Netty ByteBuf 详解
ByteBuf类:Netty的数据容器
ByteBuf 维护了两个不同的索引:① readerIndex:用于读取;② writerIndex:用于写入;起始位置都从0开始: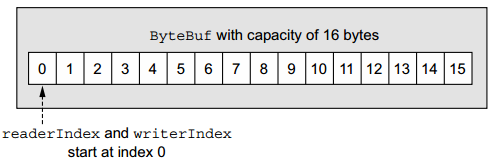

名称以 read或者 write开头的方法会更新 ByteBuf 对应的索引,而名称以 set或者 get开头的操作不会。 AbstractByteBuf.readByte 代码如下:
1 public byte readByte() {
2 checkReadableBytes0(1);
3 int i = readerIndex;
4 byte b = _getByte(i);
5 readerIndex = i + 1;// 这里更新了索引
6 return b;
7 }
AbstractByteBuf.getByte 代码如下:
1 public byte getByte(int index) {
2 checkIndex(index);
3 return _getByte(index);// 直接返回,没有更新索引
4 }
ByteBuf 的使用模式
【1】堆缓冲区:将数据存储在 JVM的堆空间。好处:提供快速分配和释放;场景:遗留数据处理;
1 public static void heapBuffer() {
2 ByteBuf heapBuf = BYTE_BUF_FROM_SOMEWHERE; //get reference form somewhere
3 if (heapBuf.hasArray()) { //检查 ByteBuf 是否有一个支撑数组
4 byte[] array = heapBuf.array();//如果有,则获取对该数组的引用
5 int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();//计算第一个字节的偏移量
6 int length = heapBuf.readableBytes();//获得可读字节数
7 handleArray(array, offset, length);//使用数组、偏移量和长度作为参数调用你的方法
8 }
9 }
如果 hasArray()返回false,仍然去访问array()会抛出 UnsupportedOperationException。
【2】直接缓冲区:NIO在JDK1.4中引入的 ByteBuffer类允许JVM实现通过本地调用来分配内存。直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外。 如果数据包含在一个在堆上分配的缓冲区中,在通过套接字发送它之前,JVM会在内部把缓冲区复制到一个直接缓冲区中。
目的:避免在每次调用本地I/O操作之前(后)将缓冲区的内容复制到一个中间缓冲区(或者从中间缓冲区把内容复制到缓冲区)
缺点:直接缓冲区的分配和释放较堆缓冲区昂贵。
1 public static void directBuffer() {
2 ByteBuf directBuf = BYTE_BUF_FROM_SOMEWHERE; //get reference form somewhere
3 if (!directBuf.hasArray()) {//检查 ByteBuf 是否由数组支撑。如果不是,则这是一个直接缓冲区
4 int length = directBuf.readableBytes();//获取可读字节数
5 byte[] array = new byte[length];//分配一个新的数组来保存具有该长度的字节数据
6 directBuf.getBytes(directBuf.readerIndex(), array);//将字节复制到该数组
7 handleArray(array, 0, length);//使用数组、偏移量和长度作为参数调用你的方法
8 }
9 }
【3】复合缓冲区:为多个ByteBuf提供一个聚合视图,可以根据需要添加或者删除 ByteBuf实例。 CompositeByteBuf ByteBuf的子类,提供一个将多个缓冲区表示为单个合并缓冲区的虚拟表示。CompositeByteBuf中的 ByteBuf实例可能同时包含直接内存分配和非直接内存分配。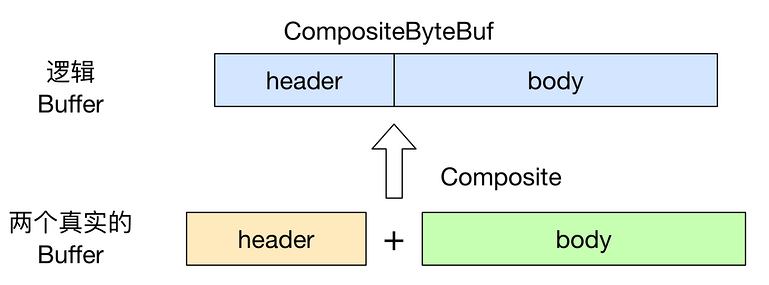
通过JDK的 ByteBuffer实现:创建一个包含两个 ByteBuffer的数组来保存消息组件
1 public static void byteBufferComposite(ByteBuffer header, ByteBuffer body) {
2 // Use an array to hold the message parts
3 ByteBuffer[] message = new ByteBuffer[]{ header, body };
4 // Create a new ByteBuffer and use copy to merge the header and body
5 ByteBuffer message2 =
6 ByteBuffer.allocate(header.remaining() + body.remaining());
7 message2.put(header);
8 message2.put(body);
9 message2.flip();
10 }
使用 CompositeByteBuf实现的复合缓冲区模式:
1 public static void byteBufComposite() {
2 CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
3 ByteBuf headerBuf = BYTE_BUF_FROM_SOMEWHERE; // can be backing or direct
4 ByteBuf bodyBuf = BYTE_BUF_FROM_SOMEWHERE; // can be backing or direct
5 messageBuf.addComponents(headerBuf, bodyBuf);//将 ByteBuf 实例追加到 CompositeByteBuf
6 //...
