【Hadoop学习之三】Hadoop全分布式安装
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop3.1.1
全分布式就是集群,注意配置主机名。
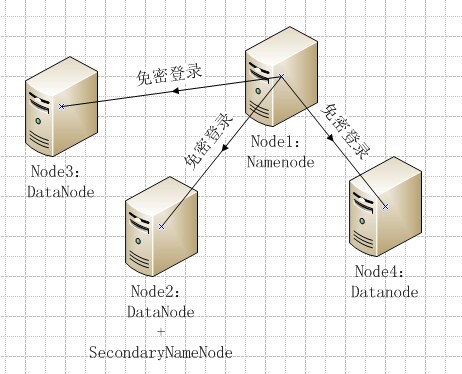
一、平台和软件
1、安装JDK和免密登录参考:【Hadoop学习之二】Hadoop伪分布式安装
2、设置环境变量
[root@node1 /]# vi /etc/profile
[root@node1 /]# source /etc/profile

#注意pwd 是打印当前路径 意思是要拷贝到远程主机统一目录下
[root@node1 etc]# scp /etc/profile node2:`pwd`
profile % .9KB/s :
[root@node1 etc]# scp /etc/profile node3:`pwd`
profile % .9KB/s :
[root@node1 etc]# scp /etc/profile node4:`pwd`
profile % .9KB/s :
3、node1-node4设置主机名 后重启
[root@node1 /]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.230.11 node1
192.168.230.12 node2
192.168.230.13 node3
192.168.230.14 node4
分发到另外三个节点
[root@node1 etc]# scp /etc/hosts node2:`pwd`
hosts % .2KB/s :
[root@node1 etc]# scp /etc/hosts node3:`pwd`
hosts % .2KB/s :
[root@node1 etc]# scp /etc/hosts node4:`pwd`
hosts % .2KB/s :
第一次配置hosts 需要重启生效
[root@node1 /]# reboot
二、配置
1、修改/usr/local/hadoop-3.1.1/etc/hadoop/hadoop-env.sh 设置JAVA环境变量、角色用户
在最后添加如下设置:
export JAVA_HOME=/usr/local/jdk1..0_65
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
2、修改/usr/local/hadoop-3.1.1/etc/hadoop/core-site.xml 配置主节点相关信息
(1)fs.defaultFS 主节点通讯信息 (hadoop3默认端口改为9820)
(2)hadoop.tmp.dir 设置namenode元数据和datanode block数据的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoopfull</value>
</property>
</configuration>
3、修改/usr/local/hadoop-3.1.1/etc/hadoop/hdfs-site.xml 配置从节点相关信息
(1)dfs.replication 副本数
(2)dfs.namenode.secondary.http-address 二级namenode (hadoop默认端口改为9868)
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
4、修改workers(hadoop2.X叫slave)配置从节点(DATANODE)信息
配置:
node2
node3
node4
5、分发hadoop到node2、node3、node4 依赖免密登录 注意拷贝时的目录 (注意:jdk也可以采用这种方式分发)
[root@node2 local]# scp -r /usr/local/hadoop-3.1. node2:`pwd`
[root@node2 local]# scp -r /usr/local/hadoop-3.1. node3:`pwd`
[root@node2 local]# scp -r /usr/local/hadoop-3.1. node4:`pwd`
三、启动
首次启动,需要主节点进行格式化
[root@node1 /]# hdfs namenode -format
启动:node1作为namenode主节点,要在主节点上启动
[root@node1 /]# start-dfs.sh
关闭:
[root@node1 /]# stop-dfs.sh
可以使用jps命令,在node2、node3、node4上查看启动情况
【Hadoop学习之三】Hadoop全分布式安装的更多相关文章
- Centos 6.5 hadoop 2.2.0 全分布式安装
hadoop 2.2.0 cluster setup 环境: 操作系统:Centos 6.5 jdk:jdk1.7.0_51 hadoop版本:2.2.0 hostname ip master ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- centos 7下Hadoop 2.7.2 伪分布式安装
centos 7 下Hadoop 2.7.2 伪分布式安装,安装jdk,免密匙登录,配置mapreduce,配置YARN.详细步骤如下: 1.0 安装JDK 1.1 查看是否安装了openjdk [l ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- [大数据] hadoop全分布式安装
一.准备工作 在伪分布式的搭建基础上修改配置,搭建全分布式hadoop环境,伪分布式安装参照 hadoop伪分布式安装. 首先准备4台虚拟机,信息如下: 192.168.1.11 namenode1 ...
- hadoop学习笔记——基础知识及安装
1.核心 HDFS 分布式文件系统 主从结构,一个namenoe和多个datanode, 分别对应独立的物理机器 1) NameNode是主服务器,管理文件系统的命名空间和客户端对文件的访问操 ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- Hadoop开发第4期---分布式安装
一.复制虚拟机 由于Hadoop的集群安装需要多台机器,由于条件有限,我是用虚拟机通过克隆来模拟多台机器,克隆方式如下图所示
随机推荐
- Android activity 周期图和fragment周期图
与Activity生命周期的对比 Fragment的生命周 onCreateView():每次创建.绘制该Fragment的View组件时回调该方法,Fragment将会显示该方法返回的View组件. ...
- AsyncStorage和Promise配合使用
代码: AsyncStorage封装 import {AsyncStorage} from "react-native"; class DeviceStorage { //保存数据 ...
- dos2unix命令
dos2unix命令用来将DOS格式的文本文件转换成UNIX格式的(DOS/MAC to UNIX text file format converter).DOS下的文本文件是以\r\n作为断行标志的 ...
- jmeter报错:响应数据HTTP Status 500 & 后台日志Typed variable declaration : Object constructor
今天在测试文件下载接口,发现在测试单个文件下载1次时,文件成功下载.但是在测试单个文件并发下载50次时,Jmeter报错了,后台服务器tomcat竟然没有发现报错信息. Jmeter响应信息报错: H ...
- HTML中--定义header和footer高度中间自适应
<html> <head> <meta charset="utf-8" /> <title></title> <s ...
- vue-父组件向子组件传递方法
1.父组件向子组件传递方法,使用的是事件绑定机制 v-on:传递给子组件的方法名=“父组件中的方法”
- Spark中的partition和block的关系
hdfs中的block是分布式存储的最小单元,类似于盛放文件的盒子,一个文件可能要占多个盒子,但一个盒子里的内容只可能来自同一份文件.假设block设置为128M,你的文件是250M,那么这份文件占3 ...
- Django 框架 数据库操作
数据库与ORM 1 django默认支持sqlite,mysql, oracle,postgresql数据库. <1> sqlite django默认使用sqlite的数据库,默认 ...
- 23-Python3 File
''' file(文件)方法 ''' #open()对象 pass #file对象 ##file.close():关闭文件,关闭后不能再进行读写操作 fo1 = open('/Users/ligaij ...
- [LeetCode] 153. Find Minimum in Rotated Sorted Array_Medium tag: Binary Search
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand. (i.e. ...