hadoop深入学习之SequenceFile
的1个byte
3.Key和Value的类名
4.压缩相关的信息
5.其他用户定义的元数据
6.同步标记,sync marker

Metadata 在文件创建时就写好了,所以也是不能更改的。条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
FileSystem fs=FileSystem.get(conf); Path mapFile=new Path("mapFile.map");
//Writer内部类用于文件的写操作,假设Key和Value都为Text类型 MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class); //通过writer向文档中写入记录 writer.append(new Text("key"),new Text("value")); IOUtils.closeStream(writer);//关闭write流
//Reader内部类用于文件的读取操作 MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf); //通过reader从文档中读取记录 Text key=new Text(); Text value=new Text(); while(reader.next(key,value)){ System.out.println(key); System.out.println(key); } IOUtils.closeStream(reader);//关闭read流
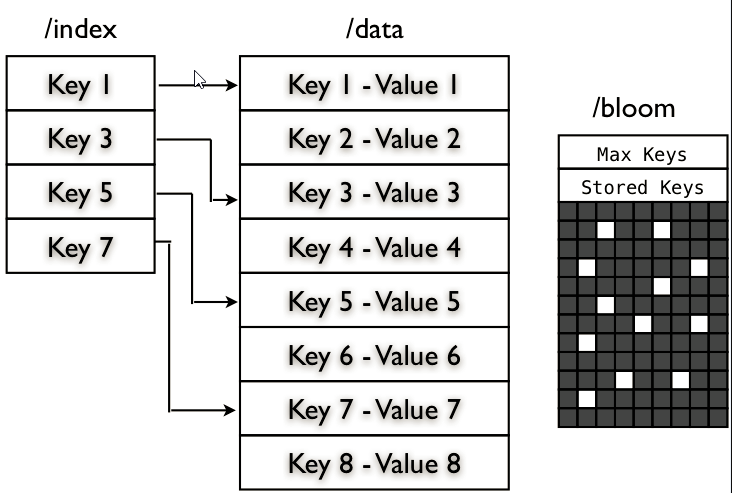
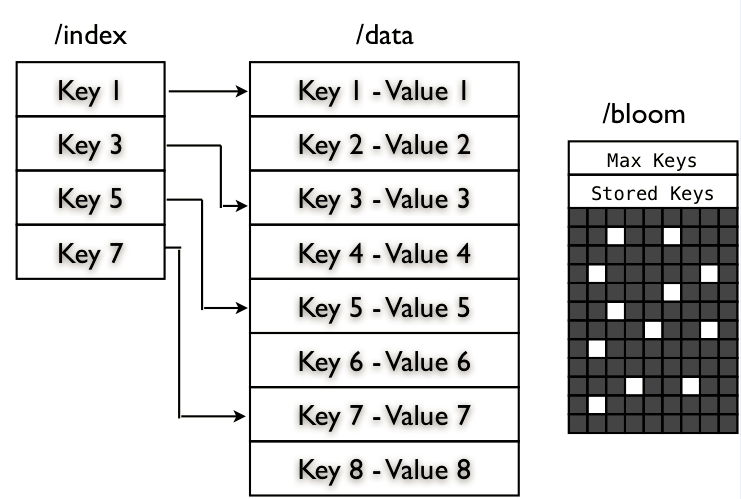
MapFile
一个key-value 对应的查找数据结构,由数据文件/data 和索引文件 /index 组成,数据文件中包含所有需要存储的key-value对,按key的顺序排列。索引文件包含一部分key值,用以指向数据文件的关键位置。
来源: http://blog.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
The MapFile is a directory that contains two SequenceFile: the data file (“/data”) and the index file (“/index”). The data contains all the key, value records but key N + 1 must be greater then or equal to the key N. This condition is checked during the append() operation, if checkKey fail it throws an IOException “Key out of order”.
The Index file is populated with the key and a LongWritable that contains the starting byte position of the record. Index does’t contains all the keys but just a fraction of the keys, you can specify the indexInterval calling setIndexInterval() method. The Index is read enteirely into memory, so if you’ve large map you can set a index skip value that allows you to keep in memory just a fraction of the index keys.
SetFile – 基于 MapFile 实现的,他只有key,value为不可变的数据。SetFile and ArrayFile are based on MapFile, and their implementation are just few lines of code. The SetFile instead of append(key, value) as just the key field append(key) and the value is always the NullWritable instance.
