5.Python使用最新爬虫工具requests-html
1.安装,在命令行输入:pip install requests-html,安装成功后,在Pycharm引入即可。
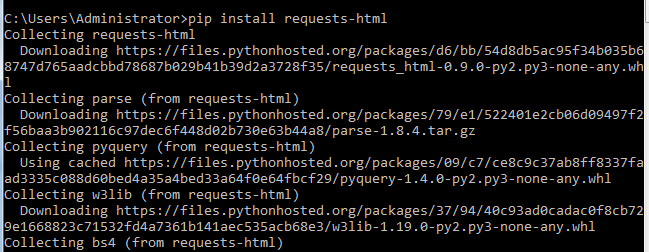
2.代码如下所示:
from requests_html import HTMLSession
import requests session = HTMLSession() r = session.get('http://www.win4000.com/wallpaper_2358_0_10_1.html') images = r.html.find('ul.clearfix > li > a') #获取到网页上所有a标签url def save_Image(url,title): #定义一个函数,用于保存图片到指定目录下(E盘下需手动新建bg文件夹)
html_response = requests.get(url)
with open('E:/bg/'+title+'.jpg','wb') as file:
file.write(html_response.content) #查找页面中背景图,找到链接,访问查看大图,并获取大图地址
for image in images:
image_url = image.attrs['href'] #获取到每张图片属性值为href的url
if '/wallpaper_detail' in image_url:
r = session.get(image_url)
item_url = r.html.find('img.pic-large',first=True) #获取到href下的src的url
url = item_url.attrs['src']
title = item_url.attrs['title']
print(url+title)
save_Image(url,title)
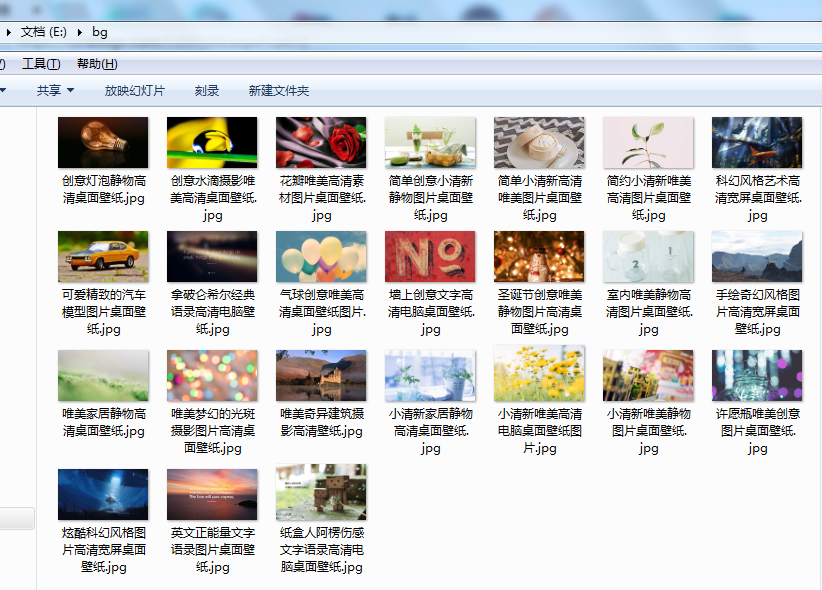
3.在指定目录即可查看到爬下来的图片
5.Python使用最新爬虫工具requests-html的更多相关文章
- python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 2.请求资源列表页面,定位获得左侧目录每一章的跳转url(难点) 3.请求每个跳转url,定位右侧下载 ...
- python写的爬虫工具,抓取行政村的信息并写入到hbase里
python的版本是2.7.10,使用了两个第三方模块bs4和happybase,可以通过pip直接安装. 1.logger利用python自带的logging模块配置了一个简单的日志输出 2.get ...
- python爬虫工具集合
python爬虫工具集合 大家一起来整理吧!强烈建议PR.这是初稿,总是有很多问题,而且考虑不全面,希望大家支持! 源文件 主要针对python3 常用库 urllib Urllib是python提供 ...
- 常见Python爬虫工具总结
常见Python爬虫工具总结 前言 以前写爬虫都是用requests包,虽然很好用,不过还是要封装一些header啊什么的,也没有用过无头浏览器,今天偶然接触了一下. 原因是在处理一个错误的时候,用到 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python爬虫工具
一直都听说python写爬虫工具非常方便,为了获取数据,我也要写点爬虫,但是python太灵活了,不知道python爬虫要哪些框架,要了解,比如beatiful soup,scrapy, 爬虫的额主要 ...
- Python爬虫之requests
爬虫之requests 库的基本用法 基本请求: requests库提供了http所有的基本请求方式.例如 r = requests.post("http://httpbin.org/pos ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
随机推荐
- 转:CentOS 7使用nmcli配置双网卡聚合LACP
进入CentOS 7以后,网络方面变化比较大,例如eth0不见了,ifconfig不见了,其原因是网络服务全部都由NetworkManager管理了,下面记录下今天下午用nmcli配置的网卡聚合,网络 ...
- hystrix -hystrix常用配置介绍
配置官网介绍地址:https://github.com/Netflix/Hystrix/wiki/Configuration hystrix.command.default.execution.iso ...
- LeetCode OJ:Peeking Iterator(peeking 迭代器)
Given an Iterator class interface with methods: next() and hasNext(), design and implement a Peeking ...
- jmeter的三种参数化
以FTP请求(用户.密码)为例:(其他都相同) 1.文件参数化 使用配置元件中的CSV Data Set Config 配置CSV Data Set Config: 文件中存储ftp登录的用户名和密码 ...
- obj-y,obj-m 区别
obj-y:把由foo.c 或者 foo.s 文件编译得到foo.o 并连接进内核.obj-m: 则表示该文件作为模块编译.除了y.m以外的obj-x 形式的目标都不会被编译. 除了obj-形式的目标 ...
- d3.js(v5.7)的node与数据匹配(自动匹配扩展函数)
在d3操作时,当然少不了对已有节点绑定数据,那么问题就来了,节点个数和数据长度不一样的,怎么办. d3在节点少于数据长度的时候,有enter().appen()方法实现node的增加: 在节点大于数据 ...
- SpreadJS 在 Angular2 中支持哪些事件?
SpreadJS 纯前端表格控件是基于 HTML5 的 JavaScript 电子表格和网格功能控件,提供了完备的公式引擎.排序.过滤.输入控件.数据可视化.Excel 导入/导出等功能,适用于 .N ...
- [Linux] 使用rename批量重命名文件
例如把所有png文件的后缀改为jpg $ rename 's/png/jpg/' *png
- Vue Devtools--vue调式工具
当浏览器控制台出现:Download the Vue Devtools extension for a better development experience: 1:安装 地址:https://g ...
- 利用索引与不用索引区别(profiles)
1.定义 对数据库表的一列或多列的值进行排序的一种结构(Btree方式)=(相当于二分查找法) 2.优点 加快数据检索速度 3.缺点 1.占用物理存储空间 2.当对表中数据更新时,索引需要动态维护,降 ...