Solr6 +mmseg4j+IK-Analyzer + SQLserver +DIH 完全配置
如今做任何一个系统都有搜索,而搜索界有著名的三剑客: solr/elasticsearch/sphinx
solr/elasticsearch 为同一类的,都是基于lucene开发的产品,本人也早在几年前用过solr做过类似中关村的产品搜索,faceting功能非常好用.
近期手头上又有个项目要搭建搜索,由于几年没摸过Solr,如今再次打开官网已觉得很陌生,不仅主页换漂亮了,版本更是到了6.1 ,还有了 solr cloud的概念!!
废话不多说,首先来介绍下环境配置:
1. 去 http://www.apache.org/dyn/closer.lua/lucene/solr/6.1.0 下载zip,解压放到你想放的位置, 我放到了E盘根目录
2. 设置环境变量PATH: E:\solr-6.1.0\bin , 这是为了方便在命令行里面可以直接找到 solr 命令
3. 任意位置创建一个目录,该目录包含以下内容
1). IK+mmseg4j的字典
2).sqlserver jdbc 驱动
3).最新版的 ik+mmseg4j 的 jar包
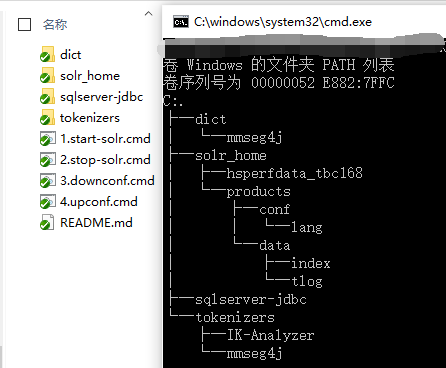
然后在目录下创建一个 1.start-solr.cmd (你喜欢的名字),内容如下:
solr start -h localhost -p 58983 -m 1g -s "%~dp0solr_home" -noprompt -V
双击运行(如果目录是需要管理员权限的, 有可能需要管理方式运行)
下面来说说具体配置
solrconfig.xml (\solr_home\products\conf\solrconfig.xml)
该配置文件是放到core里面的,我新建一个products的core
把所有依赖的jar包配置进去
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<!--同时兼容mmseg4j+ik中文分词器-->
<lib dir="${solr.solr.home}/../tokenizers/mmseg4j" regex=".*\.jar" />
<lib dir="${solr.solr.home}/../tokenizers/IK-Analyzer" regex=".*\.jar" />
<lib dir="${solr.solr.home}/../sqlserver-jdbc" regex=".*\.jar" />
启用DIH,这里要注意这个功能依赖上面的 solr-dataimporthandler-xx.jar 配置
<!--启用DIH数据导入-->
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
以下是solr6里面,如果要手动修改schame.xml配置时要替换的,详见注释链接
<!-- 这里需要配置这个,https://cwiki.apache.org/confluence/display/solr/Schema+Factory+Definition+in+SolrConfig -->
<schemaFactory class="ClassicIndexSchemaFactory"/>
schema.xml 配置
<!--以下定义中文分词器及各自的词典配置-->
<fieldtype name="mmseg4jComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="${solr.solr.home:}/../dict/mmseg4j" />
</analyzer>
</fieldtype>
<fieldtype name="mmseg4jMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="${solr.solr.home:}/../dict/mmseg4j" />
</analyzer>
</fieldtype>
<fieldtype name="mmseg4jSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="${solr.solr.home:}/../dict/mmseg4j" />
</analyzer>
</fieldtype> <fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.util.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<!--查询时候的分词器-->
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.util.IKTokenizerFactory" useSmart="false"/>
</analyzer>
</fieldType>
db-data-config.xml
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.microsoft.sqlserver.jdbc.SQLServerDriver"
url="jdbc:sqlserver://127.0.0.1:1433;databaseName=xxdb;"
user="dev"
password="111111"
batchSize="100" />
<document>
<entity name="product" query="select [id],[name],[brief],[description] from [products]"
deltaQuery="select id from [products] where [lastmodificationtime] > '${dataimporter.last_index_time}'">
<field column="name" name="name" />
<field column="brief" name="brief" />
<field column="description" name="description" />
</entity>
</document>
</dataConfig>
以上配置内包含的路径均没有写死, 使用的占位符, 可用的占位符可以在 solr admin ui 的 dashboard JVM 栏看到

!!!!!!!!!!!!!!!!!前方高能!!!!!!附件说明!!!!!!!!!!
