服务端挂了,客户端的 TCP 连接还在吗?
作者:小林coding
计算机八股文网站:https://xiaolincoding.com
大家好,我是小林。
如果「服务端挂掉」指的是「服务端进程崩溃」,服务端的进程在发生崩溃的时候,内核会发送 FIN 报文,与客户端进行四次挥手。
但是,如果「服务端挂掉」指的是「服务端主机宕机」,那么是不会发生四次挥手的,具体后续会发生什么?还要看客户端会不会发送数据?
- 如果客户端会发送数据,由于服务端已经不存在,客户端的数据报文会超时重传,当重传次数达到一定阈值后,会断开 TCP 连接;
- 如果客户端一直不会发送数据,再看客户端有没有开启 TCP keepalive 机制?
- 如果有开启,客户端在一段时间后,检测到服务端的 TCP 连接已经不存在,则会断开自身的 TCP 连接;
- 如果没有开启,客户端的 TCP 连接会一直存在,并不会断开。
上面属于精简回答了,下面我们详细聊聊。
服务端进程崩溃,客户端会发生什么?
TCP 的连接信息是由内核维护的,所以当服务端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使服务端的进程退出了,还是能与客户端完成 TCP四次挥手的过程。
我自己也做了实验,使用 kill -9 命令来模拟进程崩溃的情况,发现在 kill 掉进程后,服务端会发送 FIN 报文,与客户端进行四次挥手。
服务端主机宕机后,客户端会发生什么?
当服务端的主机突然断电了,这种情况就是属于服务端主机宕机了。
当服务端的主机发生了宕机,是没办法和客户端进行四次挥手的,所以在服务端主机发生宕机的那一时刻,客户端是没办法立刻感知到服务端主机宕机了,只能在后续的数据交互中来感知服务端的连接已经不存在了。
因此,我们要分两种情况来讨论:
- 服务端主机宕机后,客户端会发送数据;
- 服务端主机宕机后,客户端一直不会发送数据;
服务端主机宕机后,如果客户端会发送数据
在服务端主机宕机后,客户端发送了数据报文,由于得不到响应,在等待一定时长后,客户端就会触发超时重传机制,重传未得到响应的数据报文。
当重传次数达到达到一定阈值后,内核就会判定出该 TCP 连接有问题,然后通过 Socket 接口告诉应用程序该 TCP 连接出问题了,于是客户端的 TCP 连接就会断开。
那 TCP 的数据报文具体重传几次呢?
在 Linux 系统中,提供了一个叫 tcp_retries2 配置项,默认值是 15,如下图:
 图片
图片
这个内核参数是控制,在 TCP 连接建立的情况下,超时重传的最大次数。
不过 tcp_retries2 设置了 15 次,并不代表 TCP 超时重传了 15 次才会通知应用程序终止该 TCP 连接,内核会根据 tcp_retries2 设置的值,计算出一个 timeout(如果 tcp_retries2 =15,那么计算得到的 timeout = 924600 ms),如果重传间隔超过这个 timeout,则认为超过了阈值,就会停止重传,然后就会断开 TCP 连接。
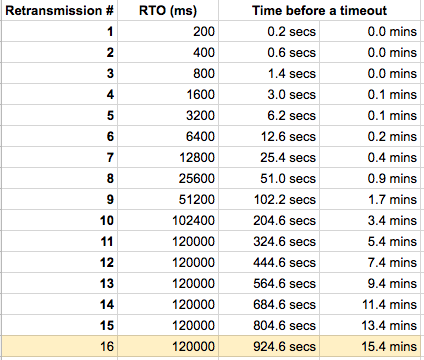
