Azure SQL 数据库仓库Data Warehouse (2) 架构
《Windows Azure Platform 系列文章目录》
在上一篇文章中,笔者介绍了MPP架构的基本内容
在本章中,笔者给大家介绍一下Azure SQL Data Warehouse数据仓库(SQL DW)的架构。
1.SQL DW分为Head Node和Work Node,下图用Control Node和Compute Node表示
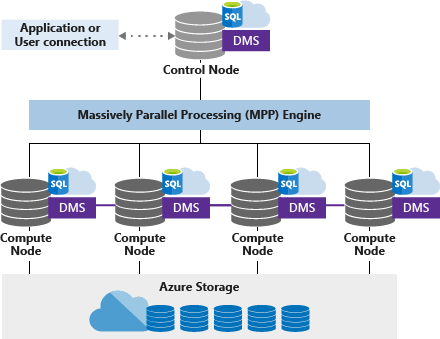
SQL DW是用多个Work Node横向扩展的方式,来支持PB级别的大量关系型数据。
应用程序将T-SQL命令发送给Head Node。Head Node使用MPP引擎,该引擎优化并行处理的查询,然后将查询发送给Work Node进行并行查询
Work Node将需要处理的数据保存到Azure Storage中,并进行并行查询
数据移动服务(DMS)是SQL DW的内部服务,可根据需要跨节点移动数据,以并行运行查询并返回准确的结果
2.SQL DW是计算和存储分离
用户的数据是保存在Azure Storage 中的,并不保存在Work Node的本地磁盘上。
SQL DW实现了Work Node和用户数据的逻辑依赖关系,数据并不移动
也就是说,当用户的Work Node从6台,横向扩展到10台后,SQL DW重新设置了10个Work Node到Azure Storage的逻辑关系
3.Azure Storage
SQL DW底层使用的是Azure Premium Storage,也就是SSD 固态硬盘存储。
同时用户也可以设置数据库表在SSD存储上的分布模式。SQL DW支持的数据表的分布模式有:
(1)轮询 Round Robin
(2)哈希 Hash
(3)复制 Replication
4.Head Node
Head Node是SQL DW的大脑。Head Node在最前端,处理应用程序的交互和链接。
在Head Node上的MPP引擎,优化和协调并行查询。
当用户提交了一个T-SQL查询,Head Node会将该查询转换,在所有的Work Node上并行查询
5.Work Node
Work Node是真正进行计算的节点。Work Node节点的数量范围是1-60.
每个Work Node都有一个在系统视图中可见的Node ID。我们可以可以通过查找名称以sys.pdw_nodes开头的系统视图中的node_id列来查看Compute节点ID
6.数据分区模式
分区是在分布式数据上运行的并行查询的基本存储和处理单元。
当SQL DW进行查询的时候,任务被分为60个并行执行的子查询。每个子查询都在1个数据分布上运行。
默认情况下,用户的数据被分为60份 (60个分区)。
当Work Node节点数量为1的时候,1个Work Node处理60个分区数据。
当Work Node节点数量为2的时候,2个Work Node处理60个分区数据,每个Work Node处理30个分区数据
当Work Node节点数量为3的时候,3个Work Node处理60个分区数据,每个Work Node处理20个分区数据
......
当Work Node节点数量为60的时候,60个Work Node处理60个分区数据,每个Work Node处理1个分区数据,这样并行度最高
举个例子,假设我们只有1个数据库,这个数据库只有1张表,这张表有6000万行数据
当Work Node节点数量为1的时候,1个Work Node处理6000万行数据,这样并行度最低
当Work Node节点数量为2的时候,2个Work Node处理6000万行数据,每个Work Node处理3000万行数据
当Work Node节点数量为3的时候,3个Work Node处理6000万行数据,每个Work Node处理2000万行数据
......
当Work Node节点数量为60的时候,60个Work Node处理6000万行数据,每个Work Node处理100万行数据,这样并行度最高
观察可以发现,设置SQL DW 分区模式是非常重要的
我们在上面介绍了,SQL DW支持的数据表的分区模式有三种:轮询 Round Robin,哈希 Hash,复制 Replication
7.轮训 Round Robin
轮询表是最简单的分布模式,一般用于临时表
轮询表中的数据是平均分布的,不进行任何优化。在使用轮训表的时候,SQL DW随机选择一个分布键,然后将数据随机的写入轮询表
与哈希分布表不同的是,值相等的行不一定分配到相同的分布区。
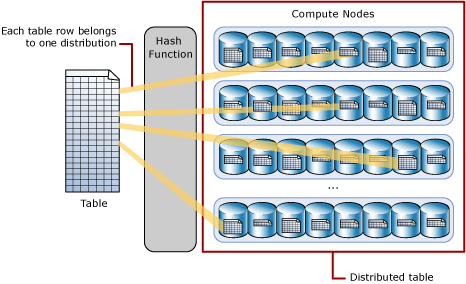
8.哈希 Hash
哈希表为大型数据库表提供表连接(join)和聚合查询(aggregation),提供最高的性能
在使用Hash表的时候,SQL DW使用Hash函数,将每一行都分配到同一个分区。
在数据库表中,定义其中一列为分区列,使用Hash函数将数据保存到同一个分区中
下图说明了Hash Table
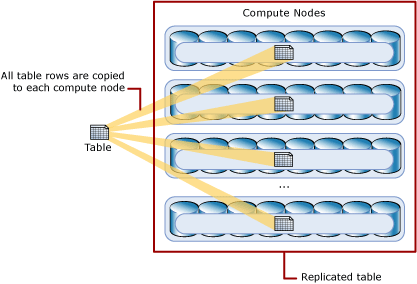
9.复制 Replica
复制表为数据量小的表,提供了最快的查询性能
复制表在每个Work Node上缓存表的完整副本。因此,在使用复制表进行表连接(join)和聚合查询(aggregation)的时候,不会产生数据在Work Node上移动
复制表最好用于数据量小的表,在表大小小于2GB时,复制表效果好
下图说明了复制Replica表
Azure SQL 数据库仓库Data Warehouse (2) 架构的更多相关文章
- Azure SQL 数据库仓库Data Warehouse (3) DWU
<Windows Azure Platform 系列文章目录> 在笔者的上一篇文章中:Azure SQL 数据库仓库Data Warehouse (2) 架构 介绍了SQL DW的工作节点 ...
