[Localization] MobileNet with SSD
先来一波各版本性能展览:
Pre-trained Models
Choose the right MobileNet model to fit your latency and size budget. The size of the network in memory and on disk is proportional to the number of parameters. The latency and power usage of the network scales with the number of Multiply-Accumulates (MACs) which measures the number of fused Multiplication and Addition operations. These MobileNet models have been trained on the ILSVRC-2012-CLS image classification dataset. Accuracies were computed by evaluating using a single image crop.
| Model Checkpoint | Million MACs | Million Parameters | Top-1 Accuracy | Top-5 Accuracy |
|---|---|---|---|---|
| MobileNet_v1_1.0_224 | 569 | 4.24 | 70.7 | 89.5 |
| MobileNet_v1_1.0_192 | 418 | 4.24 | 69.3 | 88.9 |
| MobileNet_v1_1.0_160 | 291 | 4.24 | 67.2 | 87.5 |
| MobileNet_v1_1.0_128 | 186 | 4.24 | 64.1 | 85.3 |
| MobileNet_v1_0.75_224 | 317 | 2.59 | 68.4 | 88.2 |
| MobileNet_v1_0.75_192 | 233 | 2.59 | 67.4 | 87.3 |
| MobileNet_v1_0.75_160 | 162 | 2.59 | 65.2 | 86.1 |
| MobileNet_v1_0.75_128 | 104 | 2.59 | 61.8 | 83.6 |
| MobileNet_v1_0.50_224 | 150 | 1.34 | 64.0 | 85.4 |
| MobileNet_v1_0.50_192 | 110 | 1.34 | 62.1 | 84.0 |
| MobileNet_v1_0.50_160 | 77 | 1.34 | 59.9 | 82.5 |
| MobileNet_v1_0.50_128 | 49 | 1.34 | 56.2 | 79.6 |
| MobileNet_v1_0.25_224 | 41 | 0.47 | 50.6 | 75.0 |
| MobileNet_v1_0.25_192 | 34 | 0.47 | 49.0 | 73.6 |
| MobileNet_v1_0.25_160 | 21 | 0.47 | 46.0 | 70.7 |
| MobileNet_v1_0.25_128 | 14 | 0.47 | 41.3 | 66.2 |

前两个大小还是可以接受的。
Here is an example of how to download the MobileNet_v1_1.0_224 checkpoint:
$ CHECKPOINT_DIR=/tmp/checkpoints
$ mkdir ${CHECKPOINT_DIR}
$ wget http://download.tensorflow.org/models/mobilenet_v1_1.0_224_2017_06_14.tar.gz
$ tar -xvf mobilenet_v1_1.0_224_2017_06_14.tar.gz
$ mv mobilenet_v1_1.0_224.ckpt.* ${CHECKPOINT_DIR}
$ rm mobilenet_v1_1.0_224_2017_06_14.tar.gz
代码于此,未来需研究一波。
models/research/slim/nets/mobilenet_v1.py
传统卷积-->分离成每个通道的单滤波器卷积 then 与每个pixel的1*1卷积做合并。可以提高至少十倍性能!
Ref: http://www.jianshu.com/p/072faad13145
Ref: http://blog.csdn.net/jesse_mx/article/details/70766871
摘要
- 使用深度可分解卷积(depthwise separable convolutions)来构建轻量级深度神经网络的精简结构(streamlined architecture,流线型结构 or 精简结构,倾向于后者)。
- 本文引入了两个 简单的全局超参来有效权衡延迟(latency)和准确度(accuracy)。这些超参允许模型构建者根据具体问题的限制为他们的应用选择规模合适的模型。
1.引言
2.背景介绍
1)直接设计较小且高效的网络,并训练。
- Inception思想,采用小卷积。
- Network in Network 改进传统CNN,使用1x1卷积,提出MLP CONV层Deep Fried Convents采用Adaptive Fast-food transform重新 参数化全连接层的向量矩阵。
- SqueezeNet设计目标主要是为了简化CNN的模型参数数量,主要采用了替换卷积核3x3为1x1,使用了deep compression技术对网络进行了压缩 。
- Flattened networks针对快速前馈执行设计的扁平神经网络。
- 采用hashing trick进行压缩;采用huffman编码;
- 用大网络来教小网络;
- 训练低精度乘法器;
- 采用二进制输入二进制权值等等。
3.MobileNet 架构
- 深度可分解滤波(depth wise separable filters)建立的MobileNets核心层;
- 两个模型收缩超参:宽度乘法器和分辨率乘法器(width multiplier和resolution multiplier)。
3.1.深度可分解卷积(Depthwise Separable Convolution)
MobileNet模型机遇深度可分解卷积,其可以将标准卷积分解成 一个深度卷积和一个1x1的点卷积。


