5.Python使用最新爬虫工具requests-html
1.安装,在命令行输入:pip install requests-html,安装成功后,在Pycharm引入即可。
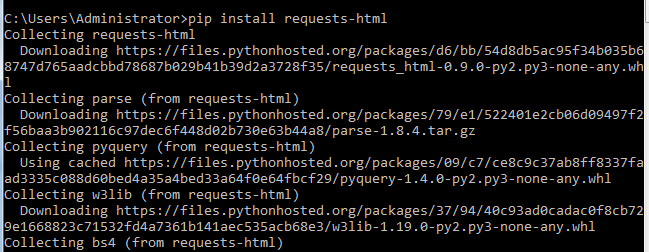
2.代码如下所示:
from requests_html import HTMLSession
import requests session = HTMLSession() r = session.get('http://www.win4000.com/wallpaper_2358_0_10_1.html') images = r.html.find('ul.clearfix > li > a') #获取到网页上所有a标签url def save_Image(url,title): #定义一个函数,用于保存图片到指定目录下(E盘下需手动新建bg文件夹)
html_response = requests.get(url)
with open('E:/bg/'+title+'.jpg','wb') as file:
file.write(html_response.content) #查找页面中背景图,找到链接,访问查看大图,并获取大图地址
for image in images:
image_url = image.attrs['href'] #获取到每张图片属性值为href的url
if '/wallpaper_detail' in image_url:
r = session.get(image_url)
item_url = r.html.find('img.pic-large',first=True) #获取到href下的src的url
url = item_url.attrs['src']
title = item_url.attrs['title']
print(url+title)
save_Image(url,title)
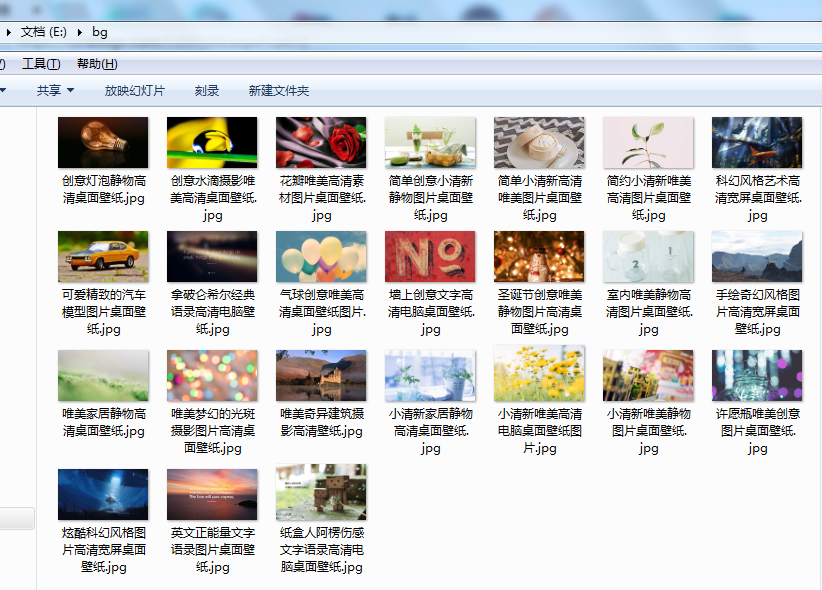
3.在指定目录即可查看到爬下来的图片
5.Python使用最新爬虫工具requests-html的更多相关文章
- python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 2.请求资源列表页面,定位获得左侧目录每一章的跳转url(难点) 3.请求每个跳转url,定位右侧下载 ...
- python写的爬虫工具,抓取行政村的信息并写入到hbase里
python的版本是2.7.10,使用了两个第三方模块bs4和happybase,可以通过pip直接安装. 1.logger利用python自带的logging模块配置了一个简单的日志输出 2.get ...
- python爬虫工具集合
python爬虫工具集合 大家一起来整理吧!强烈建议PR.这是初稿,总是有很多问题,而且考虑不全面,希望大家支持! 源文件 主要针对python3 常用库 urllib Urllib是python提供 ...
- 常见Python爬虫工具总结
常见Python爬虫工具总结 前言 以前写爬虫都是用requests包,虽然很好用,不过还是要封装一些header啊什么的,也没有用过无头浏览器,今天偶然接触了一下. 原因是在处理一个错误的时候,用到 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python爬虫工具
一直都听说python写爬虫工具非常方便,为了获取数据,我也要写点爬虫,但是python太灵活了,不知道python爬虫要哪些框架,要了解,比如beatiful soup,scrapy, 爬虫的额主要 ...
- Python爬虫之requests
爬虫之requests 库的基本用法 基本请求: requests库提供了http所有的基本请求方式.例如 r = requests.post("http://httpbin.org/pos ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
随机推荐
- opencv 图片降噪
—— # -*- coding: utf-8 -* import numpy as np import cv2 cap = cv2.VideoCapture(0) while True: _ , fr ...
- WTH统计
SELECT t2.MasterName AS '类型',SUM(t1.DailyCount) AS '数量',(CASE T2.MasterName WHEN '电子阅读' THEN '篇' WHE ...
- C# 常用时间戳处理方法
C# 常用时间戳处理方法 /// <summary> /// 时间戳转为C#格式时间 /// </summary> /// <param name="timeS ...
- socket的几个配置函数
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- LINUX系统下APACHE中的CGI应用
该实验环境是在APACHE的配置内容的基础上实现的! 1.安装软件: yum install php -y ##安装完成后,可以在/etc/httpd/conf.d/目录下查看,有php ...
- ETL学习整理 PostgreSQL
ETL分别是“Extract”.“ Transform” .“Load”三个单词的首字母缩写也就是“抽取”.“转换”.“装载”,但我们日常往往简称其为数据抽取. ETL是BI/DW(商务智能/数据仓库 ...
- Java并发编程之重入锁
重入锁,顾名思义,就是支持重进入的锁,它表示该锁能够支持一个线程对资源的重复加锁.重进入是指任意线程在获取到锁之后能够再次获取该锁而不会被锁阻塞,该特性的实现需要解决以下两个问题. 1.线程再次获取锁 ...
- SVN 安装配置详解,包含服务器和客户端,外带一个项目演示,提交,更改,下载历史版本,撤销
本次要介绍的是svn版本管理工具包含2个: 服务器端:visualsvn server 下载地址为:https://www.visualsvn.com/server/download/ 此处演示的 ...
- Android 4.0 Camera架构分析之Camera初始化
Android Camera 采用C/S架构,client 与server两个独立的线程之间使用Binder通信,这已经是众所周知的了.这里将介绍Camera从设备开机,到进入相机应用是如何完成初始化 ...
- css3实现对radio和checkbox的美化
一,如何隐藏小程序中的很粗的滚动条,实现页面的美化? tit: 在开发小程序的过程中,无论是横向或者纵向当产生滚动条时,系统默认的滚动条会很粗,效果展示十分难看,我们可以通过设置如下wxss代码实 ...