03_Storm编程上手-wordcount
1. Storm编程模型概要
消息源spout, 继承BaseRichSpout类 或 实现IRichSpout接口
1)BaseRichSpout类相对比较简单,需要覆写的方法较少,满足基本业务需求
2)IRichSpout接口,需要实现较多的框架定义好的抽象方法,部分方法和BaseRichSpout重叠,通常用于比较复杂的业务数据接入需求
重要方法
open方法: 初始化动作(传入参数,传入上下文),是spout第一个执行的方法,主类中的拓扑配置实例conf会将相关参数作为实参传入给open
nextTuple方法: 数据接入,消息tuple发射 (spout中最重要的方法)
ack方法:传入参数是object,本质是id,标识唯一一个tuple, 实现该tuple被spout成功处理后的逻辑,storm消息保证的API接口
fail方法:与ack方法对应,实现tuple处理失败后的逻辑, storm消息保证的API接口
declareOutputFields方法:声明输出字段,storm中的每个tuple都要求设置输出字段
处理单元bolt: 继承BaseBasicBolt类,或者实现IRichBolt接口
重要方法
*prepare方法:worker初始化,传递参数,声明上下文
*execute方法:接收1个tuple, 实现bolt处理逻辑,发射新tuple(最重要)
*clearup方法:worker关闭前调用,资源释放等,但不能保证该方法一定会被调用(worker进程出现问题等情况)
*declareOutputFields方法:声明输出tuple的每个字段,storm中的每个tuple都要求设置输出字段
2. wordcount代码架构
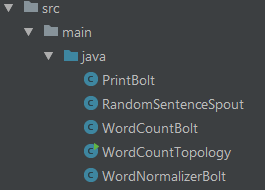
从拓扑的角度来看各个类间的关系

各个类主要功能
1. spout中随机发送内置的语句作为消息源
2. 第一组bolt进行语句切分,分离出单词,然后发送给下游bolt
3. 第二组bolt,基于字段分组策略,订阅(接收)切分好的单词,完成单词统计并将结果发送给下游
4. 最后1个bolt, 将结果打印到console
3. RandomSentenceSpout
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
/**
*
* @Author: shayzhang
* @Email: shayzhang@sina.com
* @Blog: cn.blogs.com/shay-zhangjin
* @Describe: select 1 random sentence and send to next-level bolt using field streaming groups
*
*/
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector spcollector; //for emit tuple
Random random; //spout initialize, spout执行的第一个方法,主要是从conf自动传入spout发送数据的SpoutOutputCollector
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
spcollector = spoutOutputCollector;
random = new Random();
}
//generate tuple and emit
public void nextTuple() {
//每2秒发送一次tuple
Utils.sleep(2000);
String[] sentences = new String[]{
"And if the golden sun",
"four score and seven years ago",
"storm hadoop hbase spark",
"storm is a real-time processing frame-work",
"you make my night bright"
};
// select random sentence
String msg = sentences[random.nextInt(sentences.length)];
// emit tuple, doesn't assign message id
spcollector.emit(new Values(msg.trim().toLowerCase()) );
// ack tuple, successfully sent
} //每个tuple都要说明字段
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence") );
}
}
4. WordNormalizserBolt
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.Map; /**
*
* @author: shayzhang
* @email: shayzhang@sina.com
* @blog: cn.blogs.com/shay-zhangjin
* @description: split sentence into words and emit
*
*/
public class WordNormalizerBolt implements IRichBolt {
private OutputCollector wncollector; //bolt执行的第一个方法,主类中conf对象,将相关数据推送过来,重点是获取Bolt发送数据使用的OutputCollector
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
wncollector = outputCollector;
} public void execute(Tuple tuple) {
//获取整个句子
String sentence = tuple.getString(0);
//分离出单词
String words[] = sentence.split(" ");
//发送每个单词
for(String word: words){
wncollector.emit(new Values(word));
wncollector.ack(tuple);
}
}
//Bolt退出会执行,但不能保证cleanup方法一定会被执行到(节点故障等)
public void cleanup() { }
//字段说明
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word")); //当下游bolt通过fieldsGrouping方式获取数据时尤为重要,要保障上下游使用的Fields能够对的上
} public Map<String, Object> getComponentConfiguration() {
return null;
}
}
5. WordCountBolt
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map; /**
*
* @author: shayzhang
* @email: shayzhang@sina.com
* @blog: cn.blogs.com/shay-zhangjin
* @description: count word number, emit top N
*
*/
public class WordCountBolt implements IRichBolt{
OutputCollector collector; //for emit
