sjw-风评评测-定位页面元素
一、手工标准化操作流程:
1、登录系统

2、登录后的页面点击:账户设置
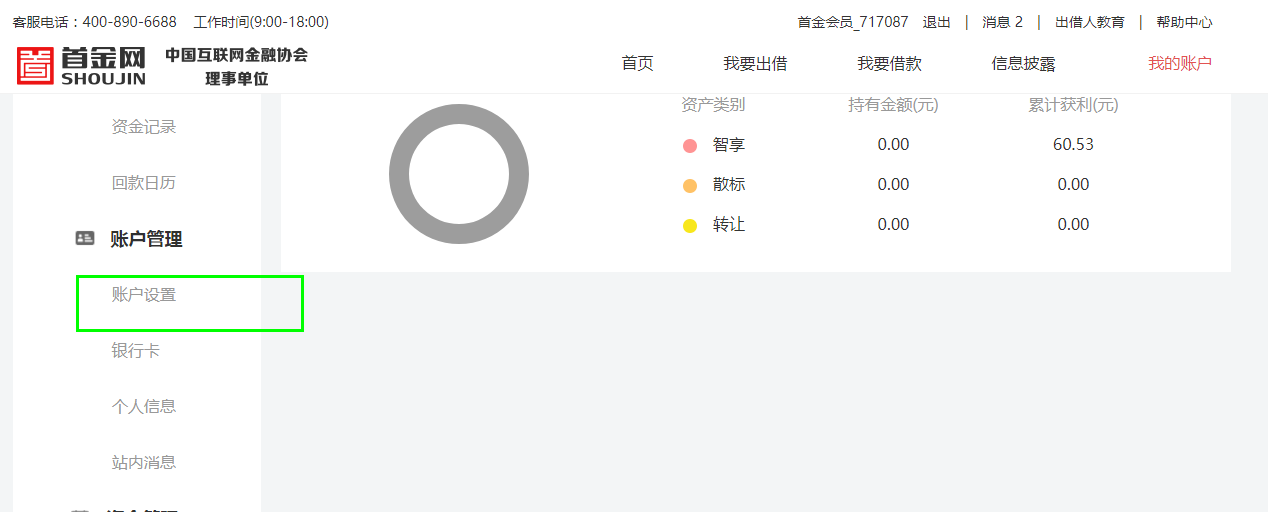
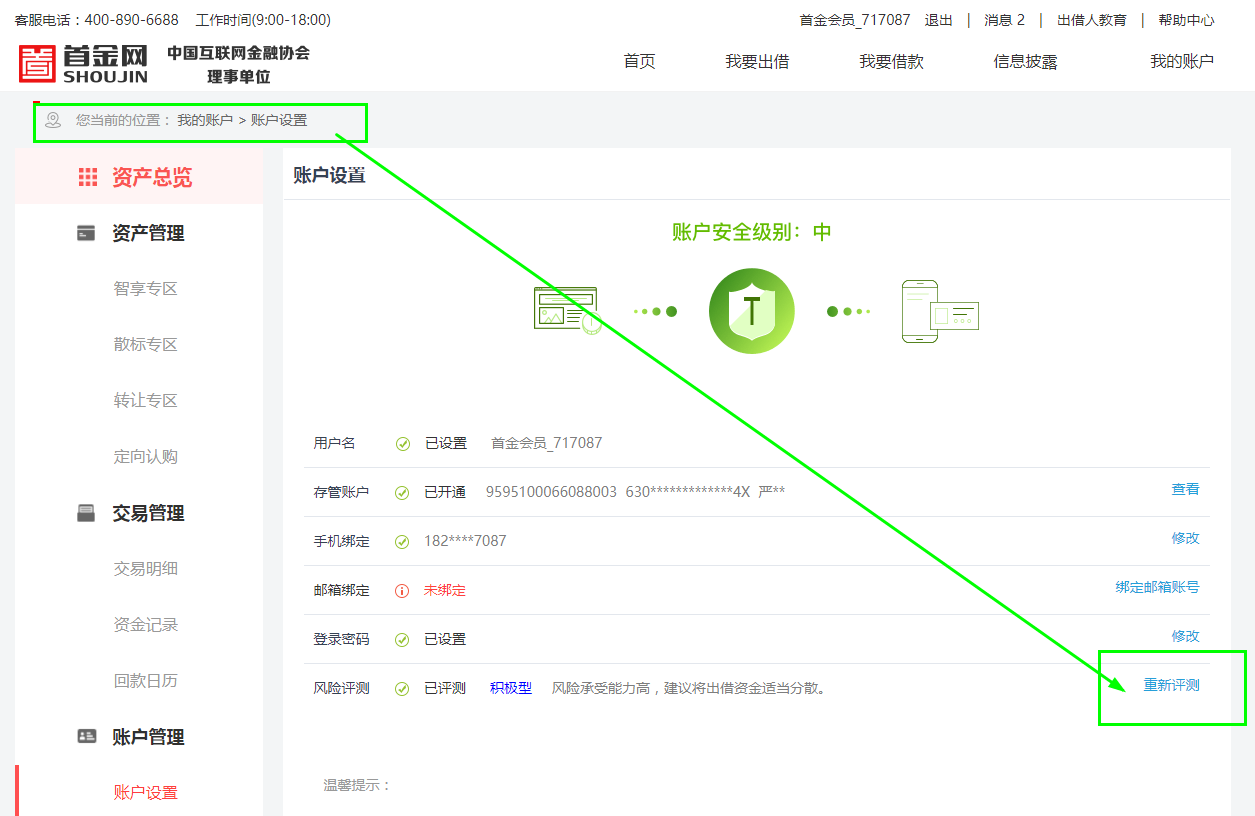
3、点击“重新评测”,进入到风险评测页面
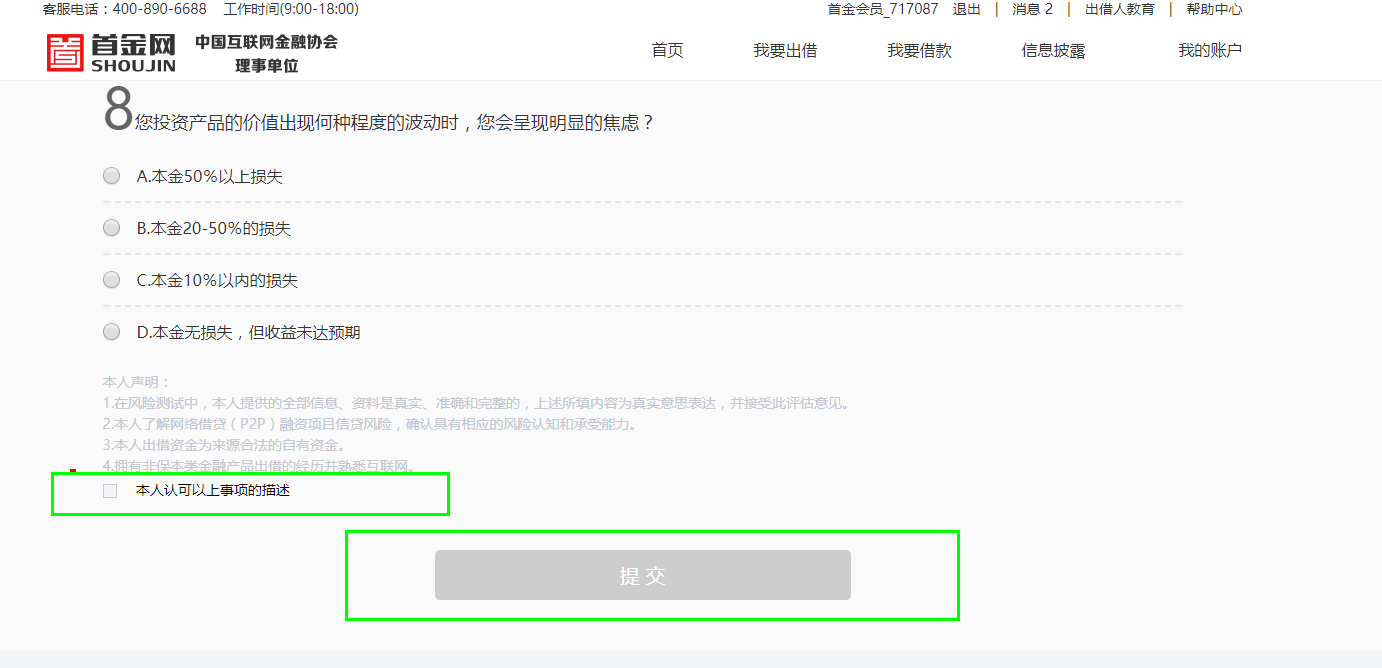
4、答完8道题

5、勾选条件checkbox
6、点击“提交”
提交后的页面
二、自动化实现
1、登录系统:略
2、登录后的页面点击:账户设置

driver.find_element_by_partial_link_text('账户设置').click()
3、点击“重新评测”,进入到风险评测页面
这一步的处理纠结时间比较长,试了很多中方法都没有定位出来。。。。。。
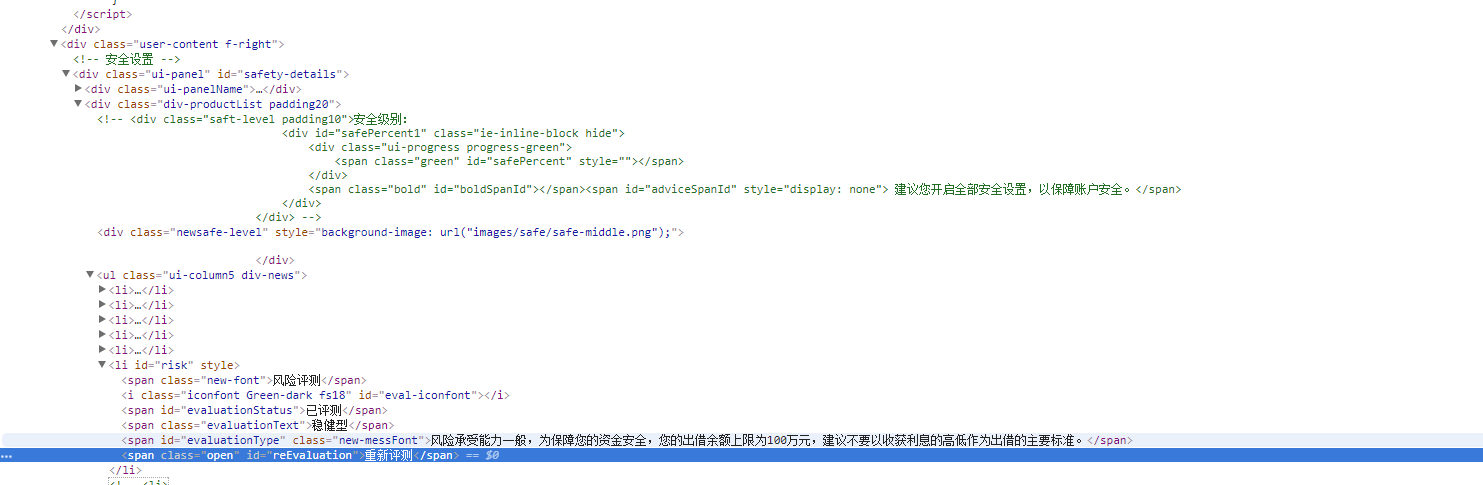
#以下定位是查找span标签有个文本(text)包含(contains)'开始评测' 的元素,该定位方法重要
driver.find_element_by_xpath("//span[contains(text(),'开始评测')]").click()
time.sleep(3)
4、答完8道题
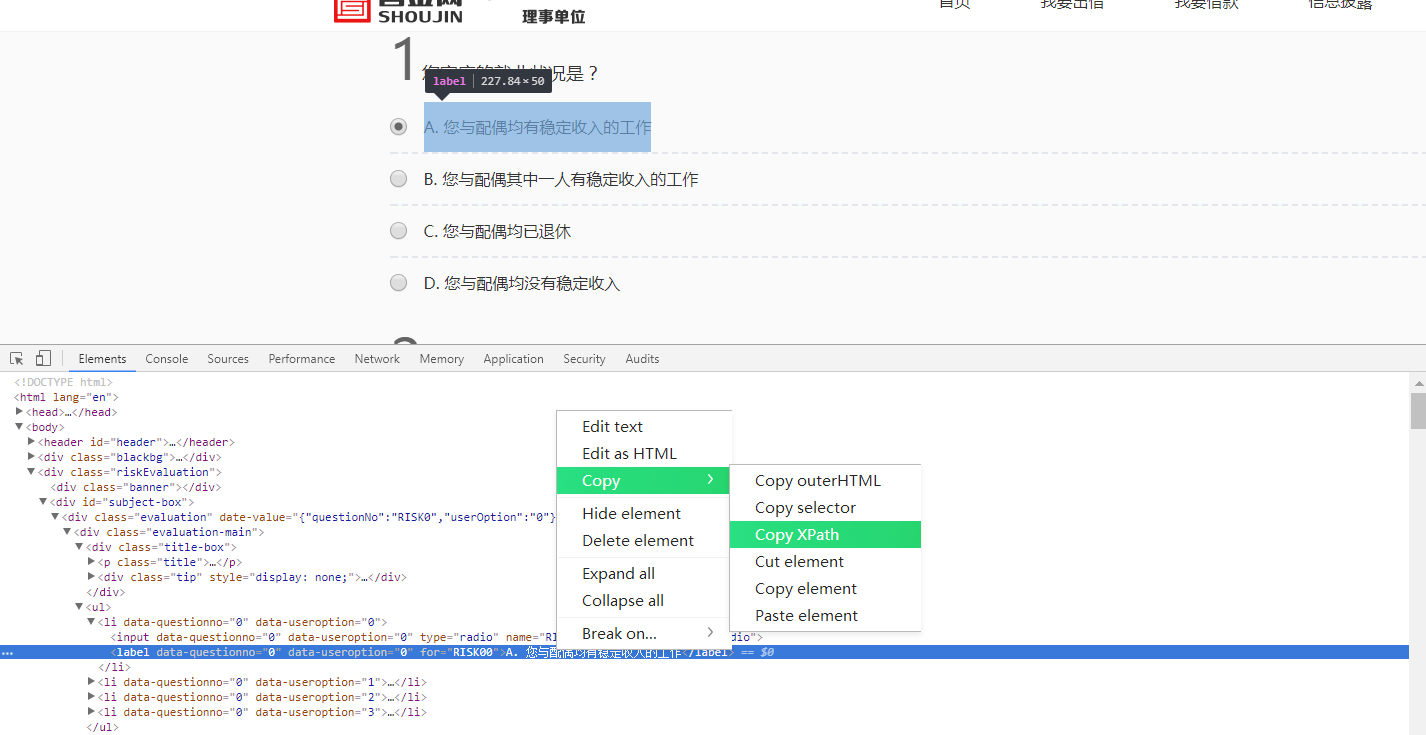
# 第1题:
driver.find_element_by_xpath('//*[@id="RISK0"]/div/ul/li[1]/label').click() #选择第1个选项
