【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 16—Recommender Systems 推荐系统
Lecture 16 Recommender Systems 推荐系统
16.1 问题形式化 Problem Formulation
在机器学习领域,对于一些问题存在一些算法, 能试图自动地替你学习到一组优良的特征。通过推荐系统(recommender systems),将领略一小部分特征学习的思想。
假使有 5 部电影,3部爱情片、2部动作片。 4 个用户为其中的部分电影打了分。现在希望构建一个算法,预测每个人可能给没看过的电影打多少分,以此作为推荐的依据。
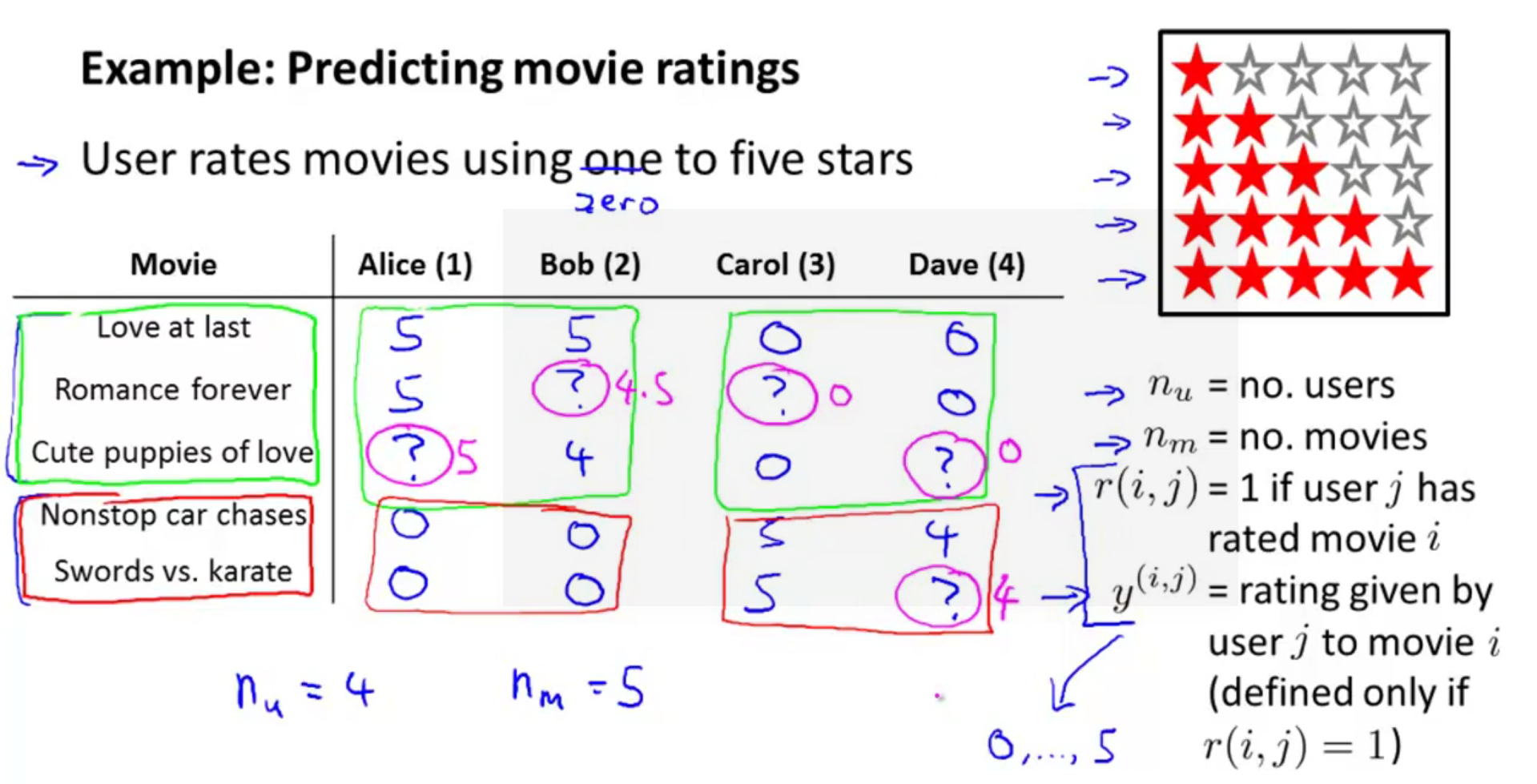
下面引入一些标记:
nu 代表用户的数量
nm 代表电影的数量
r(i, j) 如果用户 j 给电影 i 评过分则 r(i, j) = 1
y(i,j) 代表用户 j 给电影 i 的评分 (注:这里 i 和 j 不要搞反)
mj 代表用户 j 评过分的电影的总数
16.2 基于内容的推荐系统 Content Based Recommendations
1 定义
在一个基于内容的推荐系统算法中,假设对于我们希望推荐的东西有一些数据,是这些东西的特征。