- Azure SQL 数据库仓库Data Warehouse (1) 入门
<Windows Azure Platform 系列文章目录> 在之前的项目中遇到了客户使用SQL数据仓库的场景,在这里记录一下 1.什么是SQL 数据库仓库 (SQL DW) SQL D ...
- Azure SQL 数据库仓库Data Warehouse (4) 2018 TechSummit 动手实验营
<Windows Azure Platform 系列文章目录> 上传一下之前在2018 TechSummit的动手实验营:Azure数据仓库PaaS项目架构规划与实战入门 包含PPT和Wo ...
- Azure SQL 数据库弹性池现已面市
我们高兴地宣布Azure SQL 数据库弹性池现已正式面市.弹性池自去年试运行以来,得到许多软件即服务(SaaS)供应商和企业开发人员的认可,他们利用弹性池管理持续增长的云数据库和应用程序,成果高效. ...
- Azure SQL 数据库:新服务级别问答
ShawnBice 2014 年 5 月 1 日上午 11:10 本月初,我们庆祝了SQL Server 2014 的推出,并宣布正式发布分析平台系统,同时分享了智能系统服务预览版.Quentin ...
- 如何将Azure SQL 数据库还原到本地数据库实例中
原文:https://www.jerriepelser.com/blog/restore-sql-database-localdb/ 原文作者: Jerrie Pelser 译文:如何将Azure S ...
- 试用 Azure Sql 数据库
我们的12月试用账号的免费服务里有一个Azure Sql服务,最近正好自己做一个小工具需要一个数据库,正好可以把它当测试库顺便体验一把Azure Sql. 概述 Azure SQL 数据库 Azure ...
- Azure SQL 数据库新服务级别现已正式发布
T.K.Ranga Rengarajan 2014 年 9 月 10 日上午 11:00 我们很高兴地宣布,新的 SQL 数据库服务级被基本.标准和高级级别现已正式发布.这些服务级别中含有内置且可 ...
- Azure SQL 数据库:服务级别与性能问答
ShawnBice 2014 年 5 月 5 日上午 10:00 几天前,我发表了一篇文章,并就 4 月 24 日发布的适用于Windows Azure SQL 数据库的新服务级别提供了一些预料 ...
随机推荐
- J - FatMouse's Speed
p的思路不一定要到最后去找到ans:也可以设置成在中间找到ans:比如J - FatMouse's Speed 这个题,如果要是让dp[n]成为最终答案的话,即到了i,最差的情况也是dp[i-1],就 ...
- 20155208 实验四 Android开发基础
20155208 实验四 Android开发基础 实验内容 1.基于Android Studio开发简单的Android应用并部署测试; 2.了解Android.组件.布局管理器的使用: 3.掌握An ...
- FTP相关、用vsftpd搭建ftp、xshell使用xftp传输文件、使用pure-ftpd搭建ftp服务
1.FTP相关(file transfer protocol,文件传输协议) 2.用vsftpd搭建ftp安装:yum install vsftpd -y创建一个虚拟用户:useradd vft ...
- json/pickle模块(序列化)
什么叫序列化? 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes 为什么要序列化? 你打游戏过程中,打累了,停下来,关掉游戏.想 ...
- Go Example--原子计数器
package main import ( "fmt" "runtime" "sync/atomic" "time" ) ...
- mac-ppt-auto-open-recovery-files
mac 每次打开PPT都会出现一个自动保存的文件,不知道这个文件是保存在哪里,该怎么删除 打开finder(访达),按 shift+command+G,输入~/Library/Containers/c ...
- zabbix监控mysql最简单的方法
该实验基于我的上一篇文章监控第一台主机的基础上 首先,因为水平有限,我选择直接关闭了防火墙和SELinux. 环境: 两台centos7,服务器端IP是192.168.200.128(以下简称主机), ...
- linux之数据备份
第一种方法:tar备份 [root@bogon ~]# cat bp/linux.txt no centos [root@bogon ~]# tar cvf bp.tar bp //打包bp目录 bp ...
- DevExpress控件使用方法:第二篇 barManager
标题栏 一.Bars 1. 把BarManager组件添加到窗体中后,会自动创建三个空的 bars: 主菜单(通常位于窗体顶部).顶部工具栏.窗体底部的状态栏. 2. 隐藏左侧的竖线和右边的箭 ...
- powerdesigner16.5 破解
powerdesigner16.5 破解 方法: 破解方法 1.将下载下来的PowerDesigner165_破解文件.rar进行解压,之后找到pdflm16.dll破解文件,并将pdflm16.dl ...