# driver.find_elements_by_xpath('//*[@id="RISK0"]/div/ul/li[2]/label').click() #选择第2个选项
# driver.find_elements_by_xpath('//*[@id="RISK0"]/div/ul/li[3]/label').click() #选择第3个选项
# driver.find_elements_by_xpath('//*[@id="RISK0"]/div/ul/li[4]/label').click() #选择第24个选项
5、勾选条件checkbox
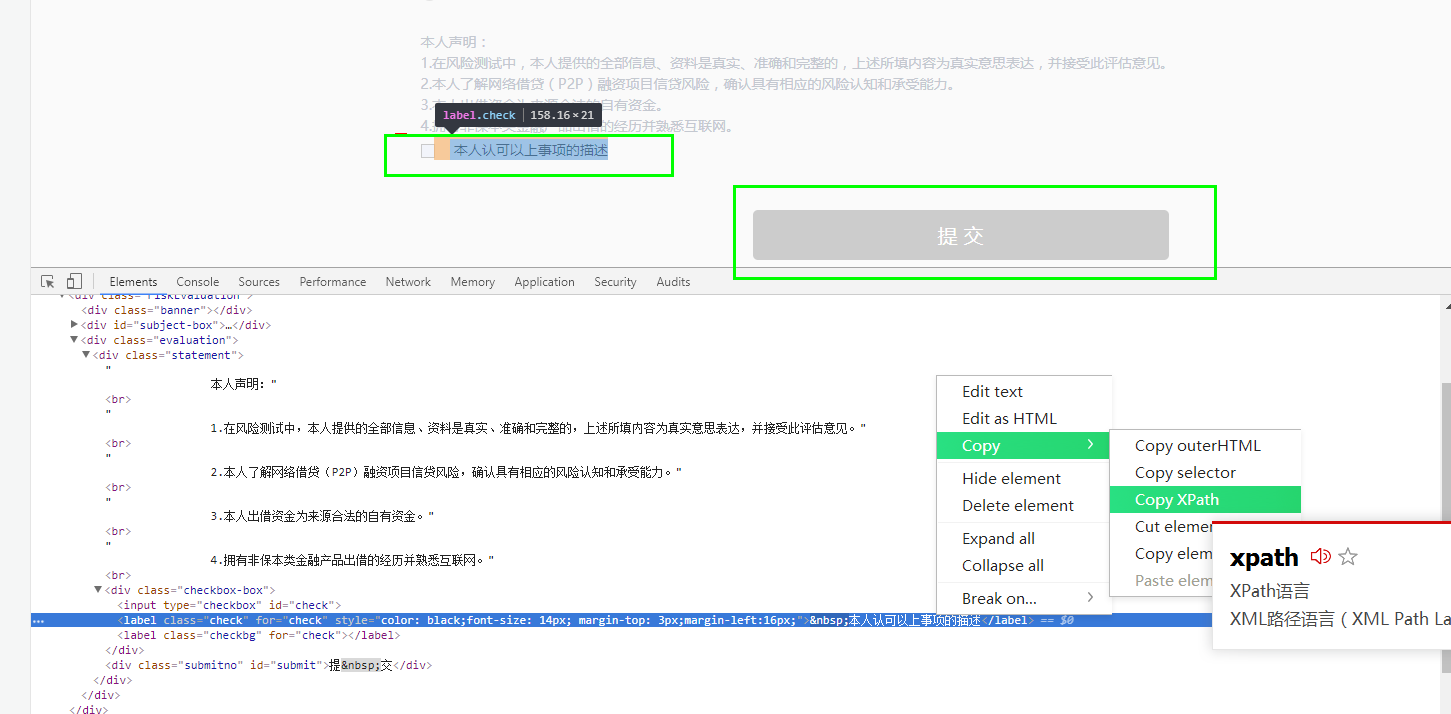
#复选框
driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[1]/label[1]').click()
#提交
driver.find_element_by_id('submit').click()
三、完整的界面自动化实现
import time
from selenium import webdriver
# import os #B
username = "" # 请替换成你的用户名 password = "123456Aa" # 请替换成你的密码 code = 121
#driver = webdriver.Chrome() # 选择Chrome浏览器或者用下面的浏览器,看心情
driver = webdriver.Firefox()
#B
