11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究
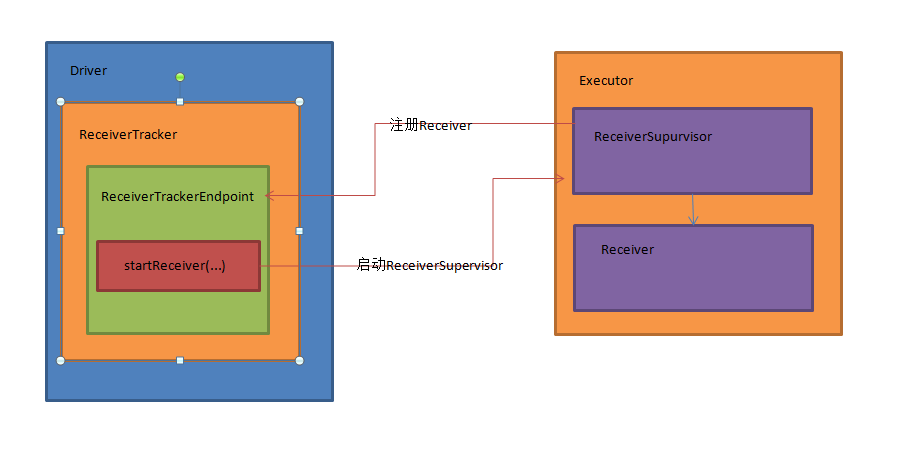
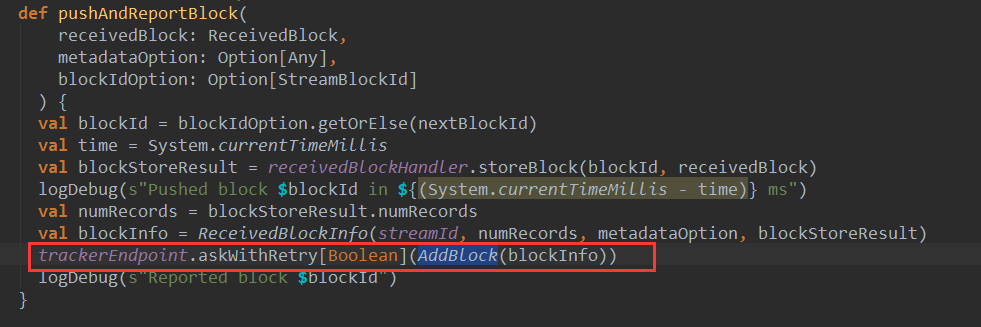
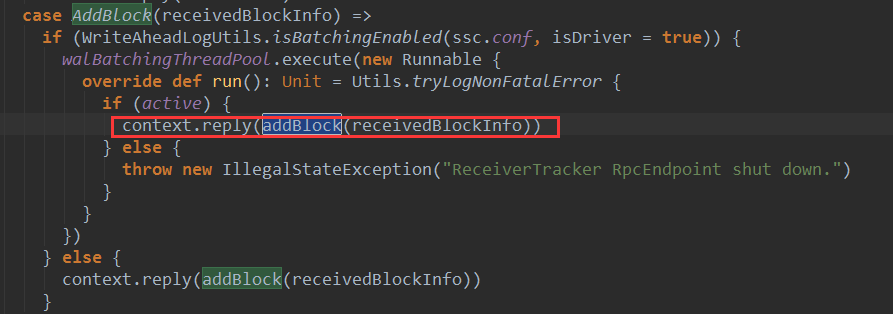
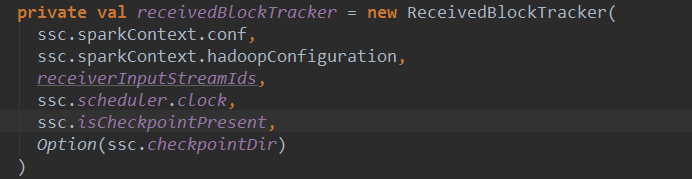
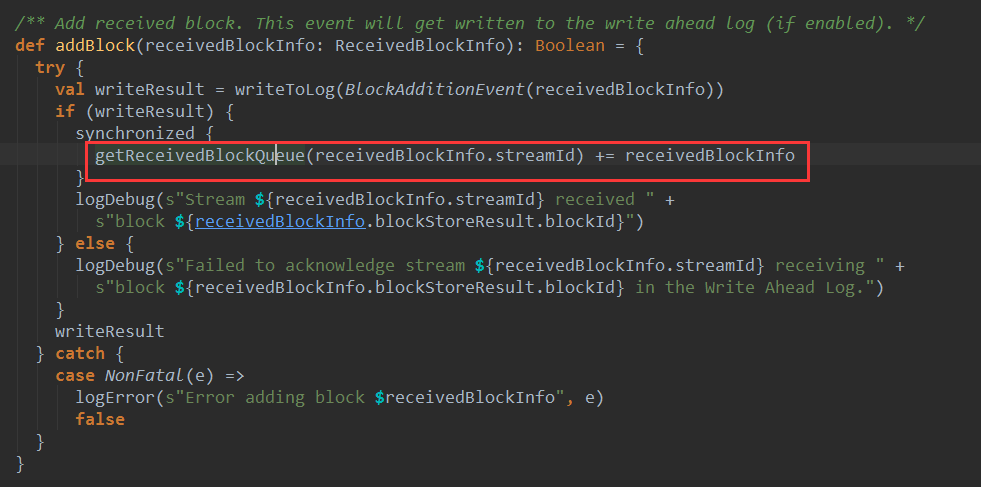
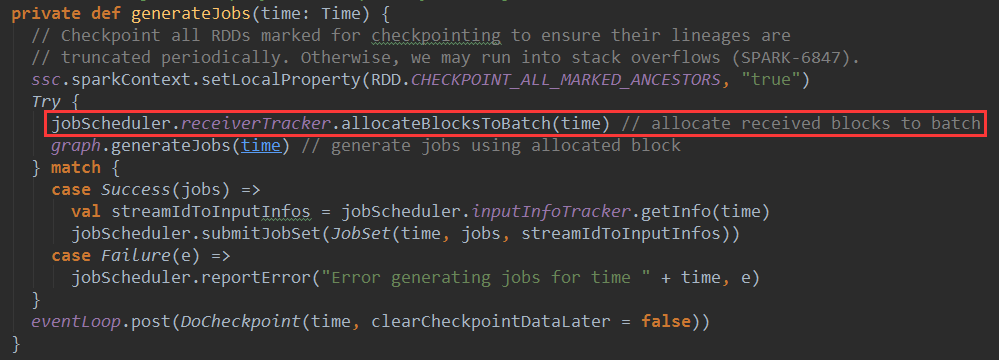
