iommu分析之---smmu v3的实现
smmu 除了完成 iommu 的统一的ops 之外,有自己独特的一些地方。
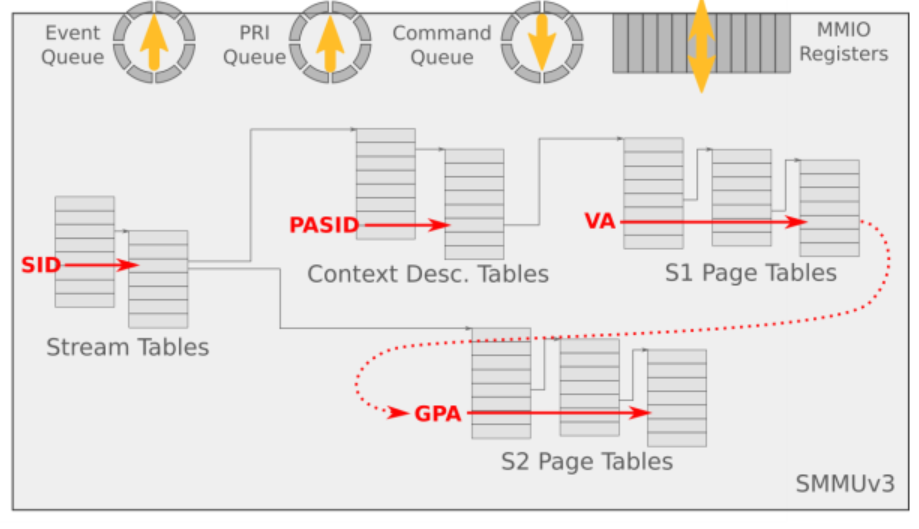
1、Stream Table
Stream Table是存在内存中的一张表,在SMMU设备初始化的时候由驱动程序创建好。
Stream Table支持2种格式,Linear Stream Table 和 2-level Stream Table, Linear Stream Table就是将整个Stream Table在内存中线性展开为一个数组,
优点是索引方便快捷,缺点是当平台上外设较少的时候浪费连续的内存空间。 2-level Stream Table则是将Stream Table拆成2级去索引,优点是更加节省内存。
但是请注意的是,Stream Table 的2-level的构造和 iommu支持的两个阶段的翻译不是一个概念,
SMMU支持2阶段地址翻译,这和内存虚拟化场景下MMU支持2阶段地址翻译类似, 第一阶段的地址翻译被用做进程(software entity)之间的隔离或者OS内的DMA隔离,
第二阶段的地址翻译被用来做DMA重映射,即将Guest发起的DMA映射到Guest的地址空间内。
第一阶段主要处理的是VA到IPA,第二阶段是IPA到PA
2、Stream Table的查找属于smmu的第一阶段查找么?
答案是肯定的,主要从看的角度来说。
我们经常表述的SMMU支持两阶段地址翻译,是指va到gpa为第一阶段,而gpa到hpa是第二阶段,
而stream table的查找是 属于前置查找,当然它可以实现为线性的,也可以实现为 2-level查找。
从术语上说,它都不属于前面所说的一阶段查找的一部分,但是它的结果又决定了stage1的行为。
3、Stream Table 是怎么申请内存的?
smmuv3对Stream Table申请内存的实现如下:
static int arm_smmu_init_strtab(struct arm_smmu_device *smmu)
{
u64 reg;
int ret;
if (smmu->features & ARM_SMMU_FEAT_2_LVL_STRTAB)//二级表模式,类似于二级mmu页表来理解
ret = arm_smmu_init_strtab_2lvl(smmu);
else
ret = arm_smmu_init_strtab_linear(smmu);//否则是线性模式,所谓线性就是可以理解为一维数组
....