Map<String,Integer> counters; //for word count //init bolt, bolt执行的第一个方法,主类中的config对象自动进行参数传递
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
collector = outputCollector;
counters = new HashMap<String, Integer>(); } //统计每个单词的次数,并排序
public void execute(Tuple tuple) {
String word = tuple.getString(0); //处理收到的每一个word
if ( !counters.containsKey(word)){
counters.put(word,1);
}else{
counters.put(word, counters.get(word)+1);
} //实时输出 <word, count>
Integer length = counters.keySet().size();
Integer count = 0; for(String key:counters.keySet()){
word = "[" + new String(key) + ": " + String.valueOf(counters.get(key)) + "]";
collector.emit(new Values(word));
collector.ack(tuple);
count++;
if(count==length){
break;
} }//execute }//execute public void cleanup() { } public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("wordcount"));
} public Map<String, Object> getComponentConfiguration() {
return null;
}
}
6. PrintBolt
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import java.util.Map; public class PrintBolt extends BaseBasicBolt{ OutputCollector collector; public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
collector = outputCollector;
} public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
try {
String msg = tuple.getString(0);
if (msg != null) {
System.out.println(msg);
}
} catch (Exception e) {
e.printStackTrace();
}
} public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("result"));
}
}
7. 主类:构建拓扑,根据是否传入参数决定运行本地模式、集群模式
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.utils.Utils; public class WordCountTopology { public static void main(String args[]) throws AlreadyAliveException, InvalidTopologyException {
//Topology配置
Config config = new Config(); //Topology构造器
TopologyBuilder builder = new TopologyBuilder(); //使用builder构建Topology
//spout, 2个executor
builder.setSpout("RandomSentence", new RandomSentenceSpout(), 2); //bolt, 2个executor, 从id为RandomSentence的spout接收tuple, shuffle方式
builder.setBolt("WordNormalizer", new WordNormalizerBolt(), 2).shuffleGrouping("RandomSentence"); //从id为“RandomSentence”的spout获取数据 //bolt, 2个executor,从id为wordNormalizer的bolt接收tuple, fields方式: 根据‘word’字段, 进行单词接收
builder.setBolt("wordcount", new WordCountBolt(), 2).fieldsGrouping("WordNormalizer", new Fields("word")); //从id为WordNormalizser的bolt获取数据,并且按照word域进行分发 //bolt, 1个executor, 收集所有结果并打印, global方式接收所有id为wordcount的bolt发出的信息
builder.setBolt("print", new PrintBolt(), 1).shuffleGrouping("wordcount"); //从id为wordcount的bolt获取数据 //设置debug, true则打印节点间交换的所有信息
config.setDebug(false); //通过是否有参数,来控制启动本地模式,集群模式
if(args!=null && args.length>0){
//有提交参数,执行集群模式
config.setNumWorkers(1); //1个worker进程
try {
//提交拓扑到storm集群, 拓扑名通过提交参数给定(args[0])
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}else{
//无提交参数,执行本地模式,调测用
//本地模式,通过LocalCluster实例提交拓扑任务
config.setMaxTaskParallelism(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WC_Local", config, builder.createTopology()); //运行5分钟后,kill该topology任务
Utils.sleep(300000);
cluster.killTopology("WC_Local");
cluster.shutdown(); } }//main
}//WordCountTopology
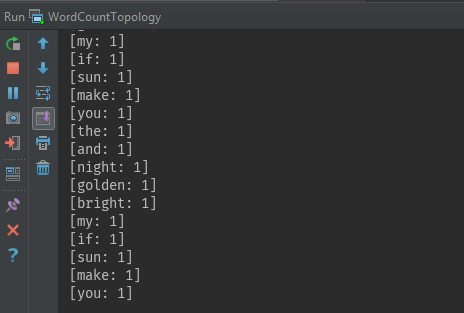
8. 本地模式运行
在IDEA中选择主类,直接运行即可, 从IDE终端可以看到代码是否正常运行
03_Storm编程上手-wordcount的更多相关文章
- 第三次作业-结对编程(wordcount)
GIT地址 https://github.com/gentlemanzq/WordCount.git GIT用户名 gentlemanzq 结对伙伴博客地址 https://home.cnblogs ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- 04_Storm编程上手_WordCount集群模式运行
1. 要解决的问题:代码打包 前一篇的代码,在IDEA中通过maven工程创建,通过IDEA完成代码打包 1)File -> Project Structure 2) 选择Artifacts, ...