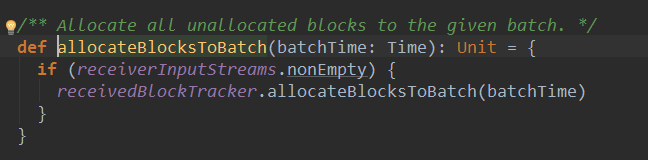
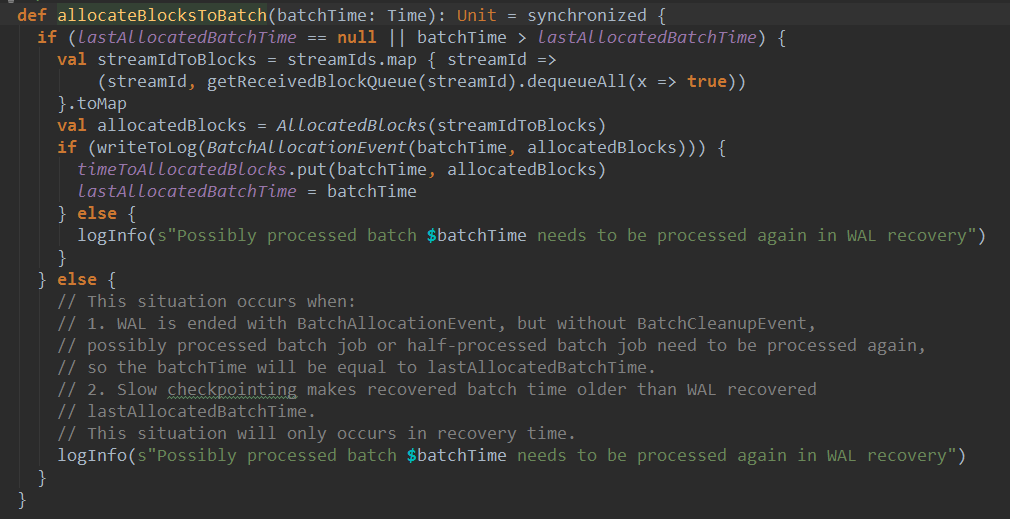
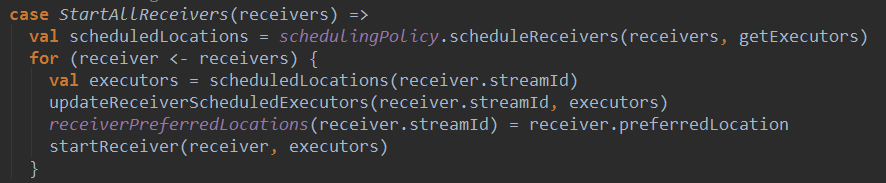
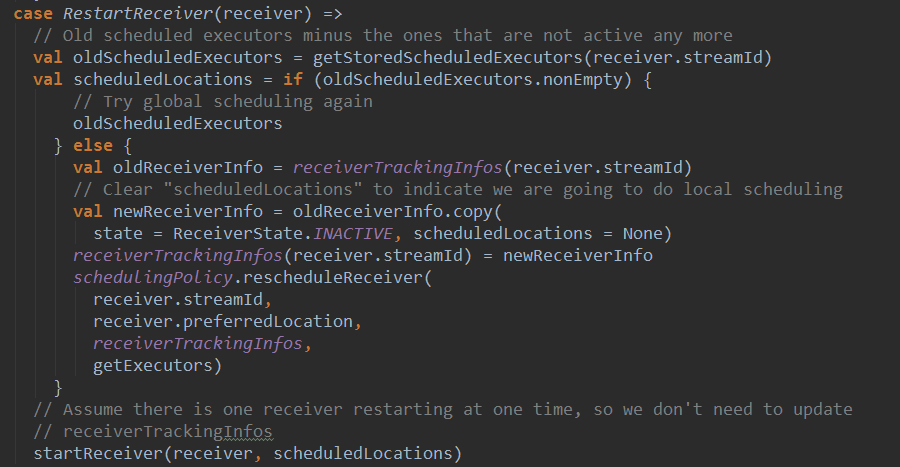
上篇文章详细解析了Receiver不断接收数据的过程,在Receiver接收数据的过程中会将数据的元信息发送给ReceiverTracker:






11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究的更多相关文章
- Spark Streaming源码解读之Driver中ReceiverTracker架构设计以具体实现彻底研究
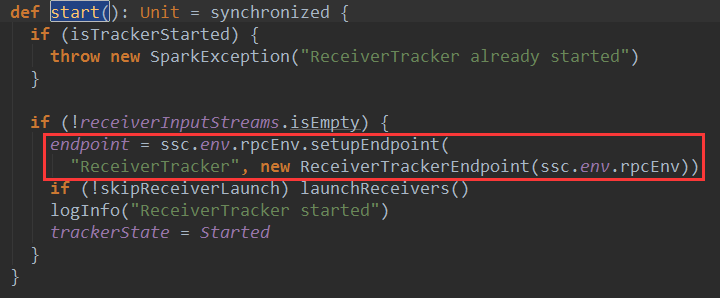
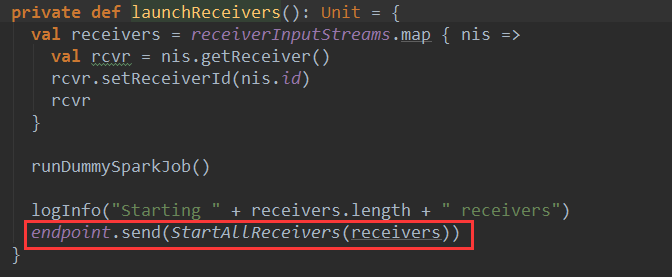
本期内容 : ReceiverTracker的架构设计 消息循环系统 ReceiverTracker具体实现 一. ReceiverTracker的架构设计 1. ReceiverTracker可以以 ...