如果是线性查找,则
static int arm_smmu_init_strtab_linear(struct arm_smmu_device *smmu)
{
void *strtab;
u64 reg;
u32 size;
struct arm_smmu_strtab_cfg *cfg = &smmu->strtab_cfg;
size = (1 << smmu->sid_bits) * (STRTAB_STE_DWORDS << 3);//caq:ste为64字节,8<<3为64
strtab = dmam_alloc_coherent(smmu->dev, size, &cfg->strtab_dma,
GFP_KERNEL | __GFP_ZERO);//条目数*64,然后申请内存,**注意这里是一次性申请完**,和二级不一样
if (!strtab) {
dev_err(smmu->dev,
"failed to allocate linear stream table (%u bytes)\n",
size);
return -ENOMEM;
}
cfg->strtab = strtab;//caq:申请的内存地址记录下来,stream table的基地址
cfg->num_l1_ents = 1 << smmu->sid_bits;//条目数
/* Configure strtab_base_cfg for a linear table covering all SIDs */
reg = FIELD_PREP(STRTAB_BASE_CFG_FMT, STRTAB_BASE_CFG_FMT_LINEAR);//caq:配置stream table(STRTAB_BASE_CFG)的log2size, ste的entry数目是2 ^ log2size
reg |= FIELD_PREP(STRTAB_BASE_CFG_LOG2SIZE, smmu->sid_bits);
cfg->strtab_base_cfg = reg;//
arm_smmu_init_bypass_stes(strtab, cfg->num_l1_ents);
return 0;
}
如果是2-level查找,则
//caq:二级表的初始化,查找的索引为SID,也就是streamid
static int arm_smmu_init_strtab_2lvl(struct arm_smmu_device *smmu)
{
void *strtab;
u64 reg;
u32 size, l1size;
struct arm_smmu_strtab_cfg *cfg = &smmu->strtab_cfg;
/* Calculate the L1 size, capped to the SIDSIZE. */
size = STRTAB_L1_SZ_SHIFT - (ilog2(STRTAB_L1_DESC_DWORDS) + 3);
size = min(size, smmu->sid_bits - STRTAB_SPLIT);
cfg->num_l1_ents = 1 << size;//caq:计算有多少一级条目
size += STRTAB_SPLIT;
if (size < smmu->sid_bits)
dev_warn(smmu->dev,
"2-level strtab only covers %u/%u bits of SID\n",
size, smmu->sid_bits);
l1size = cfg->num_l1_ents * (STRTAB_L1_DESC_DWORDS << 3);//一级表*8,就是一个指针大小
strtab = dmam_alloc_coherent(smmu->dev, l1size, &cfg->strtab_dma,
GFP_KERNEL | __GFP_ZERO);//caq:先申请一级表大小,请注意,看起来二级表是通过pagefault
if (!strtab) {
dev_err(smmu->dev,
"failed to allocate l1 stream table (%u bytes)\n",
size);
return -ENOMEM;
}
cfg->strtab = strtab;//caq:记录一级表位置,也就是stream table的基地址,是一个指针数组
/* Configure strtab_base_cfg for 2 levels */
reg = FIELD_PREP(STRTAB_BASE_CFG_FMT, STRTAB_BASE_CFG_FMT_2LVL);//caq:fmt为2level
reg |= FIELD_PREP(STRTAB_BASE_CFG_LOG2SIZE, size);
reg |= FIELD_PREP(STRTAB_BASE_CFG_SPLIT, STRTAB_SPLIT);
cfg->strtab_base_cfg = reg;//caq:要按照二级查找的模式构造这个值,最终会将这个值刷到对应的寄存器
return arm_smmu_init_l1_strtab(smmu);
}
那么,streamtable什么时候使用线性查找,什么时候使用二阶查找呢?
#define IDR1_SSIDSIZE GENMASK(10, 6)//硬件支持substreamID的bit数,0表示不支持substreamid
#define IDR1_SIDSIZE GENMASK(5, 0)//硬件支持streamID的bit数,0表示支持一个stream
/* SID/SSID sizes */
smmu->ssid_bits = FIELD_GET(IDR1_SSIDSIZE, reg);//caq:从硬件上支持的位数
smmu->sid_bits = FIELD_GET(IDR1_SIDSIZE, reg);//caq:从bit看支持64,但spec里面就是20bit,
/*
* If the SMMU supports fewer bits than would fill a single L2 stream
* table, use a linear table instead.