(一定要先配置PATH环境变量后再双击)

Solr6 +mmseg4j+IK-Analyzer + SQLserver +DIH 完全配置的更多相关文章
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 安装elasticsearch及中文IK和近义词配置
安装elasticsearch及中文IK和近义词配置 安装java环境 java环境是elasticsearch安装必须的 yum install java-1.8.0-openjdk 安装elast ...
- Solr学习(2) Solr4.2.0+IK Analyzer 2012
Solr学习(二) Solr4.2.0+IK Analyzer 2012 开场白: 本章简单讲述如何在solr中配置著名的 IK Analyzer 分词器. 本章建立在 Solr学习(一) 基础上进 ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- 安装elasticsearch-1.7.1及中文IK和近义词配置
安装elasticsearch及中文IK和近义词配置 https://www.cnblogs.com/yjf512/p/4789239.html 安装elasticsearch及中文IK和近义词配置 ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- SharePoint 2013+ Sqlserver 2014 Kerberos 配置传奇, 最终的解决方案 验证。
SharePoint 2013+ Sqlserver 2014 Kerberos 配置传奇. 1,安装数据库,我就不多说安装,客户一定要注意. 我将参照以下实施例和账户. 2,建立DNS,假设没有DN ...
- Win7下Solr4.10.1和IK Analyzer中文分词
1.下载IK中文分词压缩包IK Analyzer 2012FF_hf1,并解压到D:\IK Analyzer 2012FF_hf1: 2.将D:\IK Analyzer 2012FF_hf1\IKAn ...
随机推荐
- cglib
参考:http://blog.csdn.net/zhoudaxia/article/details/30591941 <!-- https://mvnrepository.com/artifac ...
- bzoj 1706: [usaco2007 Nov]relays 奶牛接力跑——倍增floyd
Description FJ的N(2 <= N <= 1,000,000)头奶牛选择了接力跑作为她们的日常锻炼项目.至于进行接力跑的地点 自然是在牧场中现有的T(2 <= T < ...
- [POJ2954&POJ1265]皮克定理的应用两例
皮克定理: 在一个多边形中.用I表示多边形内部的点数,E来表示多边形边上的点数,S表示多边形的面积. 满足:S:=I+E/2-1; 解决这一类题可能运用到的: 求E,一条边(x1,y1,x2,y2)上 ...
- mysql七:数据备份、pymysql模块
阅读目录 一 IDE工具介绍 二 MySQL数据备份 三 pymysql模块 一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具 下载链接:https:/ ...
- Spring MVC 基础篇4
Spring MVC Controller中返回数据到页面 1.使用ModelAndView 进行数据返回到请求页面 2.利用Map类型的入参进行Controller返回到页面上 3.将数据放到Ses ...
- 工作管理 (job control)
这个工作管理 (job control) 是用在 bash 环境下的,也就是说:『当我们登入系统取得创建的 bash shell 进程之后,在该bush下同时进行多个工作的行为管理 』. 而所有创建的 ...
- 深入解析当下大热的前后端分离组件django-rest_framework系列一
前言 Nodejs的逐渐成熟和日趋稳定,使得越来越多的公司开始尝试使用Nodejs来练一下手,尝一尝鲜.在传统的web应用开发中,大多数的程序员会将浏览器作为前后端的分界线.将浏览器中为用户进行页面展 ...
- java类型强转
知乎: 首先基本数据类型不是对象,强转改的是值,分为有损和无损,有损会丢失数据细节. 然后对象,只有继承关系的类才能强转,改变的只是引用,而且向上转型是安全的,把你转为人类是安全的,你还是你,只是现在 ...
- windows上的命令telnet
telnet可以测试端口号是否可用,比如: telnet ip:port 或者 telnet www.baidu.com PS:win7环境下,默认没有安装telnet客户端,你可以去“控制面板”-- ...
- <div>之定位
在使用盒子模型的过程中,如何放置各种类型的“盒子”,就存在定位.浮动等问题.下面就日常运用过程中出现过的情况总结如下(陆续加入中....) 一.图片直接做<div>的背景 在<div ...