ArrayFile – 也是基于 MapFile 实现,他就像我们使用的数组一样,key值为序列化的数字。The ArrayFile as just the value field append(value) and the key is a LongWritable that contains the record number, count + 1.
BloomMapFile – 他在 MapFile 的基础上增加了一个 /bloom 文件,包含的是二进制的过滤表,在每一次写操作完成时,会更新这个过滤表The BloomMapFile extends the MapFile adding another file, the bloom file “/bloom”, and this file contains a serialization of the DynamicBloomFilter filled with the added keys. The bloom file is written entirely during the close operation.
If you want to play with SequenceFile, MapFile, SetFile, ArrayFile without using Java, I’ve written a naive implementation in python. You can find it, in my github repository python-hadoop.
参考url
--------------------------------
1.Hadoop I/O: Sequence, Map, Set, Array, BloomMap Files - Cloudera Engineering Blog
http://blog.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
== 以上 2017/7/6 下午5:29:17
--------------------------------
1.[hadoop源码阅读][4]-org.apache.hadoop.io - 阿笨猫 - 博客园
http://www.cnblogs.com/xuxm2007/archive/2012/06/15/2550986.html
== 以上 2017/7/6 下午5:06:26
http://hadoop.apache.org/common/docs/r0.20.2/api/index.html
http://blog.csdn.net/ludi7125/article/details/7605719
http://www.cloudera.com/blog/2011/01/hadoop-io-sequence-map-set-array-bloommap-files/
http://blog.nosqlfan.com/html/1217.html
http://jerrylead.iteye.com/blog/1181716
http://www.itivy.com/arch/archive/2011/12/12/hadoop-writable-interface-introduction.html
hadoop深入学习之SequenceFile的更多相关文章
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Hadoop家族学习路线图--转载
原文地址:http://blog.fens.me/hadoop-family-roadmap/ Sep 6, 2013 Tags: Hadoophadoop familyroadmap Comment ...
- Hadoop家族学习路线图
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- [转]Hadoop家族学习路线图
Hadoop家族学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, ...
- Hadoop家族学习路线图v
主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项 ...
- Hadoop家族学习路线、实践案例
作者:Han Hsiao链接:https://www.zhihu.com/question/19795366/answer/24524910来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
随机推荐
- mysql中一个字段根据另一字段的值分割为不同列
1.数据结构如下: vehicleId mileage_type mileage 11AM6897 0 120 11AM6897 1 60 13AY9180 0 ...
- Day16 Django深入讲解
参考博客: http://www.cnblogs.com/yuanchenqi/articles/6083427.html http://www.cnblogs.com/yuanchenqi/arti ...
- $.ajaxComplete()
https://www.cnblogs.com/RachelChen/p/5433881.html 全局ajax事件 必须当页面上存在任何ajax请求的时候都将触发这些特定的全局ajax处理函数. ...
- Java进阶7 并发优化2 并行程序设计模式
Java进阶7 并发优化2 并行程序设计模式20131114 1.Master-worker模式 前面讲解了Future模式,并且使用了简单的FutureTask来实现并发中的Future模式.下面介 ...
- canvas基础学习
/** * Created by ty on 2016/7/11. * canvas 基础 */ window.onload = function() { var canvas = document. ...
- python 中 property 属性的讲解及应用
Python中property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回 property属性的有两种方式: 1. 装饰器 即:在方法上应用装饰器 2. 类属性 即 ...
- bfs+状态压缩dp
题目连接 题解 : 对两两管道进行bfs,然后用dp[i][j] 来表示在i状态下通过了前j个管道 参考博客 #include<bits/stdc++.h> using namespace ...
- java异步计算Future的使用(转)
从jdk1.5开始我们可以利用Future来跟踪异步计算的结果.在此之前主线程要想获得工作线程(异步计算线程)的结果是比较麻烦的事情,需要我们进行特殊的程序结构设计,比较繁琐而且容易出错.有了Futu ...
- gcc中关于静态库和动态库使用(转)
转自:http://blog.chinaunix.net/uid-25871104-id-3069931.html 1,如何生成静态库 静态库只是一堆object对象的集合,使用ar命令可以将.o文件 ...
- (三) ffmpeg filter学习-编写自己的filter
目录 目录 什么是ffmpeg filter 如何使用ffmpeg filter 1 将输入的1920x1080缩小到960x540输出 2 为视频添加logo 3 去掉视频的logo 自己写一个过滤 ...