现在假设每部电影都有两个特征, x1 代表电影的浪漫程度,x2 代表电影的动作程度。
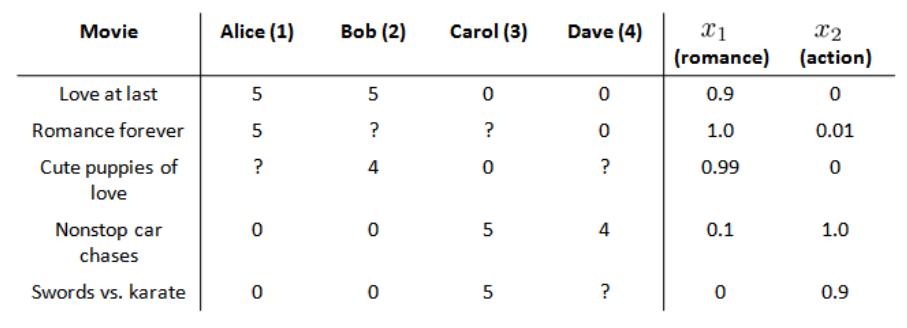
则每部电影都有一个特征向量,如 x(1)是第一部电影的特征向量,为[0.9 0]。
下面我们采用线性回归模型,针对每一个用户都训练一个线性回归模型,如θ(1) 是第一个用户的模型的参数。 于是有:
θ(j) 用户 j 的参数向量
x(i) 电影 i 的特征向量
对于用户 j 和电影 i,我们预测其评分为:(θ(j))Tx(i)
2 代价函数
针对用户 j,该线性回归模型的代价为预测误差的平方和,加上正则化项:
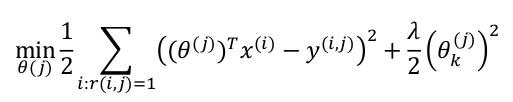
其中 i: r(i, j) 表示我们只计算那些用户 j 评过分的电影。在一般的线性回归模型中,误差项和正则项应该都是乘以1/2m,在这里我们将m去掉,且不对方差项θ0进行正则化处理。
上面的代价函数只是针对一个用户的,为了学习所有用户,我们将所有用户的代价函数求和: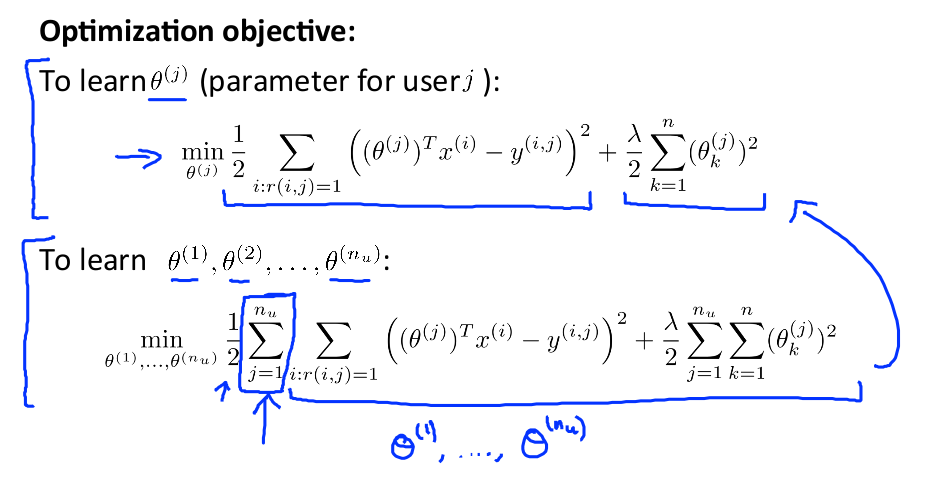
如果我们要用梯度下降法来求解最优解,我们计算代价函数的偏导数后得到梯度下降的更新公式为: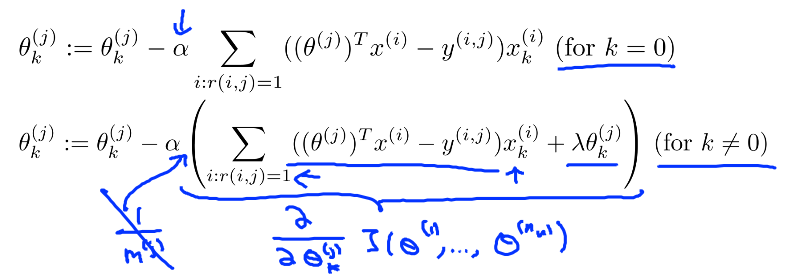
16.3 协同过滤 Collaborative Filtering
