Hbase架构和读写流程
转载自:http://www.cnblogs.com/muzili-ykt/p/muzili_ykt.html
在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相同)并不保证在一起,甚至删除一个Cell也只是写入一个新的Cell,它含有Delete标记,而不一定将一个Cell真正删除了,因而这就引起了一个问题,如何实现读的问题?要解决这个问题,我们先来分析一下相同的Cell可能存在的位置:首先对新写入的Cell,它会存在于MemStore中;然后对之前已经Flush到HDFS中的Cell,它会存在于某个或某些StoreFile(HFile)中;最后,对刚读取过的Cell,它可能存在于BlockCache中。既然相同的Cell可能存储在三个地方,在读取的时候只需要扫瞄这三个地方,然后将结果合并即可(Merge Read),在HBase中扫瞄的顺序依次是:BlockCache、MemStore、StoreFile(HFile)。其中StoreFile的扫瞄先会使用Bloom Filter过滤那些不可能符合条件的HFile,然后使用Block Index快速定位Cell,并将其加载到BlockCache中,然后从BlockCache中读取。我们知道一个HStore可能存在多个StoreFile(HFile),此时需要扫瞄多个HFile,如果HFile过多又是会引起性能问题。

Compaction
MemStore每次Flush会创建新的HFile,而过多的HFile会引起读的性能问题,那么如何解决这个问题呢?HBase采用Compaction机制来解决这个问题,有点类似Java中的GC机制,起初Java不停的申请内存而不释放,增加性能,然而天下没有免费的午餐,最终我们还是要在某个条件下去收集垃圾,很多时候需要Stop-The-World,这种Stop-The-World有些时候也会引起很大的问题,比如参考本人写的这篇文章,因而设计是一种权衡,没有完美的。还是类似Java中的GC,在HBase中Compaction分为两种:Minor Compaction和Major Compaction。
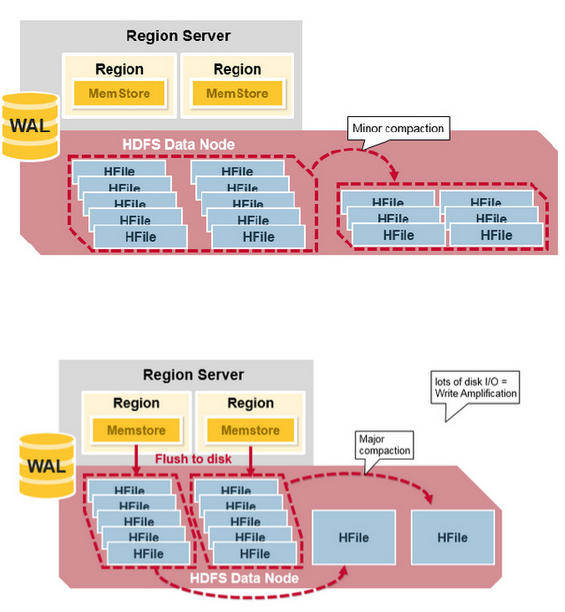
- Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。
- Major Compaction是指将所有的StoreFile合并成一个StoreFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃,那些已经超过最多版本数的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在。Major Compaction可以手动或自动触发,然而由于它会引起很多的IO操作而引起性能问题,因而它一般会被安排在周末、凌晨等集群比较闲的时间。
更形象一点,如下面两张图分别表示Minor Compaction和Major Compaction。
HRegion Split
最初,一个Table只有一个HRegion,随着数据写入增加,如果一个HRegion到达一定的大小,就需要Split成两个HRegion,这个大小由hbase.hregion.max.filesize指定,默认为10GB。当split时,两个新的HRegion会在同一个HRegionServer中创建,它们各自包含父HRegion一半的数据,当Split完成后,父HRegion会下线,而新的两个子HRegion会向HMaster注册上线,处于负载均衡的考虑,这两个新的HRegion可能会被HMaster分配到其他的HRegionServer中。关于Split的详细信息,可以参考这篇文章:《Apache HBase Region Splitting and Merging》。
HRegion负载均衡
在HRegion Split后,两个新的HRegion最初会和之前的父HRegion在相同的HRegionServer上,出于负载均衡的考虑,HMaster可能会将其中的一个甚至两个重新分配的其他的HRegionServer中,此时会引起有些HRegionServer处理的数据在其他节点上,直到下一次Major Compaction将数据从远端的节点移动到本地节点。

HRegionServer Recovery
当一台HRegionServer宕机时,由于它不再发送Heartbeat给ZooKeeper而被监测到,此时ZooKeeper会通知HMaster,HMaster会检测到哪台HRegionServer宕机,它将宕机的HRegionServer中的HRegion重新分配给其他的HRegionServer,同时HMaster会把宕机的HRegionServer相关的WAL拆分分配给相应的HRegionServer(将拆分出的WAL文件写入对应的目的HRegionServer的WAL目录中,并并写入对应的DataNode中),从而这些HRegionServer可以Replay分到的WAL来重建MemStore。
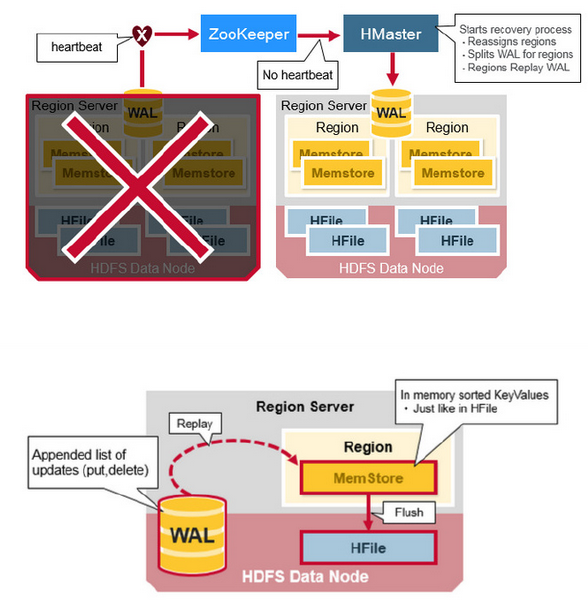
HBase架构简单总结
在NoSQL中,存在著名的CAP理论,即Consistency、Availability、Partition Tolerance不可全得,目前市场上基本上的NoSQL都采用Partition Tolerance以实现数据得水平扩展,来处理Relational DataBase遇到的无法处理数据量太大的问题,或引起的性能问题。因而只有剩下C和A可以选择。HBase在两者之间选择了Consistency,然后使用多个HMaster以及支持HRegionServer的failure监控、ZooKeeper引入作为协调者等各种手段来解决Availability问题,然而当网络的Split-Brain(Network Partition)发生时,它还是无法完全解决Availability的问题。从这个角度上,Cassandra选择了A,即它在网络Split-Brain时还是能正常写,而使用其他技术来解决Consistency的问题,如读的时候触发Consistency判断和处理。这是设计上的限制。