- Spark Streaming源码解读之Driver容错安全性
本期内容 : ReceivedBlockTracker容错安全性 DStreamGraph和JobGenerator容错安全性 Driver的安全性主要从Spark Streaming自己运行机制的角 ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- 15、Spark Streaming源码解读之No Receivers彻底思考
在前几期文章里讲了带Receiver的Spark Streaming 应用的相关源码解读,但是现在开发Spark Streaming的应用越来越多的采用No Receivers(Direct Appr ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming源码解读之生成全生命周期彻底研究与思考
本期内容 : DStream与RDD关系彻底研究 Streaming中RDD的生成彻底研究 问题的提出 : 1. RDD是怎么生成的,依靠什么生成 2.执行时是否与Spark Core上的RDD执行有 ...
- Spark Streaming源码解读之Job动态生成和深度思考
本期内容 : Spark Streaming Job生成深度思考 Spark Streaming Job生成源码解析 Spark Core中的Job就是一个运行的作业,就是具体做的某一件事,这里的JO ...
随机推荐
- synchronized 加锁Integer对象(数据重复)详解
场景描述:多线程输出1到100,对静态Integer对象加锁,synchronized代码块中操作Integer对象,发生线程安全问题(数据重复) 代码: public class MyRunnabl ...
- 《深入Java虚拟机》笔记
当运行一个Java程序的同时,也就在运行了一个Java虚拟机实例.Java虚拟机实例通过调用某个初始类的mian()方法来运行一个Java程序运行中Java程序的每一个线程都是一个独立的虚拟机执行引擎 ...
- [LeetCode] Gas Station,转化为求最大序列的解法,和更简单简单的Jump解法。
LeetCode上 Gas Station是比较经典的一题,它的魅力在于算法足够优秀的情况下,代码可以简化到非常简洁的程度. 原题如下 Gas Station There are N gas stat ...
- 基础但是很重要的2-sat POJ 3678
http://poj.org/problem?id=3678 题目大意:就是给你n个点,m条边,每个点都可以取值为0或者1,边上都会有一个符号op(op=xor or and三种)和一个权值c.然后问 ...
- HDU 1211 EXGCD
EXGCD的模板水题 RSA算法给你两个大素数p,q定义n=pq,F(n)=(p-1)(q-1) 找一个数e 使得(e⊥F(n)) 实际题目会给你e,p,q计算d,$de \mod F(n) = 1$ ...
- JAVA多线程提高八:线程锁技术
前面我们讲到了synchronized:那么这节就来将lock的功效. 一.locks相关类 锁相关的类都在包java.util.concurrent.locks下,有以下类和接口: |---Abst ...
- Fast File System
不扯淡了,直接来写吧,一天一共要写三篇博客,还有两篇呢. 1. 这篇博客讲什么? Fast File System(FFS)快速文件系统,基本思想已经在在上一篇博客File System Implem ...
- ASP.NET中的加密页面机制
本节介绍ASP.NET对视图信息的加密功能.Page.RegisterRequiresViewStateEncryption方法就是将控件注册为需要视图状态加密的控件.如果您要开发用于处理潜在的敏感信 ...
- 【CodeForces】790 C. Bear and Company 动态规划
[题目]C. Bear and Company [题意]给定大写字母字符串,交换相邻字符代价为1,求最小代价使得字符串不含"VK"子串.n<=75. [算法]动态规划 [题解 ...
- 【leetcode 简单】第三十九题 Excel表列名称
给定一个正整数,返回它在 Excel 表中相对应的列名称. 例如, 1 -> A 2 -> B 3 -> C ... 26 -> Z 27 -> AA 28 -> ...