driver.get('http://118.178.---.--:8081/systLogonUser/login.do') # 打首金网登录页面
#C
#driver.get('http://10.253.125.38:8081/systLogonUser/login.do') # 打首金网登录页面
# time.sleep(1) #找到用户名输入框点击获取焦点并输入信息
driver.find_element_by_id('userName').click()
driver.find_element_by_id('userName').send_keys(username) #找到密码输入框点击获取焦点并输入信息
driver.find_element_by_id('pwd').click()
driver.find_element_by_id('pwd').send_keys(password) # 找到图形验证码输入框点击获取焦点输入信息
driver.find_element_by_id('verifyCode').click()
driver.find_element_by_id('verifyCode').send_keys(code) # 找到登录按钮点击
driver.find_element_by_id('login').click()
time.sleep(1) # 找到签到点击完成签到
# driver.find_element_by_class_name('signIn').click() # driver.close() # 这些是网站中定位到的元素
# userName
# pwd
# verifyCode
# login
#定位“我的账户”左侧列表
'''
“我的账户”页面左侧导航列表页面
'''
driver.find_element_by_partial_link_text('账户设置').click()
time.sleep(1) '''
以下定位是查找span标签有个文本(text)包含(contains)'开始评测' 的元素,该定位方法重要
'''
driver.find_element_by_xpath("//span[contains(text(),'重新评测')]").click()
time.sleep(1) # 第1题:
driver.find_element_by_xpath('//*[@id="RISK0"]/div/ul/li[1]/label').click() #选择第1个选项
# driver.find_elements_by_xpath('//*[@id="RISK0"]/div/ul/li[2]/label').click() #选择第2个选项
# driver.find_elements_by_xpath('//*[@id="RISK0"]/div/ul/li[3]/label').click() #选择第3个选项
# driver.find_elements_by_xpath('//*[@id="RISK0"]/div/ul/li[4]/label').click() #选择第24个选项
# 第2题:
driver.find_element_by_xpath('//*[@id="RISK1"]/div/ul/li[1]/label').click()
