keras_训练人脸识别模型心得
keras_cnn_实现人脸训练分类
废话不多扯,直接进入正题吧!今天在训练自己分割出来的图片,感觉效果挺不错的,所以在这分享一下心得,望入门的同孩采纳。
1、首先使用python OpenCV库里面的人脸检测分类器把你需要训练的测试人脸图片给提取出来,这一步很重要,因为deep learn他也不是万能的,很多原始人脸图片有很多干扰因素,直接拿去做模型训练效果是非常low的。所以必须得做这一步。而且还提醒一点就是你的人脸图片每个类别的人脸图片光线不要相差太大,虽然都是灰度图片,但是会影响你的结果,我测试过了好多次了,
2、把分割出来的人脸全部使用resize的方法变成[100x100]的图片,之前我也试过rgb的图片,但是效果不好,所以我建议都转成灰度图片,这样数据量小,计算速度也快,当然了keras的后端我建议使用TensorFlow-GPU版,这样计算过程明显比CPU快1万倍。
3、时间有限,我的数据集只有六张,前面三张是某某的人脸,后面三张又是另一个人脸,这样就只有两个类别,说到这里的时候很多人都觉得不可思议了吧,数据集这么小你怎么训练的?效果会好吗?那么你不要着急慢慢读下去吧!其次我把每个类别的前面两张图片自我复制了100次,这样我就有数据集了,类别的最后一张使用来做测试集,
自我复制50次。下面我来为大家揭晓答案吧,请详细参考如下代码:
(1)、导包
# coding:utf-
import numpy as np
import os
import cv2
os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten
from keras.layers import Conv2D,MaxPooling2D
from keras import optimizers
import pandas as pd
import matplotlib.pyplot as plt
导入需要包
(2)、读取我们的图片数据
filePath = os.listdir('img_test/')
print(filePath)
img_data = []
for i in filePath:
img_data.append(cv2.resize(cv2.cvtColor(cv2.imread('img_test/%s'%i),cv2.COLOR_BGR2GRAY),(100,100),interpolation=cv2.INTER_AREA))
导入图片
(3)、制作训练集合测试集
x_train = np.zeros([,,,])
y_train = []
x_test = np.zeros([,,,])
y_test = [] for i in range():
if i<:
x_train[i,:,:,] = img_data[]
y_train.append()
elif <=i<:
x_train[i, :, :, ] = img_data[]
y_train.append()
elif <=i<:
x_train[i, :, :, ] = img_data[]
y_train.append()
else:
x_train[i, :, :, ] = img_data[]
y_train.append() for j in range():
if j%==:
x_test[j, :, :, ] = img_data[]
y_test.append()
else:
x_test[j, :, :, ] = img_data[] # np.ones((,))
y_test.append() y_train = np.array(pd.get_dummies(y_train))
y_ts = np.array(y_test)
y_test = np.array(pd.get_dummies(y_test))
训练数据与测试数据
(4)、建立keras_cnn模型
model = Sequential()
# 第一层:
model.add(Conv2D(32,(3,3),input_shape=(100,100,1),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.5))
# model.add(Conv2D(64,(3,3),activation='relu'))
#第二层:
# model.add(Conv2D(32,(3,3),activation='relu')) # model.add(Dropout(0.25))
# model.add(MaxPooling2D(pool_size=(2,2)))
# model.add(Dropout(0.25)) # 2、全连接层和输出层:
model.add(Flatten())
# model.add(Dense(500,activation='relu'))
# model.add(Dropout(0.5))
model.add(Dense(20,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2,activation='softmax')) model.summary()
model.compile(loss='categorical_crossentropy',#,'binary_crossentropy'
optimizer=optimizers.Adadelta(lr=0.01, rho=0.95, epsilon=1e-06),#,'Adadelta'
metrics=['accuracy'])
建立模型
(5)、训练模型和得分输出
# 模型训练
model.fit(x_train,y_train,batch_size=30,epochs=100)
y_predict = model.predict(x_test)
score = model.evaluate(x_test, y_test)
print(score)
y_pred = np.argmax(y_predict,axis=1)
plt.figure('keras')
plt.scatter(list(range(len(y_pred))),y_pred ,c=y_pred)
plt.show()
下面是结果输出,loss = 0.0018 acc = 1.0 效果很不错,主要在于你训练时候的深度。
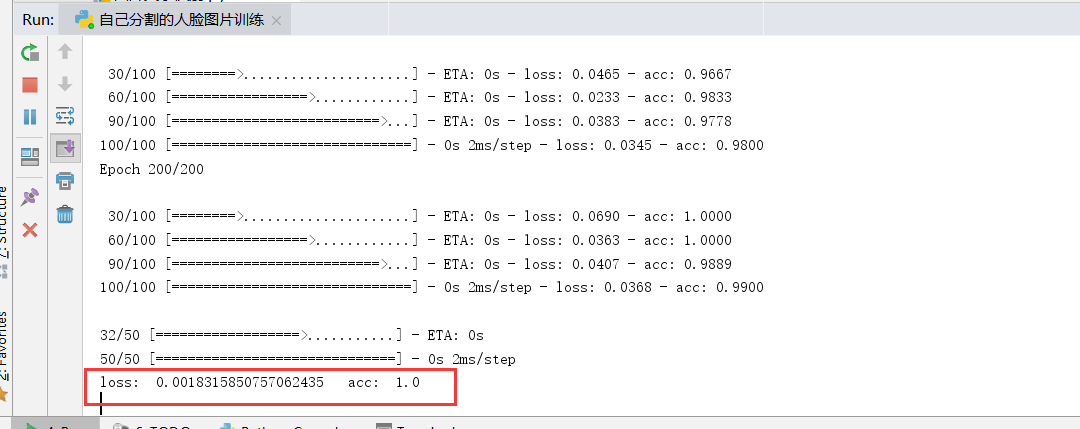

完整代码如下:
1 # coding:utf-8
2 import numpy as np
3 import os
4 import cv2
5 os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
6 from keras.models import Sequential
7 from keras.layers import Dense,Dropout,Flatten