- Spark编程环境搭建及WordCount实例
基于Intellij IDEA搭建Spark开发环境搭建 基于Intellij IDEA搭建Spark开发环境搭——参考文档 ● 参考文档http://spark.apache.org/docs/la ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 【Visual C++】游戏编程学习笔记之一:五毛钱特效之透明和半透明处理
本系列文章由@二货梦想家张程 所写,转载请注明出处. 本文章链接:http://blog.csdn.net/terence1212/article/details/44163799 作者:ZeeCod ...
- 实训任务04 MapReduce编程入门
实训任务04 MapReduce编程入门 1.实训1:画图mapReduce处理过程 使用有短句“A friend in need is a friend in deed”,画出使用MapReduce ...
- 2.4 Scala函数式编程
一.函数定义与使用 1.函数的定义 2.匿名函数 举例: Scala自动推断变量类型,不用声明: 一个下划线只能表示这一个参数的一次出现 二.高阶函数 定义:函数定义的括号里仍然是个函数的函数,叫作高 ...
- Hive实现WordCount详解
一.WordCount原理 初学MapReduce编程,WordCount作为入门经典,类似于初学编程时的Hello World.WordCount的逻辑就是给定一个/多个文本,统计出文本中每次单词/ ...
随机推荐
- LINUX内核分析20133201
实验:通过汇编一个简单的C程序,分析汇编代码理解计算机是如何工作的 学号:20133201 姓名:李冬辉 注: 原创作品转载请注明出处 +<Linux内核分析>MOOC课程http://m ...
- Mybatis框架学习总结-Mybatis框架搭建和使用
Mybatis介绍 Mybatis是一个支持普通SQL查询,存储过程,和高级映射的优秀持久层框架.Mybatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.Mybatis可以使 ...
- MySQL整理(二)
一.MySQL操作表的约束 MySQL提供了一系列机制来检查数据库表中的数据是否满足规定条件,以此来保证数据库表中数据的准确性和一致性,这种机制就是约束. (1)设置非空约束(NOT NULL),唯一 ...
- 20165324 Java实验四 Android程序设计
20165324 Java实验四 Android程序设计 一.实验报告封面 课程:Java程序设计 班级:1653班 姓名:何春江 学号:20165324 指导教师:娄嘉鹏 实验日期:2018年5月1 ...
- SQL Server 数据分页查询
最近学习了一下SQL的分页查询,总结了以下几种方法. 首先建立了一个表,随意插入的一些测试数据,表结构和数据如下图: 现在假设我们要做的是每页5条数据,而现在我们要取第三页的数据.(数据太少,就每页5 ...
- PKU 1094 Sorting It All Out(拓扑排序)
题目大意:就是给定一组字母的大小关系判断他们是否能组成唯一的拓扑序列. 是典型的拓扑排序,但输出格式上确有三种形式: 1.该字母序列有序,并依次输出: 2.判断该序列是否唯一: 3.该序列字母次序之间 ...
- Tornado 自定义Form,session实现方法
一. 自定义Tornado 验证模块 我们知道,平时在登陆某个网站或软件时,网站对于你输入的内容是有要求的,并且会对你输入的错误内容有提示,对于Django这种大而全的web框架,是提供了form表单 ...
- WLAN QOS
1. 理解WLAN QOS 1.1 WLAN QOS简介 802.11的WLAN网络为用户提供了公平竞争无线资源的无线接入服务,但不同的应用需求对于网络的要求是不同的,而原始802.11网 ...
- SCP命令只能单项拷贝,另一个方向“RSA host key for 172.16.103.176 has changed and you have requested strict checki Host key verification failed. lost connection”问题
[dinghuaneng@95 move_data]$ scp * dinghuaneng@172.16.103.176:/home/dinghuaneng@@@@@@@@@@@@@@@@@@@@@@ ...
- CCTableView
今天用到TableView, 我就来记录一下....这些都是在网上找到了资料 //首先 继承 : public cocos2d::extension::CCTableViewDelegate,publ ...