在发生超时重传的过程中,每一轮的超时时间(RTO)都是倍数增长的,比如如果第一轮 RTO 是 200 毫秒,那么第二轮 RTO 是 400 毫秒,第三轮 RTO 是 800 毫秒,以此类推。
而 RTO 是基于 RTT(一个包的往返时间) 来计算的,如果 RTT 较大,那么计算出来的 RTO 就越大,那么经过几轮重传后,很快就达到了上面的 timeout 值了。
举个例子,如果 tcp_retries2 =15,那么计算得到的 timeout = 924600 ms,如果重传总间隔时长达到了 timeout 就会停止重传,然后就会断开 TCP 连接:
- 如果 RTT 比较小,那么 RTO 初始值就约等于下限 200ms,也就是第一轮的超时时间是 200 毫秒,由于 timeout 总时长是 924600 ms,表现出来的现象刚好就是重传了 15 次,超过了 timeout 值,从而断开 TCP 连接
- 如果 RTT 比较大,假设 RTO 初始值计算得到的是 1000 ms,也就是第一轮的超时时间是 1 秒,那么根本不需要重传 15 次,重传总间隔就会超过 924600 ms。
最小 RTO 和最大 RTO 是在 Linux 内核中定义好了:
#define TCP_RTO_MAX ((unsigned)(120*HZ))
#define TCP_RTO_MIN ((unsigned)(HZ/5))
Linux 2.6+ 使用 1000 毫秒的 HZ,因此TCP_RTO_MIN约为 200 毫秒,TCP_RTO_MAX约为 120 秒。
如果tcp_retries设置为15,且 RTT 比较小,那么 RTO 初始值就约等于下限 200ms,这意味着它需要 924.6 秒才能将断开的 TCP 连接通知给上层(即应用程序),每一轮的 RTO 增长关系如下表格:
服务端主机宕机后,如果客户端一直不发数据
在服务端主机发送宕机后,如果客户端一直不发送数据,那么还得看是否开启了 TCP keepalive 机制 (TCP 保活机制)。
如果没有开启 TCP keepalive 机制,在服务端主机发送宕机后,如果客户端一直不发送数据,那么客户端的 TCP 连接将一直保持存在,所以我们可以得知一个点,在没有使用 TCP 保活机制,且双方不传输数据的情况下,一方的 TCP 连接处在 ESTABLISHED 状态时,并不代表另一方的 TCP 连接还一定是正常的。
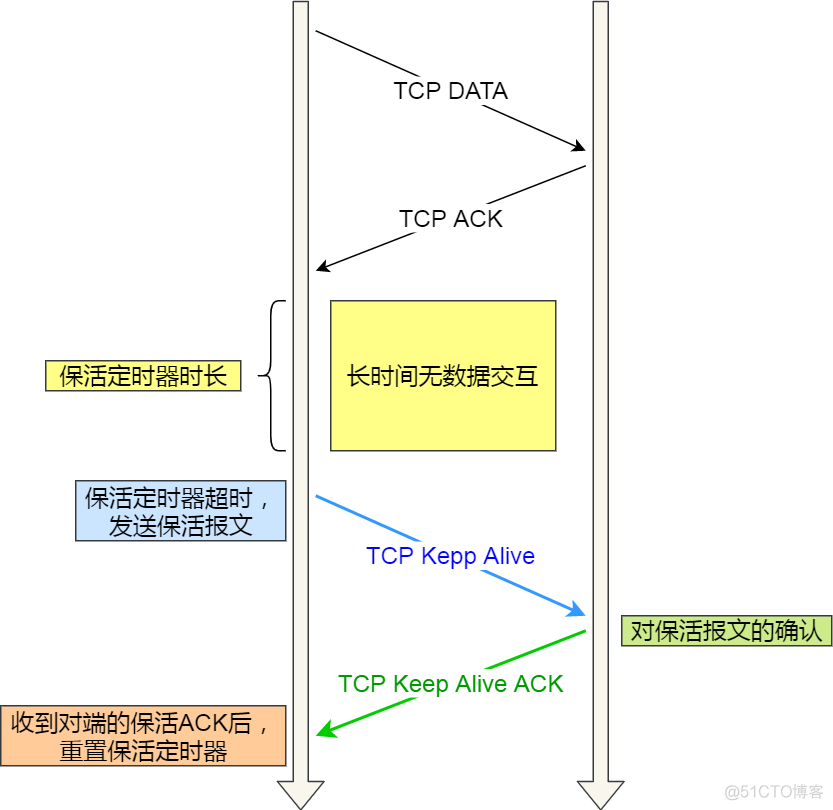
而如果开启了 TCP keepalive 机制,在服务端主机发送宕机后,即使客户端一直不发送数据,在持续一段时间后,TCP 就会发送探测报文,探测服务端是否存活:
- 如果对端是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
所以,TCP keepalive 机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活。
TCP keepalive 机制具体是怎么样的?