# 第3题:
driver.find_element_by_xpath('//*[@id="RISK2"]/div/ul/li[1]/label').click()
# 第4题:
driver.find_element_by_xpath('//*[@id="RISK3"]/div/ul/li[1]/label').click()
# 第5题:
driver.find_element_by_xpath('//*[@id="RISK4"]/div/ul/li[1]/label').click()
# 第6题:
driver.find_element_by_xpath('//*[@id="RISK5"]/div/ul/li[1]/label').click()
# 第7题:
driver.find_element_by_xpath('//*[@id="RISK6"]/div/ul/li[1]/label').click()
# 第8题:
driver.find_element_by_xpath('//*[@id="RISK7"]/div/ul/li[1]/label').click() # time.sleep(3)
#复选框
driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[1]/label[1]').click()
#提交
driver.find_element_by_id('submit').click()
time.sleep(3)
driver.close()
四、mac下运行出现的问题

提示信息的大概意思是什么东西被遮挡了,观察后估计是浏览器显示的问题,添加如下一句代码后解决
driver.maximize_window() #将浏览器最大化显示
driver = webdriver.Firefox() driver.maximize_window() #将浏览器最大化显示 time.sleep(3)
五、优化及修改
1、selenium “could not be scrolled into view” 解决方法:让脚本sleep一下,等页面加载完就可以了
2、页面是否最大化的设置
3、“重新评测”定位的两种方式,win上#1不行,#2可行;mac上#1是可以的
'''
以下定位是查找span标签有个文本(text)包含(contains)'开始评测' 的元素,该定位方法重要
'''
# driver.find_element_by_xpath("//span[contains(text(),'重新评测')]").click()#1
driver.find_element_by_id('reEvaluation').click()#2
time.sleep(3)
sjw-风评评测-定位页面元素的更多相关文章
- selenium定位页面元素的一件趣事
PS:本博客selenium分类不会记载selenium打开浏览器,定位元素,操作页面元素,切换到iframe,处理alter.confirm和prompt对话框这些在网上随处可见的信息:本博客此分类 ...