在之前的基于内容的推荐系统中,使用电影的特征,训练出了每一个用户的参数。相反地,如果拥有用户的参数,可以学习得出电影的特征。
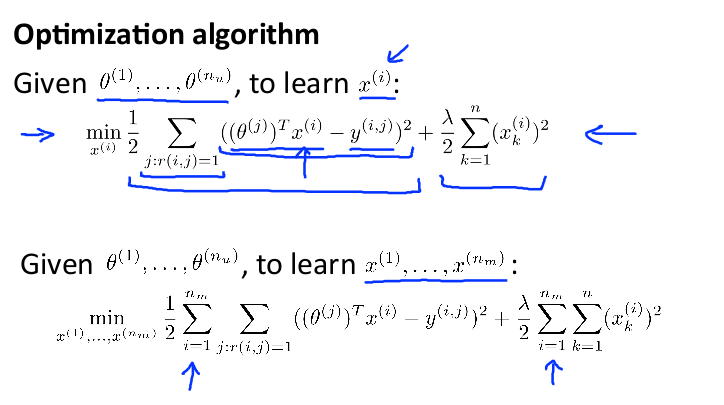
但是如果既没有用户的参数,也没有电影的特征,这两种方法都不可行了。可以使用协同过滤算法,同时学习这两者。

优化目标便改为同时针对x和θ进行。是一个:预测 θ,再反过来预测 x, 再预测 θ,再预测 x 的迭代过程。
16.4 协同过滤算法 Collaborative Filtering Algorithm
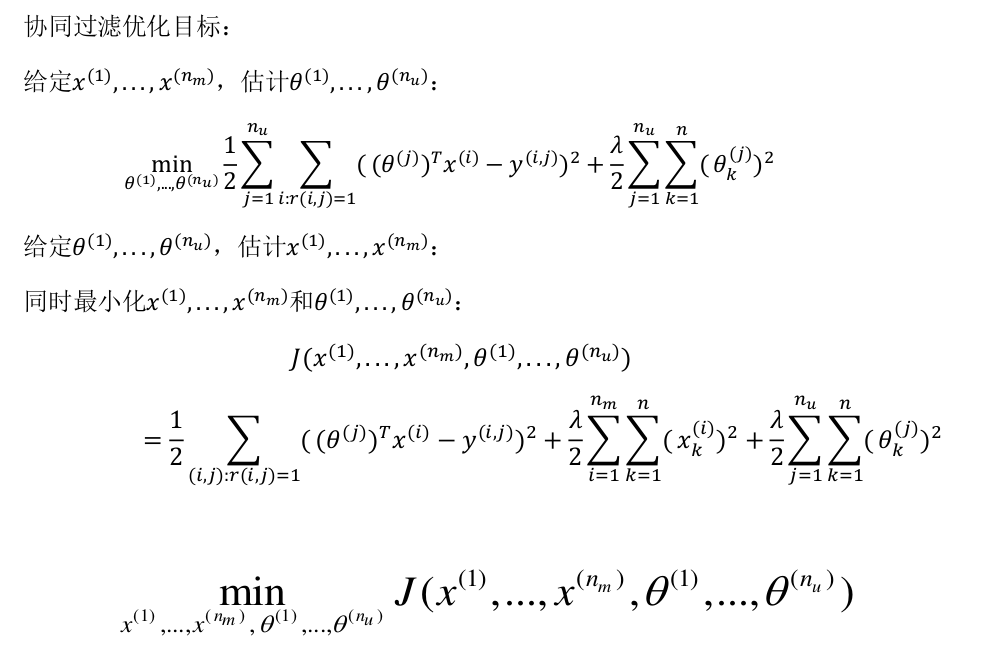
协同过滤的代价函数定义为:

对代价函数求偏导数:
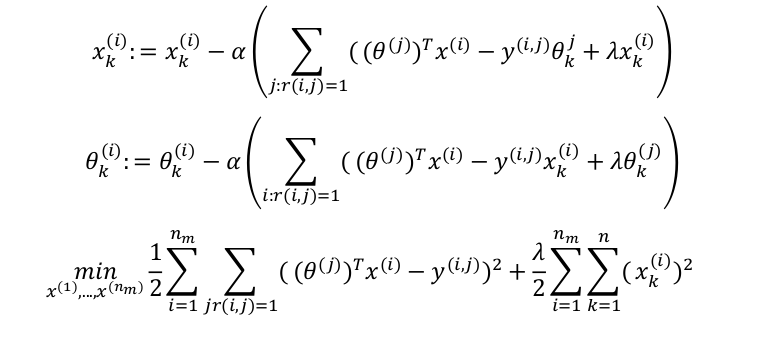
(注:在协同过滤从算法中,通常不使用方差项,如果需要的话,算法会自动学得。)
协同过滤算法使用步骤如下:

1. 初始 x 和 θ 为一些随机小值
2. 使用梯度下降算法最小化代价函数 J
3. 在训练完算法后,通过计算 θTx 预测用户 j 给电影 i 的评分
通过这个学习过程获得的特征矩阵包含了有关电影的重要数据,这些数据不总是人能读懂的,但是可以用这些数据作为给用户推荐电影的依据。
总结:
16.5 向量化:低秩矩阵分解 Vectorization_ Low Rank Matrix Factorization