TCP keepalive 机制机制的原理是这样的:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
每个参数的意思,具体如下:
- tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制
- tcp_keepalive_intvl=75:表示每次检测间隔 75 秒;
- tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。

注意,应用程序如果想使用 TCP 保活机制,需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
TCP keepalive 机制探测的时间也太长了吧?
对的,是有点长。
TCP keepalive 是 TCP 层(内核态) 实现的,它是给所有基于 TCP 传输协议的程序一个兜底的方案。
实际上,我们应用层可以自己实现一套探测机制,可以在较短的时间内,探测到对方是否存活。
比如,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。如果设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。

总结
如果「服务端挂掉」指的是「服务端进程崩溃」,服务端的进程在发生崩溃的时候,内核会发送 FIN 报文,与客户端进行四次挥手。
但是,如果「服务端挂掉」指的是「服务端主机宕机」,那么是不会发生四次挥手的,具体后续会发生什么?还要看客户端会不会发送数据?
- 如果客户端会发送数据,由于服务端已经不存在,客户端的数据报文会超时重传,当重传总间隔时长达到一定阈值(内核会根据 tcp_retries2 设置的值计算出一个阈值)后,会断开 TCP 连接;
- 如果客户端一直不会发送数据,再看客户端有没有开启 TCP keepalive 机制?
- 如果有开启,客户端在一段时间没有进行数据交互时,会触发 TCP keepalive 机制,探测对方是否存在,如果探测到对方已经消亡,则会断开自身的 TCP 连接;
- 如果没有开启,客户端的 TCP 连接会一直存在,并且一直保持在 ESTABLISHED 状态。
还有另外一个很有意思的问题:「拔掉网线几秒,再插回去,原本的 TCP 连接还存在吗?」,之前我也写过,可以参考这篇:拔掉网线几秒,原本的 TCP 连接还存在吗?
完!
更多网络文章
 网站:xiaolincoding.com
网站:xiaolincoding.com
网络基础篇:
HTTP 篇:
TCP 篇:
- TCP 三次握手与四次挥手面试题
- TCP 重传、滑动窗口、流量控制、拥塞控制
- TCP 实战抓包分析
- TCP 半连接队列和全连接队列
- 如何优化 TCP?
- 如何理解是 TCP 面向字节流协议?
- 为什么 TCP 每次建立连接时,初始化序列号都要不一样呢?
- SYN 报文什么时候情况下会被丢弃?
- 四次挥手中收到乱序的 FIN 包会如何处理?
- 在 TIME_WAIT 状态的 TCP 连接,收到 SYN 后会发生什么?
- TCP 连接,一端断电和进程崩溃有什么区别?
- 拔掉网线后, 原本的 TCP 连接还存在吗?
- tcp_tw_reuse 为什么默认是关闭的?
- HTTPS 中 TLS 和 TCP 能同时握手吗?
- TCP Keepalive 和 HTTP Keep-Alive 是一个东西吗?
- TCP 有什么缺陷?
- 如何基于 UDP 协议实现可靠传输?
- TCP 和 UDP 可以使用同一个端口吗?
- 服务端没有 listen,客户端发起连接建立,会发生什么?
- 没有 accpet,可以建立 TCP 连接吗?
- 用了 TCP 协议,数据一定不会丢吗?
IP 篇:
学习心得:
服务端挂了,客户端的 TCP 连接还在吗?的更多相关文章
- [C语言]一个很实用的服务端和客户端进行TCP通信的实例
本文给出一个很实用的服务端和客户端进行TCP通信的小例子.具体实现上非常简单,只是平时编写类似程序,具体步骤经常忘记,还要总是查,暂且将其记下来,方便以后参考. (1)客户端程序,编写一个文件clie ...
- 保持WCF服务端与客户端的长连接
背景 客户端与服务端使用WCF建立连接后:1.可能长时间不对话(调用服务操作):2.客户端的网络不稳定. 为服务端与客户端两边都写“心跳检测”代码?不愿意. 解决 设置inactivityTimeou ...
- Tcp服务端判断客户端是否断开连接
今天搞tcp链接弄了一天,前面创建socket,绑定,监听等主要分清自己的参数,udp还是tcp的.好不容易调通了,然后就是一个需求,当客户端主动断开连接时,服务端也要断开连接,这样一下次客户端请求链 ...
