辑回归增加了一个函数g(z),能够把连续值映射到0或者1. MLLib的逻辑回归类有两个:Logist ...
- 掌握Spark机器学习库-07-线性回归算法概述
1)简介 自变量,因变量,线性关系,相关系数,一元线性关系,多元线性关系(平面,超平面) 2)使用线性回归算法的前提 3)应用例子 沸点与气压 浮力与表面积
- 【Spark机器学习速成宝典】推荐引擎——协同过滤
目录 推荐模型的分类 ALS交替最小二乘算法:显式矩阵分解 Spark Python代码:显式矩阵分解 ALS交替最小二乘算法:隐式矩阵分解 Spark Python代码:隐式矩阵分解 推荐模型的分类 ...
- 交替最小二乘ALS
https://www.cnblogs.com/hxsyl/p/5032691.html http://www.cnblogs.com/skyEva/p/5570098.html 1. 基础回顾 矩阵 ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- Spark机器学习解析下集
上次我们讲过<Spark机器学习(上)>,本文是Spark机器学习的下部分,请点击回顾上部分,再更好地理解本文. 1.机器学习的常见算法 常见的机器学习算法有:l 构造条件概率:回归分 ...
- spark 机器学习 ALS原理(一)
1.线性回归模型线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归.当你使用它时,你首先假设输出变量(相应变量.因变量.标签)和预测变量(自变量.解释变量.特征)之间存 ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
随机推荐
- 【Java】 剑指offer(36) 二叉搜索树与双向链表
本文参考自<剑指offer>一书,代码采用Java语言. 更多:<剑指Offer>Java实现合集 题目 输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表.要求不 ...
- Java Web报错: GET http://localhost:8080/ 404 (Not Found)
eclipse正常启动tomcat,但是 访问http://localhost:8080 报404错误 搞笑的是我访问服务器中的其他网页也可以打开 报错如下: 解决: 如果这3项都已经变灰色,删除配置 ...
- C6000 CSL 函数说明
转自:http://bbs.21ic.com/icview-741800-1-1.html 先来看一个例子 代码1 CSL_FINST(osdRegs->VIDWINMD, OSD_VIDWIN ...
- window下mongodb安装和配置
mongodb安装和配置 1.下载:https://www.mongodb.com 2.解压到盘的根目录下,本人解压到D盘根目录 3.在软件根目录下新建一个文件夹data 4.再新建两个文件夹db.l ...
- How to use Jackson to deserialise an array of objects
first create a mapper : import com.fasterxml.jackson.databind.ObjectMapper; ObjectMapper mapper = ne ...
- web 连接池配置
TOMCAT J2EE项目连接池配置 web 项目的 web.xml <web-app> <resource-ref> <description>DB Connec ...
- Progressive web app理念及发展前景
前一段时间微信推出微信小程序进行公测,着实火了一把,博得了大众的眼球,不明真相的吃瓜观众们纷纷围观,所谓的“微信小程序”,通俗的讲就是一种不需要下载安装即可使用的应用程序,脱离于app商店依托于浏览器 ...
- BZOJ 3994: [SDOI2015]约数个数和3994: [SDOI2015]约数个数和 莫比乌斯反演
https://www.lydsy.com/JudgeOnline/problem.php?id=3994 https://blog.csdn.net/qq_36808030/article/deta ...
- 【织梦dedecms系统安全】完善DEDECMS目录的权限安全设置
[织梦dedecms系统安全]完善DEDECMS目录的权限安全设置: ../ [站点上级目录] 如果要使用后台的目录相关的功能需要有列出目录的权限 / [站点根目录] 需要执行和读 ...
- C# 添加动态属性
1.ExpandoObject(System.Dynamic) 2.JObject(Newtonsoft.Json.Linq)