8 from keras.layers import Conv2D,MaxPooling2D
9 from keras import optimizers
10 import pandas as pd
11 import matplotlib.pyplot as plt
12
13 filePath = os.listdir('img_test/')
14 print(filePath)
15 img_data = []
16 for i in filePath:
17 img_data.append(cv2.resize(cv2.cvtColor(cv2.imread('img_test/%s'%i),cv2.COLOR_BGR2GRAY),(100,100),interpolation=cv2.INTER_AREA))
18
19
20 x_train = np.zeros([100,100,100,1])
21 y_train = []
22 x_test = np.zeros([50,100,100,1])
23 y_test = []
24
25 for i in range(100):
26 if i<25:
27 x_train[i,:,:,0] = img_data[2]
28 y_train.append(1)
29 elif 25<=i<50:
30 x_train[i, :, :, 0] = img_data[4]
31 y_train.append(2)
32 elif 50<=i<75:
33 x_train[i, :, :, 0] = img_data[1]
34 y_train.append(1)
35 else:
36 x_train[i, :, :, 0] = img_data[5]
37 y_train.append(2)
38
39 for j in range(50):
40 if j%2==0:
41 x_test[j, :, :, 0] = img_data[0]
42 y_test.append(1)
43 else:
44 x_test[j, :, :, 0] = img_data[3] # np.ones((100,100))
45 y_test.append(2)
46
47 y_train = np.array(pd.get_dummies(y_train))
48 y_ts = np.array(y_test)
49 y_test = np.array(pd.get_dummies(y_test))
50 '''
51 from keras.models import load_model
52 from sklearn.metrics import accuracy_score
53
54 model = load_model('model/my_model.h5')
55 y_predict = model.predict(x_test)
56 y_p = np.argmax(y_predict,axis=1)+1
57 score = accuracy_score(y_ts,y_p)
58 # score = model.evaluate(x_train,y_train)
59 print(score)
60 '''
61
62 model = Sequential()
63 # 第一层:
64 model.add(Conv2D(32,(3,3),input_shape=(100,100,1),activation='relu'))
65 model.add(MaxPooling2D(pool_size=(2,2)))
66 model.add(Dropout(0.5))
67 # model.add(Conv2D(64,(3,3),activation='relu'))
68 #第二层:
69 # model.add(Conv2D(32,(3,3),activation='relu')) # model.add(Dropout(0.25))
70 # model.add(MaxPooling2D(pool_size=(2,2)))
71 # model.add(Dropout(0.25))
72
73 # 2、全连接层和输出层:
74 model.add(Flatten())
75 # model.add(Dense(500,activation='relu'))
76 # model.add(Dropout(0.5))
77 model.add(Dense(20,activation='relu'))
78 model.add(Dropout(0.5))
79 model.add(Dense(2,activation='softmax'))
80
81 model.summary()
82 model.compile(loss='categorical_crossentropy',#,'binary_crossentropy'
83 optimizer=optimizers.Adadelta(lr=0.01, rho=0.95, epsilon=1e-06),#,'Adadelta'
84 metrics=['accuracy'])
85
86 # 模型训练
87 model.fit(x_train,y_train,batch_size=30,epochs=150)
88 y_predict = model.predict(x_test)
89 score = model.evaluate(x_test, y_test)
90 print('loss: ',score[0],' acc: ',score[1])
91 y_pred = np.argmax(y_predict,axis=1)
92 plt.figure('keras',figsize=(12,6))
93 plt.scatter(list(range(len(y_pred))),y_pred ,c=y_pred)
94 plt.show()
95
96 # 保存模型
97 # model.save('test/my_model.h5')
98
99 # import matplotlib.pyplot as plt
100 # plt.imshow(x_train[30,:,:,0].reshape(100,100),cmap='gray')
101 # plt.figure()
102 # plt.imshow(x_test[3,:,:,0].reshape(100,100),cmap='gray')
103 # plt.xticks([]);plt.yticks([])
104 # plt.show()
keras_训练人脸识别模型心得的更多相关文章
- 人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型 经过前面稍显罗嗦的准备工作,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了.CNN擅长图像处理,keras库的te ...