- 通过netty实现服务端与客户端的长连接通讯,及心跳检测。
基本思路:netty服务端通过一个Map保存所有连接上来的客户端SocketChannel,客户端的Id作为Map的key.每次服务器端如果要向某个客户端发送消息,只需根据ClientId取出对应的S ...
- 拔掉网线后, 原本的 TCP 连接还存在吗?
大家好,我是小林. 今天,聊一个有趣的问题:拔掉网线几秒,再插回去,原本的 TCP 连接还存在吗? 可能有的同学会说,网线都被拔掉了,那说明物理层被断开了,那在上层的传输层理应也会断开,所以原本的 T ...
- WCF心跳判断服务端及客户端是否掉线并实现重连接
WCF心跳判断服务端及客户端是否掉线并实现重连接 本篇文章将通过一个实例实现对WCF中针对服务端以及客户端是否掉线进行判断:若掉线时服务器或客户端又在线时将实现自动重连:将通过WCF的双工知识以及相应 ...
- 编写一个简单的TCP服务端和客户端
下面的实验环境是linux系统. 效果如下: 1.启动服务端程序,监听在6666端口上 2.启动客户端,与服务端建立TCP连接 3.建立完TCP连接,在客户端上向服务端发送消息 4.断开连接 实现 ...
- 【转】TCP/UDP简易通信框架源码,支持轻松管理多个TCP服务端(客户端)、UDP客户端
[转]TCP/UDP简易通信框架源码,支持轻松管理多个TCP服务端(客户端).UDP客户端 目录 说明 TCP/UDP通信主要结构 管理多个Socket的解决方案 框架中TCP部分的使用 框架中UDP ...
- vertx 从Tcp服务端和客户端开始翻译
写TCP 服务器和客户端 vert.x能够使你很容易写出非阻塞的TCP客户端和服务器 创建一个TCP服务 最简单的创建TCP服务的方法是使用默认的配置:如下 NetServer server = ve ...
随机推荐
- CAP:多重注意力机制,有趣的细粒度分类方案 | AAAI 2021
论文提出细粒度分类解决方案CAP,通过上下文感知的注意力机制来帮助模型发现细微的特征变化.除了像素级别的注意力机制,还有区域级别的注意力机制以及局部特征编码方法,与以往的视觉方案很不同,值得一看 来源 ...
- SAP Office Excel Intergration
*&---------------------------------------------------------------------* *& Report DEMOEXCEL ...
- NC16663 [NOIP2004]合并果子
NC16663 [NOIP2004]合并果子 题目 题目描述 在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆.多多决定把所有的果子合成一堆. 每一次合并,多多可 ...
- eclipse使用小记录
(手动狗头)之前用eclipse的时候左侧的project栏不知道为什么整没了....记录一下 1.击Window--how View--other 2.Project Explorer,就可以了
- abstract,抽象修饰符
//abstract 抽象类:类由extends继承继承表现在单继承(接口可以多继承)//abstract--约束~~有人帮我们实现抽象方法,只有方法名字,没有方法实现1.不能靠new这个抽象类,只靠 ...
- 多校B层冲刺NOIP20211111模拟12
题面:PDFhttp://xn--gwt928b.accoders.com/pdf/10248/10248.pdfhttp://xn--gwt928b.accoders.com/pdf/10248/1 ...
- Acwing八数码
此题用\(bfs\) 首先我们可以定义两个重要的数组 \(unordered\_map<string,int> d\)表示\(string\)距离\(start\)的交换次数 \(queu ...
- 8000字讲透OBSA原理与应用实践
摘要:OBSA项目是围绕OBS建立的大数据和AI生态,其在不断的发展和完善中,目前有如下子项目:hadoop-obs项目和flink-obs项目. 文章作者:存储服务产品部开发者支持团队 OBS存储服 ...
- python 链表、堆、栈
简介 很多开发在开发中并没有过多的关注数据结构,当然我也是,因此,我写这篇文章就是想要带大家了解一下这些分别是什么东西. 链表 概念:数据随机存储,并且通过指针表示数据之间的逻辑关系的存储结构. 链表 ...
- 开源深度思考 - In Community We Trust
作者 | 黄东旭,PingCAP 联合创始人&CTO 出品 | CSDN(ID:CSDNnews) 业界一直流传着黄东旭的传说:小学三年级开始写代码,四五年级学习C语言,初中毕业时,已经能够用 ...