11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究
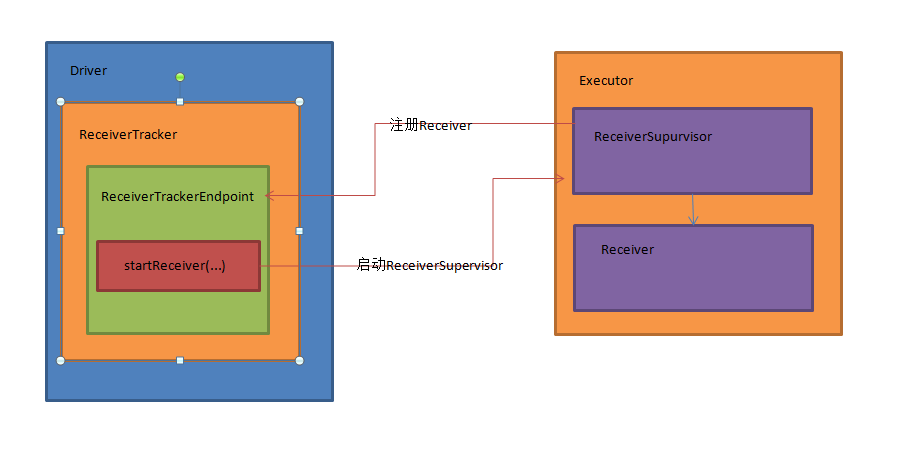
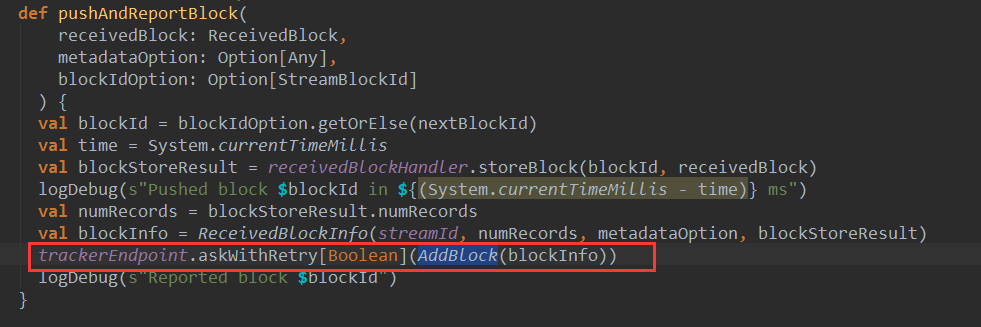
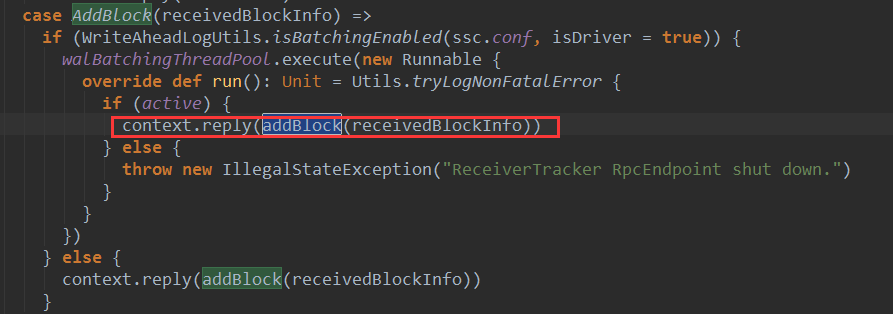
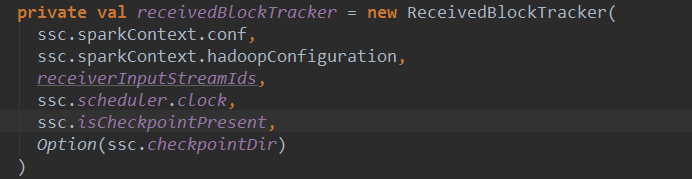
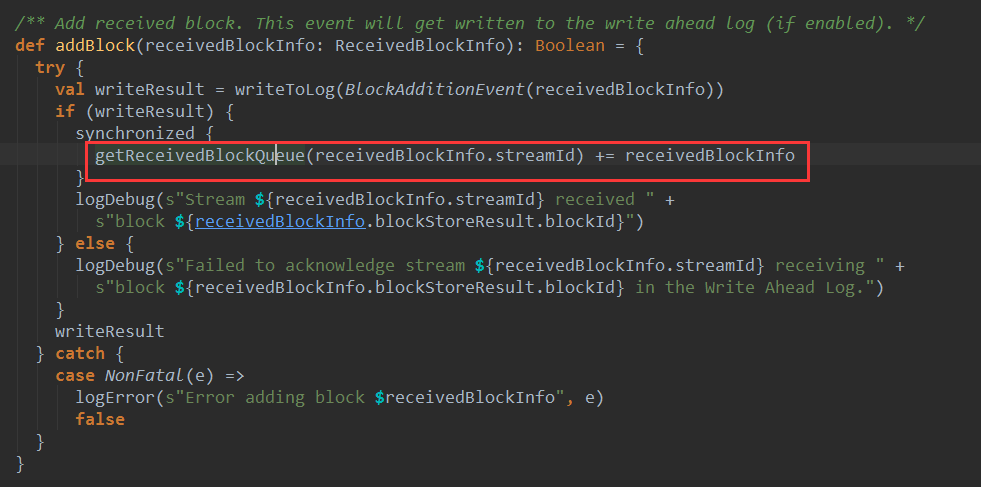
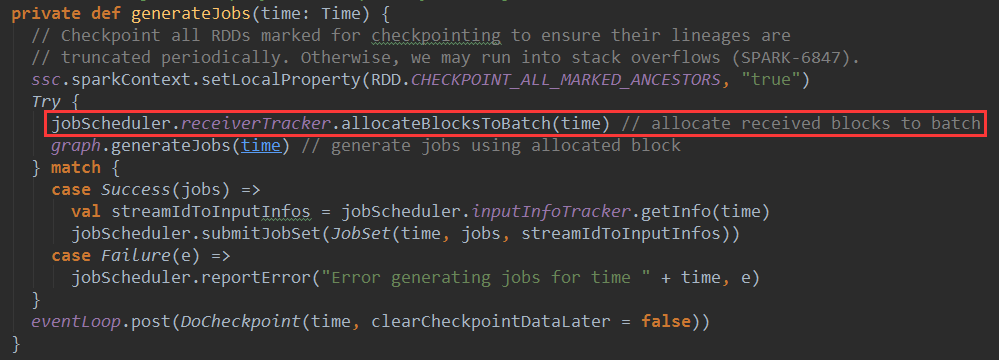