协同过滤算法的向量化实现
举例:
1)给出一件产品,能否找到与之相关的其它产品。
2)一位用户最近看上一件产品,有没有其它相关的产品可以推荐给他。
现在有5部电影,4位用户,矩阵 Y 就是一个 5 行 4 列的矩阵,存储每个用户对每个电影的评分数据:
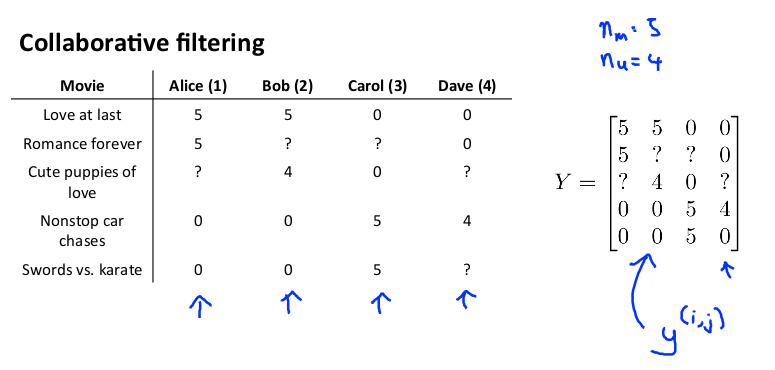
通过使用 θ 和 x 计算,可以预测出每个用户对每个电影打的分数:

现在将所有 x 都集中在一个大的矩阵X中,每一部电影是一行;
将所有 θ 集中在一个大的Θ中,每个用户是一行。
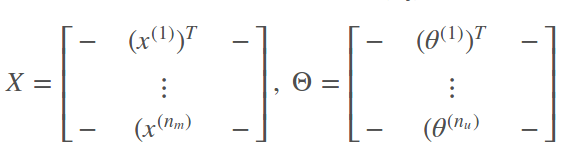
则有:

因为矩阵X乘Θ的转置,在数学上具有低秩属性。因此这个算法也被称为低秩矩阵分解 low rank matrix factorization。
现在已经学习到了特征参数向量,那么可以使用这些向量做一些别的事情,比如度量两部电影之间的相似性。例如,如果一位用户正在观看电影 x(i) ,可以根据两部电影的特征向量之间的距离 ∥x(i) − x(j)∥,寻找另一部相似电影 x(j):

16.6 推行工作上的细节:均值归一化 Mean Normalization
现在新增一个用户 Eve,她没有为任何电影评分,那么我们以什么为依据为 Eve 推荐电影呢?