3.2. 网络结构和训练

对应的api:https://www.tensorflow.org/versions/r0.12/api_docs/python/nn/convolution
tf.nn.depthwise_conv2d(input, filter, strides, padding, name=None)

3.3.宽度乘法器(Width Multiplier)
第一个超参数,即宽度乘数 α 。
为了构建更小和更少计算量的网络,引入了宽度乘数 α ,改变输入输出通道数,减少特征图数量,让网络变瘦。
在 α 参数作用下,MobileNets某一层的计算量为:
其中, α 取值是0~1,应用宽度乘数可以进一步减少计算量,大约有 α2 的优化空间。
3.4. 分辨率乘法器(Resolution Multiplier)
第二个超参数是分辨率乘数 ρ
用来改变输入数据层的分辨率,同样也能减少参数。
在 α 和 ρ 共同作用下,MobileNets某一层的计算量为:
DK×DK×αM×ρDF×ρDF + αM×αN×ρDF×ρDF
其中,ρ 是隐式参数,ρ 如果为{1,6/7,5/7,4/7},则对应输入分辨率为{224,192,160,128},ρ 参数的优化空间同样是 ρ2 左右。

以上就是重点。
Final Report: Towards Real-time Detection and Camera Triggering
在草莓pi上各个轻网络的的实验效果,其中有介绍剪裁网络的思路,提供了很多线索,挺好。
以及对mobileNet结构的微调方法。
The main thing that makes MobileNets stand out is its use of depthwise separable convolution (DSC) layer.
The Intuition behind DSC: studies [2] have showed that DSC can be treated as an extreme case of inception module.
The structure of Mobile-Det is similar to ssd-vgg-300: [Localization] SSD - Single Shot MultiBoxDetector the original SSD framework.
- The difference is that rather than using VGG, now the backbone is MobileNets,
- and also all the following added convolution is replaced with depthwise separable convolution.
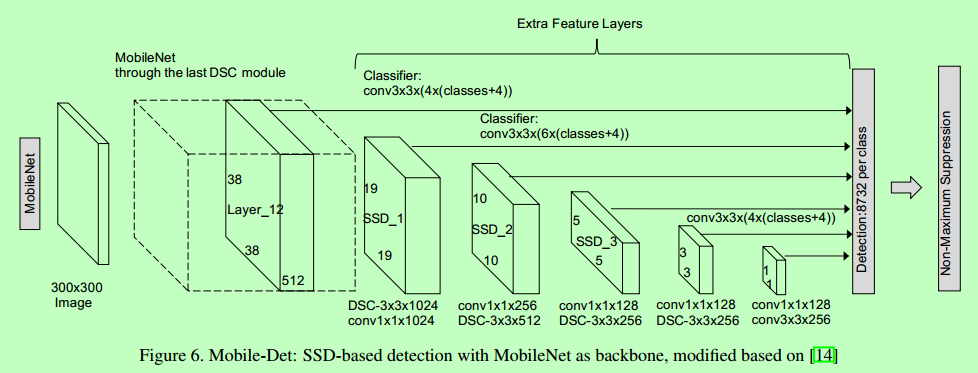
The benefit of using SSD framework is evident:
now we have a unified model and is able to train end-to-end;
we do not rely on the reference frame and hence the temporal information, expanding our application scenarios;
it is also more accurate in theory.
However, the main issue is that, the model becomes very slow, as a large amount of convolution operations are added.
In this project, we tested a variety of detection models, including the state-of-art YOLO2, and two our newly proposed models: Temporal Detection and Mobile-Det.
We conclude that the current object detection methods, although accurate, is far from being able to be deployed in real-world applications due to large model size and slow speed.
Our work of Mobile-Det shows that the combination of SSD and MobileNet provides a new feasible and promising insight on seeking a faster detection framework.
Finally, we present the power of temporal information and shows differential based region proposal can drastically increase the detection speed.
7. Future work
There are a few aspects that could potentially improve the performance but remains to be implemented due to limited time, including:
• Implement an efficient inference module of 8bit float in C++ to better take advantage of the speed up of quantization to inference step on small device.
• Try to combine designed CNN modules like MobileNet module and fire module with other real-time standard detection frameworks.