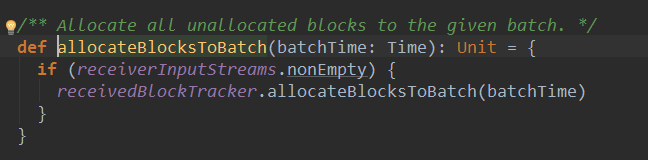
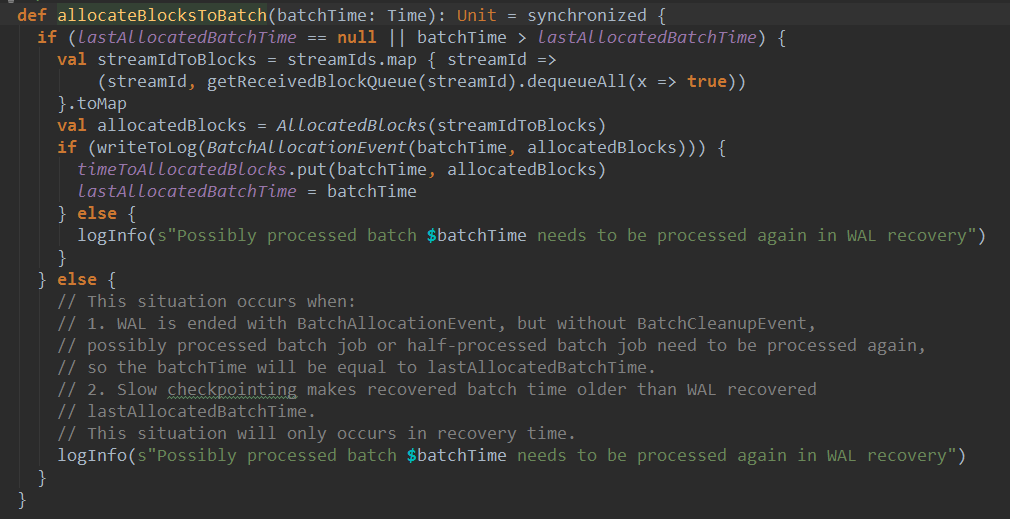
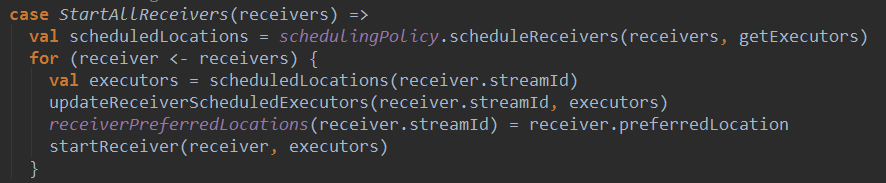
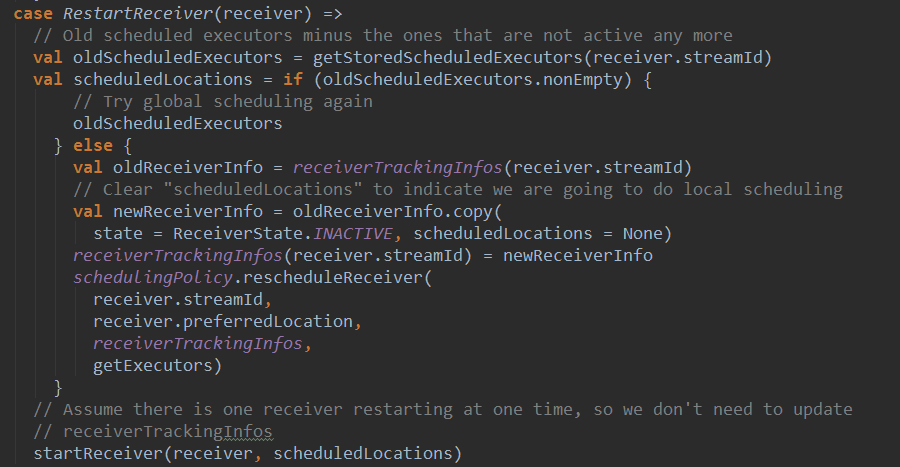
上篇文章详细解析了Receiver不断接收数据的过程,在Receiver接收数据的过程中会将数据的元信息发送给ReceiverTracker:






11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究的更多相关文章
- Spark Streaming源码解读之Driver中ReceiverTracker架构设计以具体实现彻底研究
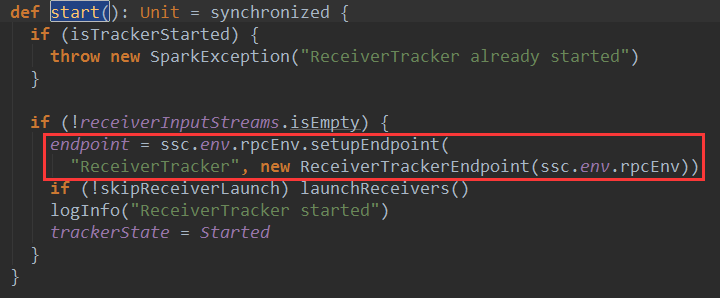
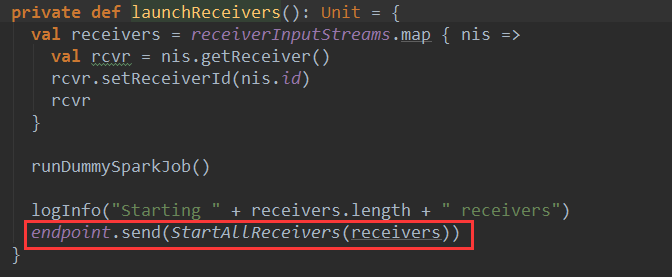
本期内容 : ReceiverTracker的架构设计 消息循环系统 ReceiverTracker具体实现 一. ReceiverTracker的架构设计 1. ReceiverTracker可以以 ...