实现上的优点:
- HBase采用强一致性模型,在一个写返回后,保证所有的读都读到相同的数据。
- 通过HRegion动态Split和Merge实现自动扩展,并使用HDFS提供的多个数据备份功能,实现高可用性。
- 采用HRegionServer和DataNode运行在相同的服务器上实现数据的本地化,提升读写性能,并减少网络压力。
- 内建HRegionServer的宕机自动恢复。采用WAL来Replay还未持久化到HDFS的数据。
- 可以无缝的和Hadoop/MapReduce集成。
实现上的缺点:
- WAL的Replay过程可能会很慢。
- 灾难恢复比较复杂,也会比较慢。
- Major Compaction会引起IO Storm。
Hbase架构和读写流程的更多相关文章
- hbase架构和读写过程
转载自:https://www.cnblogs.com/itboys/p/7603634.html 在HBase读写时,相同Cell(RowKey/ColumnFamily/Column相同)并不保证 ...
- hadoop 组件 hdfs架构及读写流程
一 . Namenode Namenode 是整个系统的管理节点 就像一本书的目录,储存文件信息,地址,接受用户请求,等 二 . Datanode 提供真实的文件数据,存储服务 文件块(block)是 ...
- [转帖]深度分析HBase架构
深度分析HBase架构 https://zhuanlan.zhihu.com/p/30414252 原文链接(https://mapr.com/blog/in-depth-look-hbase-a ...
- 【HBase】知识小结+HMaster选举、故障恢复、读写流程
1:什么是HBase HBase是一个高可靠性,高性能,面向列,可伸缩的分布式数据库,提供海量数据存储功能,一个结构化的分布式存储系统,不同于一般的关系型数据库,它适合半结构化和非结构化数据存储. 2 ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- Hbase的读写流程
HBase读写流程 1.HBase读数据流程 HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在 ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- HBASE架构解析(一)
http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html 前记 公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官 ...
- HBase架构深度解析
原文出处: DLevin(@雪地脚印_) 前记 公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官网看到了这篇文文章:An In-Depth Look at the HBase A ...
随机推荐
- 巨头们的GitHub仓库整理
1.Google >1.Google >https://github.com/google >2.Google Samples https://github.com/googlesa ...
- 线段树 + 字符串Hash - Codeforces 580E Kefa and Watch
Kefa and Watch Problem's Link Mean: 给你一个长度为n的字符串s,有两种操作: 1 L R C : 把s[l,r]全部变为c; 2 L R d : 询问s[l,r]是 ...
- Web项目开发规范文档
http://www.kancloud.cn/chandler/css-code-guide/51267
- C++ 百炼成钢20
题目56: 编写C++程序完成以下功能:(1)定义一个Point类,其属性包括点的坐标,提供计算两点之间距离的方法:(2)定义一个圆形类,其属性包括圆心和半径:(3)创建两个圆形对象,提示用户输入圆心 ...
- C# 创建XML文件
private void CreateXMLFile(string pathAndFileName) { XmlDocument doc = new XmlDocument(); XmlElement ...
- [转]Shell脚本中获取SELECT结果值的方法
http://blog.itpub.net/13885898/viewspace-1670297/ 有时候我们可能会需要在Shell脚本中执行SELECT语句,并将结果赋值给一个变量,对于这样的情形, ...
- int main(int argc, char *argv[])中的argc和argv
argc 是 argument count的缩写,表示传入main函数的参数个数: argv 是 argument vector的缩写,表示传入main函数的参数序列或指针,并且第一个参数argv[0 ...
- Laravel5.1 搭建博客 --编译前端文件
上篇文章写了Gulp编译前端文件,这篇记录下在搭建博客中使用Gulp 1 引入bootstrap和js 1.1 首先先在项目本地安装Bower sudo npm install bower 1.2 创 ...
- Struts2_day03--课程安排_OGNL概述入门_什么是值栈_获取值栈对象_值栈内部结构
Struts2_day03 上节内容 今天内容 OGNL概述 OGNL入门案例 什么是值栈 获取值栈对象 值栈内部结构 向值栈放数据 向值栈放对象 向值栈放list集合 从值栈获取数据 获取字符串 获 ...
- ipc 进程间通讯的AIDL
1.什么是aidl:aidl是 Android Interface definition language的缩写,一看就明白,它是一种android内部进程通信接口的描述语言,通过它我们可以定义进程间 ...