- 定位页面元素之xpath详解以及定位不到测试元素的常见问题
一.定位元素的方法 id:首选的识别属性,W3C标准推荐为页面每一个元素设置一个独一无二的ID属性, 如果没有且很难找到唯一属性,解决方法:(1)找开发把id或者name加上.如果不行,解决思路可以是 ...
- 使用CSS选择器定位页面元素
摘录:http://blog.csdn.net/defectfinder/article/details/51734690 CSS选择器也是一个非常好用的定位元素的方法,甚至比Xpath强大.在自动化 ...
- Selenium 定位页面元素 以及总结页面常见的元素 以及总结用户常见的操作
1. Selenium常见的定位页面元素 2.页面常见的元素 3. 用户常见的操作 1. Selenium常见的定位页面元素 driver.findElement(By.id());driver.fi ...
- webdriver定位页面元素时使用set_page_load_time()和JavaScript停止页面加载
webdriver定位页面元素时使用set_page_load_time()和JavaScript停止页面加载 原文:https://my.oschina.net/u/2344787/blog/400 ...
- selenium第三课(selenium八种定位页面元素方法)
selenium webdriver进行元素定位时,通过seleniumAPI官方介绍,获取页面元素的方式一共有以下八种方式,现按照常用→不常用的顺序分别介绍一下. 官方api地址:https://s ...
- 关于appium操作真机打开app之后无法定位页面元素的问题的解决办法
appium操作真机打开app后无法定位页面元素:例如微信或者支付宝支付时,手机的安全控件会对支付环境进行保护,会断掉当前appium与真机的链接,导致连接失败,无法定位到页面元素,在做ui自动化之前 ...
- selenium webdriver学习(四)------------定位页面元素(转)
selenium webdriver学习(四)------------定位页面元素 博客分类: Selenium-webdriver seleniumwebdriver定位页面元素findElemen ...
- Python+Selenium自动化-定位页面元素的八种方法
Python+Selenium自动化-定位页面元素的八种方法 本篇文字主要学习selenium定位页面元素的集中方法,以百度首页为例子. 0.元素定位方法主要有: id定位:find_elemen ...
随机推荐
- Flask web开发之路一
之前学过一段时间的flask,感觉还是挺好用的,自己的专利挖掘项目也想这个web框架来搭建,于是重新开始基础学习 环境:win10,python3.6,pycharm2017,虚拟环境virtuale ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验【中英】
[吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第一周测验[中英] 第一周测验 - 深度学习简介 和“AI是新电力”相类似的说法是什么? [ ]AI为我们的家庭和办公室的个人设备供电 ...
- ifnull与nvl
mysql 用 ifnull ,oracle没有ifnull 但是有相应的替换函数 nvl NVL(eExpression1, eExpression2)
- ELK之使用filebeat收集java运行日志
安装filebeat修改配置文件/etc/filebeat/filebeat.yml filebeat.prospectors: - type: log enabled: true #日志路径 pat ...
- Caused by: java.sql.BatchUpdateException
Caused by: java.sql.BatchUpdateException: Table (%s) has been dropped, altered or renamed.解决方法重启项目
- 2017年蓝桥杯省赛A组c++第5题(递归算法填空)
/* 由 A,B,C 这3个字母就可以组成许多串. 比如:"A","AB","ABC","ABA","AACB ...
- [cloud][sdn] openstack openflow opendaylight openvswitch
https://www.quora.com/What-is-the-relation-between-OpenStack-OpenDaylight-OpenFlow-and-Open-vSwitch- ...
- 中位数&贪心
谁能想到基本算法就这么难呢?我想去冲省选,但是迟迟在这些地方 花时间 算是提升自己的思维算了. 这道题呢 答案其实很简单每个数在a的位置和在b的位置之差的累加/2即是答案为什么呢?考虑当前数字 要向后 ...
- CABasicAnimation 划线动画
CGFloat animateDuration = ; UIBezierPath *bezierPath = [[UIBezierPath alloc] init]; CGPoint centerFr ...
- C++生成静态库
//StaticMath.h #include <iostream> class StaticMath { public: //StaticMath(void); //~StaticMat ...