*/
if (smmu->sid_bits <= STRTAB_SPLIT)//caq:如果小于8bit,则没必要用二阶表
smmu->features &= ~ARM_SMMU_FEAT_2_LVL_STRTAB;//caq:直接用线性表
#define STRTAB_L1_SZ_SHIFT 20//caq:20位的streamid,按照高 STRTAB_SPLIT 位来拆分
#define STRTAB_SPLIT 8//caq:20位的streamid,高8位用来查找ste,低12位用来查找二层真正的ste entry
如果硬件支持的streamid的bit小于8,则只使用线性查找。
3、streamid,substreamid到底代表啥?
一个smmu可以有多个设备连着,他们的页表除非共用,否则肯定不一样,SMMU 用stream id作区分,注意,此时区分的是设备。
【StreamID去索引Stream Table中的STE(Stream Table Entry)】
一个设备有多个进程会使用,所以smmu单元也要支持多页表,smmu使用substream id区分多进程的io页表。
同样x86上也有类似的区分机制,不同的是x86是使用Request ID来区分的,Request ID默认是PCI设备分配到的BDF号。
看SMMUv3 Spec,又有说明:对于PCI设备StreamID就是PCI设备的RequestID, 两者其实就是同一个东西。
只是一个是从SMMU的角度去看就成为StreamID,从PCIe的角度去看就称之为RequestID。但arm内有很多platform类设备
这类设备没有bdf号,所以arm抽象成StreamID来区分设备也比较合理。
同时,一个设备可能被多个进程使用,
多个进程有多个页表,设备需要对其进行区分,SMMU使用SubstreamID来对其进行表示。 SubstreamID的概念和PCIe PASID是等效的,
这只不过又是在ARM上的另外一种称呼而已。 SubstreamID最大支持20bit和PCIe PASID的最大宽度是一致的。
设备master发起一笔DMA请求,请求的总线信息中带有streamid、subtreamid、iova(也就是大家理解的address)等参数,
smmu硬件收到该请求会自动通过streamid检索到STE表(目前我们N2是采用二级STE表),再通过substreamid检索到这个STE表指向的CD表
(就是context description表),从CD表中找到页表基地址,开始页表查找过程,找到IOVA对应的物理地址,再对这个物理地址发起一次DMA请求。
由于smmu是为master服务的,可以称其为秘书,这个master可以是一个pcie的设备,也可能是其他设备。
todo。。。。。。
同X86上一样,ARM上的设备直通关键也是要解决DMA重映射和直通设备中断投递的问题。 但和X86上不一样的是,
ARMv8-A上使用的是SMMU v3.1来处理设备的DMA重映射,这个在smmuv3的驱动代码就能看出,但是中断的话,
由于arm进入服务器领域较晚,所以arm迭代的支持虚拟化的中断是在GICv3中断控制器来完成的,
并没有像x86那样使用一个 **虚拟的 irq_chip **来完成。
SMMUv3和GICv3在设计的时候考虑了更多跟虚拟化相关的实现, 针对虚拟化场景有一定的改进和优化。
iommu分析之---smmu v3的实现的更多相关文章
- iommu分析之---intel irq remap框架实现
背景介绍: IRQ域层级结构: 在某些架构上,可能有多个中断控制器参与将一个中断从设备传送到目标CPU. 让我们来看看x86平台上典型的中断传递路径吧 Device --> IOAPIC -&g ...
- iommu分析之---intel iommu初始化
intel 的iommu 是iommu框架的一个实现案例. 由于intel 的iommu 实现得比arm smmv3复杂得多,里面概念也多,所以针对intel 实现的iommu 案例的初始化部分进行一 ...
- iommu分析之---DMA remap框架实现
本文主要介绍iommu的框架.基于4.19.204内核 IOMMU核心框架是管理IOMMU设备的一个通过框架,IOMMU设备通过实现特定的回调函数并将自身注册到IOMMU核心框架中,以此通过IOMMU ...
- Bootstarp-源码分析-alert.js v3.x和v4.x的对比
一些概念 1. 使用 data-api 调用 就是给所有带有data-dismiss="alert"的元素绑定点击事件 v3.x: $(document).on('click.bs ...
- 一文看透 Redis 分布式锁进化史(解读 + 缺陷分析)(转)
近两年来微服务变得越来越热门,越来越多的应用部署在分布式环境中,在分布式环境中,数据一致性是一直以来需要关注并且去解决的问题,分布式锁也就成为了一种广泛使用的技术,常用的分布式实现方式为Redis,Z ...