【fire layer貌似不好使,有实验已测试】
今后课题:
- 如何训练识别两个以上的物体。
- 使用传统算子生成训练集。
[Localization] MobileNet with SSD的更多相关文章
- 本人AI知识体系导航 - AI menu
Relevant Readable Links Name Interesting topic Comment Edwin Chen 非参贝叶斯 徐亦达老板 Dirichlet Process 学习 ...
- [Localization] SSD - Single Shot MultiBoxDetector
Prerequisite: VGG Ref: [Object Tracking] Localization and Detection SSD Paper: http://lib.csdn.net/a ...
- [Localization] R-CNN series for Localization and Detection
CS231n Winter 2016: Lecture 8 : Localization and Detection CS231n Winter 2017: Lecture 11: Detection ...
- 深度学习入门篇--手把手教你用 TensorFlow 训练模型
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:付越 导语 Tensorflow在更新1.0版本之后多了很多新功能,其中放出了很多用tf框架写的深度网络结构(https://git ...
- tensorflow利用预训练模型进行目标检测(一):安装tensorflow detection api
一.tensorflow安装 首先系统中已经安装了两个版本的tensorflow,一个是通过keras安装的, 一个是按照官网教程https://www.tensorflow.org/install/ ...
- 百度大脑EasyEdge端模型生成部署攻略
EasyEdge是百度基于Paddle Mobile研发的端计算模型生成平台,能够帮助深度学习开发者将自建模型快速部署到设备端.只需上传模型,最快2分种即可生成端计算模型并获取SDK.本文介绍Easy ...
- SSD: Single Shot MultiBox Detector
By Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexande ...
- SSD: Single Shot MultiBoxDetector英文论文翻译
SSD英文论文翻译 SSD: Single Shot MultiBoxDetector 2017.12.08 摘要:我们提出了一种使用单个深层神经网络检测图像中对象的方法.我们的方法,名为SSD ...
- 深度学习笔记(七)SSD 论文阅读笔记简化
一. 算法概述 本文提出的SSD算法是一种直接预测目标类别和bounding box的多目标检测算法.与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度.针 ...
随机推荐
- C#--WinForm项目主窗体设计
主窗体基本设置 大小.颜色.去边框.出现的位置 Panel控件 背景图.颜色.布局: Label标签 文本.字体.背景颜色.布局 按钮 布局.文本.字体颜色.背景色. 底部panel绑定控件边框.颜色 ...
- GoDaddy账户间域名转移PUSH以及ACCEPT接受域名过户方法
GoDaddy账户之间的域名进行过户PUSH.以及接受ACCEPT一般发生在我们有要求代购.交易域名账户之间的处理.一般的海外域名注册商账户之间是直接可以用户交易过户的,不需要经过商家允许,但是不同的 ...
- Verilog 加法器和减法器(8)-串行加法器
如果对速度要求不高,我们也可以使用串行加法器.下面通过状态机来实现串行加法器的功能. 设A=an-1an-2-a0, B=bn-1bn-2-b0,是要相加的两个无符号数,相加的和为:sum=sn-1s ...
- wxParse解析富文本内容使点击图片可以选中并实现放大缩小
wxParse解析富文本内容不多说,之前写过步骤介绍,主要是在使用过程中发现解析的富文本内容里有图片时有的可以点击放大缩小,有的点击却报错,找不到imgUrls. 经过排查发现:循环解析的富文本内容正 ...
- Java高编译低运行错误(ConcurrentHashMap.keySet)
Java高编译低运行错误(ConcurrentHashMap.keySet) 调了一天: https://www.jianshu.com/p/f4996b1ccf2f
- WIN10平板 如何修改网络IP地址为固定
右击网络,属性,更改适配器设置,然后可以找到当前的无线网络 然后依次点开即可修改IP地址
- 用 CPI 火焰图分析 Linux 性能问题
https://yq.aliyun.com/articles/465499 用 CPI 火焰图分析 Linux 性能问题 yangoliver 2018-02-11 16:05:53 浏览1076 ...
- Windows批处理 调用程序后 不等待子进程 父进程继续执行命令
从DOS过来的老鸟应该都知道批处理,这个功能在WINDOWS中仍然保留着.批处理 说白了就是把一系列DOS命令写在一个文本文件里,然后把这个文件命名为XXX.bat(WINXP以后的系统也可以命名为* ...
- python hex() oct() bin() math 内置函数
示例: print hex(20),hex(-20) #转换成十六进制 print oct(20),oct(-20) #转换成八进制 print bin(20),bin(-20) #转换成二进制 pr ...
- 实战c++中的vector系列--vector<unique_ptr<>>初始化(全部权转移)
C++11为我们提供了智能指针,给我们带来了非常多便利的地方. 那么假设把unique_ptr作为vector容器的元素呢? 形式如出一辙:vector<unique_ptr<int> ...