- 虹软最新版 python 接口 完整版
虹软最新版 python 接口 完整版 当前开源的人脸检测模型,识别很多,很多小伙伴也踩过不少坑.相信不少使用过dlib和facenet人脸识别的小伙伴都有这样的疑惑,为什么论文里高达99.8以上的准 ...
- 腾讯 AI Lab 计算机视觉中心人脸 & OCR团队近期成果介绍(3)
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:周景超 在上一期中介绍了我们团队部分已公开的国际领先的研究成果,近期我们有些新的成果和大家进一步分享. 1 人脸进展 人脸是最重要的视觉 ...
- 让AI简单且强大:深度学习引擎OneFlow技术实践
本文内容节选自由msup主办的第七届TOP100summit,北京一流科技有限公司首席科学家袁进辉(老师木)分享的<让AI简单且强大:深度学习引擎OneFlow背后的技术实践>实录. 北京 ...
- face recognition[翻译][深度人脸识别:综述]
这里翻译下<Deep face recognition: a survey v4>. 1 引言 由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领 ...
- OpenCV 学习笔记 05 人脸检测和识别
本节将介绍 Haar 级联分类器,通过对比分析相邻图像区域来判断给定图像或子图像与已知对象是否匹配. 本章将考虑如何将多个 Haar 级联分类器构成一个层次结构,即一个分类器能识别整体区域(如人脸) ...
- Python的开源人脸识别库:离线识别率高达99.38%
Python的开源人脸识别库:离线识别率高达99.38% github源码:https://github.com/ageitgey/face_recognition#face-recognitio ...
- TensorFlow人脸识别
TensorFlow框架做实时人脸识别小项目(一)https://blog.csdn.net/Goerge_L/article/details/80208297 TensorFlow框架做实时人脸识别 ...
- 【EdgeBoard体验】开箱与上手
简介 市面上基于嵌入式平台的神经网络加速平台有很多,今天给大家带来是百度大脑出品的EdgeBoard.按照官网文档的介绍,EdgeBoard是基于Xilinx Zynq Ultrascale+ MPS ...
随机推荐
- JavaScript序列化对象成URL格式
http://access911.net/fixhtm/72FABF1E15DCEAF3.htm?tt=
- web端常见兼容性问题整理
一.html和css 各浏览器的默认内外边距不一致问题 最明显的是ul标签内外边距问题,ul标签在IE-7中,有个默认的外边距,但是在IE8以上及其他浏览器中有个默认的内边距. 解决办法:*{marg ...
- SSH公钥认证(码云)
开发者向码云版本库写入最常用到的协议是 SSH 协议,因为 SSH 协议使用公钥认证,可以实现无口令访问,而若使用 HTTPS 协议每次身份认证时都需要提供口令.使用 SSH 公钥认证,就涉及到公钥的 ...
- Python 3基础教程29-os模块
本文介绍os模块,主要是介绍一些文件的相关操作. 你还有其他方法去查看os 1. help() 然后输入os 2. Python接口文档,前面提到的用浏览器打开的,os文件路径为:C:\Users\A ...
- QC的使用学习(一)
今天学习的时间很少,就利用睡前的一点时间来学习一下刚安装好的QC. 1.后台站点管理.主要是对八大选项的了解: site project:顾名思义,就站点项目管理,管理域和项目. site user: ...
- python基础训练营05
任务五 时长:2天 1.file a.打开文件方式(读写两种方式) b.文件对象的操作方法 c.学习对excel及csv文件进行操作 2.os模块 3.datetime模块 4.类和对象 5.正则表达 ...
- mysql数据备份和还原
MySQL是一个永久存储数据的数据库服务器.如果使用MySQLServer,那么需要创建数据库备份以便从崩溃中恢复.mysql提供了一个用于备份的实用程序mysqldump. 1.普通.sql文件中的 ...
- Flask 学习笔记(一)
一.Web 服务器与 Web 框架 首先明确一下,要运行一个动态网页,我们需要 一个 Web 服务器来监听并响应请求,如果请求的是静态文件它就直接将其返回,如果是动态 url 它就将请求转交给 Web ...
- SQL select 和SQL where语句
一.SQL SELECT语句 用于从表中选取数据,结果被存储在一共结果表中(称为结果集) 1.语法: SELECT 列名称 FROM 表名称 以及: SELECT * FROM 表名称 注:SQ ...
- line-height用法总结
Line-height是前端用语,经常被前端开发人员经常使用. line-height设置1.5和150%有什么区别?这是一个比较常见的前端面试题. 定义: line-height指的是文本行基线间的 ...