如果根据之前的模型,因为她没有打分,代价函数第一项为0。算法目标变为最小化最后一项,最后得到 θ(5) 中的元素都是0。现在拿着 θ(5) 预测出的瓶分都是0。这没有什么意义,因此需要做一些处理。

首先需要对结果 Y 矩阵进行均值归一化处理,将每一个用户对某一部电影的评分减去所有用户对该电影评分的平均值:

然后利用这个新的 Y 矩阵来训练算法。 最后在预测评分时,需要在预测值的基础上加回平均值,即预测值等于 (θ(j))Tx(i) + μi 。因此对于 Eve,新模型预测出的她的打分都是该电影的平均分。
【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 16—Recommender Systems 推荐系统的更多相关文章
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 1_Introduction and Basic Concepts 介绍和基本概念
目录 1.1 欢迎1.2 机器学习是什么 1.2.1 机器学习定义 1.2.2 机器学习算法 - Supervised learning 监督学习 - Unsupervised learning 无 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 15—Anomaly Detection异常检测
Lecture 15 Anomaly Detection 异常检测 15.1 异常检测问题的动机 Problem Motivation 异常检测(Anomaly detection)问题是机器学习算法 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 14—Dimensionality Reduction 降维
Lecture 14 Dimensionality Reduction 降维 14.1 降维的动机一:数据压缩 Data Compression 现在讨论第二种无监督学习问题:降维. 降维的一个作用是 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 13—Clustering 聚类
Lecture 13 聚类 Clustering 13.1 无监督学习简介 Unsupervised Learning Introduction 现在开始学习第一个无监督学习算法:聚类.我们的数据没 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 12—Support Vector Machines 支持向量机
Lecture 12 支持向量机 Support Vector Machines 12.1 优化目标 Optimization Objective 支持向量机(Support Vector Machi ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 10—Advice for applying machine learning 机器学习应用建议
Lecture 10—Advice for applying machine learning 10.1 如何调试一个机器学习算法? 有多种方案: 1.获得更多训练数据:2.尝试更少特征:3.尝试更多 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 18—Photo OCR 应用实例:图片文字识别
Lecture 18—Photo OCR 应用实例:图片文字识别 18.1 问题描述和流程图 Problem Description and Pipeline 图像文字识别需要如下步骤: 1.文字侦测 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
随机推荐
- Lua table
获取数组长度 在Lua中可以使用“#”和table.maxn两种方法来获取数组的长度 arr = {,,,} arr[] = 7 都仅统计数字key的长度: #是从1递增到nil的长度: table. ...
- ubuntu下Python的安装和使用
版权声明 更新:2017-04-13-上午博主:LuckyAlan联系:liuwenvip163@163.com声明:吃水不忘挖井人,转载请注明出处! 1 文章介绍 本文介绍了Python的开发环境. ...
- python(十二):网络编程之ISO/OSI模型
互联网(Internet)是依据操作系统,在计算机硬件的基础上建立起的通讯机制.它依赖于TCP/IP协议栈. 一.ISO/OSI模型 1.ISO七层模型与OSI五层模型 它们将计算机抽象成了具有层级关 ...
- 数学杂烩总结(多项式/形式幂级数+FWT+特征多项式+生成函数+斯特林数+二次剩余+单位根反演+置换群)
数学杂烩总结(多项式/形式幂级数+FWT+特征多项式+生成函数+斯特林数+二次剩余+单位根反演+置换群) 因为不会做目录所以请善用ctrl+F 本来想的是笔记之类的,写着写着就变成了资源整理 一些有的 ...
- MySQL安装与操作总结
安装MySQL 添加mysql源 # rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm 安装mysq ...
- json常用方法和本地存储方法
1.JSON.parse()[把json字符串解析成json对象] 2.JSON.stringify()[把json对象中解析成json字符串] <script> let obj = '{ ...
- VS2013下的64位与32位程序配置
VS2013下的64位与32位程序配置 在Windows 7 64bit和Visual Studio 2013下生成64位程序. 新建一个Visual Studio Win32 Console项目 ...
- 转发 Java火焰图在Netflix的实践
为了分析不同软件或软件的不同版本使用CPU的情况,相关设计人员通常需要进行函数的堆栈性能分析.相比于定期采样获得数据的方式,利用定时中断来收集程序运行时的PC寄存器值.函数地址以及整个堆栈轨迹更加高效 ...
- JavaFX 之窗口拖动(三)
一.问题场景 在上一篇中,我们将窗口的默认标题栏隐藏从而导致鼠标点击窗体无法进行拖动. 二.解决思路 给组件添加鼠标按下事件监听器和鼠标拖动事件监听器. 三.代码实现 /** * 程序入口 * @au ...
- 3.JMeter添加集合点
1.JMeter的集合点是通过添加定时器来完成的,在做性能测试时,真正的并发是不可能的,为了更真实的模拟并发场景,因此在需要压测的地方设置集合点,即可一起操作发送请求. 2.JMeter添加定时器,右 ...