- ceph-csi组件源码分析(1)-组件介绍与部署yaml分析
更多ceph-csi其他源码分析,请查看下面这篇博文:kubernetes ceph-csi分析目录导航 ceph-csi组件源码分析(1)-组件介绍与部署yaml分析 基于tag v3.0.0 ht ...
- 【腾讯优测干货】看腾讯的技术大牛如何将Crash率从2.2%降至0.2%?
小优有话说: App Crash就像地雷. 你怕它,想当它不存在.无异于让你的用户去探雷,一旦引爆,用户就没了. 你鼓起勇气去扫雷,它却神龙见首不见尾. 你告诫自己一定开发过程中减少crash,少埋点 ...
- MSQL基本增删改语句汇总练习
删除约束注意: 网上说是 ALTER TABLE 表名 DROP CONSTRAINT 约束名; 这里的CONSTRAINT 是指primary key,foreign key,unique,等实际的 ...
- 将gdal源码转化为VS工程编译过程记录
作者:朱金灿 来源:http://blog.csdn.net/clever101 为什么要用VS工程的方式来编译gdal库?主要还是为了调试方便,虽然理论上使用命令行方式生成库也能调试,详见:GDAL ...
随机推荐
- 【Java面试】Mybatis中#{}和${}的区别是什么?
一个工作2年的粉丝,被问到一个Mybatis里面的基础问题. 他跑过来调戏我,说Mic老师,你要是能把这个问题回答到一定高度,请我和一个月奶茶. 这个问题是: "Mybatis里面#{}和$ ...
- 【Java集合】ArrayDeque源码解读
简介 双端队列是一种特殊的队列,它的两端都可以进出元素,故而得名双端队列. ArrayDeque是一种以循环数组方式实现的双端队列,它是非线程安全的. 它既可以作为队列也可以作为栈. 继承体系 Arr ...
- C语言学习之我见-strcpy()字符串复制函数
strcpy()函数,用于两个字符串值的复制. (1)函数原型 char * strcpy(char * _Dest,const char * _Source); (2)头文件 string.h (3 ...
- NLog自定义Target之MQTT
NLog是.Net中最流行的日志记录开源项目(之一),它灵活.免费.开源 官方支持文件.网络(Tcp.Udp).数据库.控制台等输出 社区支持Elastic.Seq等日志平台输出 实时日志需求 在工业 ...
- 一文get到SOLID原则的重点
最近没事再次翻开<敏捷软件开发:原则.模式与实践>看,发现以前似懂非懂的东西突然就看懂了,get到了讲的重点. SOLID(单一职责原则.开放-封闭原则.里氏替换原则.接口隔离原则以及 ...
- SAP FPM 相关包 APB_FPM_CORE
related interface: APB_FPM_COREAPB_FPM_CORE_4_EXT_SCAPB_FPM_CORE_INTERNALAPB_FPM_CORE_RESTRICTED
- UiPath循环活动Do While的介绍和使用
一.Do While的介绍 先执行循环体, 再判断条件是否满足, 如果满足, 则再次执行循环体, 直到判断条件不满足, 则跳出循环 二.Do While在UiPath中的使用 1. 打开设计器,在设计 ...
- python删除Android应用及文件夹,就说牛不牛吧
写在前面的一些P话: 碌者劳其心力,懒人使用工具.程序员作为懒人推动社会进步,有目共睹. adb 已提供了开发者可以使用的全部工具,但是重复执行一系列adb命令也令人心烦,所以,如果业务需求固定,直接 ...
- Http实战之Wireshark抓包分析
Http实战之Wireshark抓包分析 Http相关的文章网上一搜一大把,所以笔者这一系列的文章不会只陈述一些概念,更多的是通过实战(抓包+代码实现)的方式来跟大家讨论Http协议中的各种细节,帮助 ...
- P2599 [ZJOI2009]取石子游戏 做题感想
题目链接 前言 发现自己三岁时的题目都不会做. 我发现我真的是菜得真实. 正文 神仙构造,分讨题. 不敢说有构造,但是分讨我只服这道题. 看上去像是一个类似 \(Nim\) 游戏的变种,经过不断猜测结 ...