- Spark Streaming源码解读之Driver容错安全性
本期内容 : ReceivedBlockTracker容错安全性 DStreamGraph和JobGenerator容错安全性 Driver的安全性主要从Spark Streaming自己运行机制的角 ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- 15、Spark Streaming源码解读之No Receivers彻底思考
在前几期文章里讲了带Receiver的Spark Streaming 应用的相关源码解读,但是现在开发Spark Streaming的应用越来越多的采用No Receivers(Direct Appr ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming源码解读之生成全生命周期彻底研究与思考
本期内容 : DStream与RDD关系彻底研究 Streaming中RDD的生成彻底研究 问题的提出 : 1. RDD是怎么生成的,依靠什么生成 2.执行时是否与Spark Core上的RDD执行有 ...
- Spark Streaming源码解读之Job动态生成和深度思考
本期内容 : Spark Streaming Job生成深度思考 Spark Streaming Job生成源码解析 Spark Core中的Job就是一个运行的作业,就是具体做的某一件事,这里的JO ...
随机推荐
- C语言 ------ #undef 的使用
#undef 是在后面取消以前定义的宏定义 该指令的形式为 #undef 标识符 其中,标识符是一个宏名称.如果标识符当前没有被定义成一个宏名称,那么就会忽略该指令. 一旦定义预处理器标识符,它将保持 ...
- zabbix 邮件配置
一.系统和版本 操作系统:centos7 zabbix版本: 3.2.5 二.安装sendmail yum -y install sendmail systemctl enable sendmail ...
- 【Android】完善Android学习(七:API 4.0.3)
备注:之前Android入门学习的书籍使用的是杨丰盛的<Android应用开发揭秘>,这本书是基于Android 2.2API的,目前Android已经到4.4了,更新了很多的API,也增 ...
- JSOI2008 小店购物
https://www.luogu.org/problem/show?pid=2792 题目背景 JSOI集训队的队员发现,在他们经常活动的集训地,有一个小店因为其丰富的经营优惠方案深受附近居民的青睐 ...
- 维护前面的position+主席树 Codeforces Round #406 (Div. 2) E
http://codeforces.com/contest/787/problem/E 题目大意:给你n块,每个块都有一个颜色,定义一个k,表示在区间[l,r]中最多有k中不同的颜色.另k=1,2,3 ...
- 关于NuGet
一.NuGet是什么? NuGet是Microsoft开发平台的程序集包管理器,它由客户端工具和服务端站点组成,客户端工具提供给用户管理和安装/卸载软件程序包,以及打包和发布程序包到NuGet服务端站 ...
- 深入理解Spring系列之十一:SpringMVC-@RequestBody接收json数据报415
转载 https://mp.weixin.qq.com/s/beRttZyxM3IBJJSXsLzh5g 问题原因 报错原因可能有两种情况: 请求头中没有设置Content-Type参数,或Conte ...
- AUC画图与计算
利用sklearn画AUC曲线 from sklearn.metrics import roc_curve labels=[1,1,0,0,1] preds=[0.8,0.7,0.3,0.6,0.5] ...
- Windows上安装Jekyll
Jekyll是什么 jekyll是一个简单的免费的Blog生成工具,是一个静态站点生成器, 它会根据网页源码生成静态文件.它提供了模板.变量.插件等功能,所以实际上可以用来编写整个网站.也可使用基于j ...
- centos7安装ssh服务
1.查看是否安装了相关软件: rpm -qa|grep -E "openssh" 显示结果含有以下三个软件,则表示已经安装,否则需要安装缺失的软件 openssh-ldap-6.6 ...