7 //删除位于索引位置为 0(第一个组件)的 ByteBuf
8 messageBuf.removeComponent(0); // remove the header
9 //循环遍历所有的 ByteBuf 实例
10 for (ByteBuf buf : messageBuf) {
11 System.out.println(buf.toString());
12 }
13 }
因为 CompositeByteBuf可能不支持访问其支撑数组,访问 CompositeByteBuf中的数据类似于直接缓冲区的模式:
1 public static void byteBufCompositeArray() {
2 CompositeByteBuf compBuf = Unpooled.compositeBuffer();
3 int length = compBuf.readableBytes();//获得可读字节数
4 byte[] array = new byte[length];//分配一个具有可读字节数长度的新数组
5 compBuf.getBytes(compBuf.readerIndex(), array);//将字节读到该数组中
6 handleArray(array, 0, array.length);//使用偏移量和长度作为参数使用该数组
7 }
ByteBuf 字节级操作
ByteBuf 提供了许多超出基本读/写操作的方法用于修改数据。
【1】随机访问索引:第一个字节的索引 0, 最后一个字节的索引:capacity() - 1;
1 public static void byteBufRelativeAccess() {
2 ByteBuf buffer = BYTE_BUF_FROM_SOMEWHERE; //get reference form somewhere
3 for (int i = 0; i < buffer.capacity(); i++) {
4 byte b = buffer.getByte(i);
5 System.out.println((char) b);
6 }
7 }
【2】顺序访问索引:首先看下 ByteBuf的内部分段:
+-------------------+------------------+------------------+
| discardable bytes | readable bytes | writable bytes |
| | (CONTENT) | |
+-------------------+------------------+------------------+
| | | |
0 <= readerIndex <= writerIndex <= capacity
After discardReadBytes():对可写分段的内容并没有任何保证,因为只是移动了可以读取的字节以及 writerIndex,并没有对所有可写入的字节进行擦除写。
+------------------+--------------------------------------+
| readable bytes | writable bytes (got more space) |
+------------------+--------------------------------------+
| | |
readerIndex (0) <= writerIndex (decreased) <= capacity
可以看出,ByteBuf被读索引和写索引划分成了3个区域:
● 可丢弃字节:已经被读过的字节,调用 discardReadBytes() 丢弃并回收空间(丢弃字节部分变为可写)。初始大小是0,存储在readerIndex中,随着 read操作的执行而增加。
●可读字节:可读字节分段存储了实际数据。新分配的/包装的/复制的缓冲区的默认的 readerIndex值为0。任何 read或者 skip开头的操作都将检索或者跳过位于当前 readerIndex的数据,并且将它增加已读字节数。如果被调用的方法需要一个 ByteBuf参数作为写入的目标,并且没有指定目标索引参数,那么该目标缓冲区的 writerIndex也将被增加。如果尝试在缓冲区的可读字节数已经耗尽时从中读取数据,将抛出 IndexOutOfBoundsException 见下面代码
●可写字节:可写字节分段指一个未定义内容/写入就绪的内存区域。新分配的缓冲区的 writerIndex的默认值是0。任何 write开头的操作都将从当前的 writerIndex处开始写数据,并将它增加已经写入的字节数。
readBytes(ByteBuf dst) 代码
1 public ByteBuf readBytes(ByteBuf dst) {
2 readBytes(dst, dst.writableBytes());
3 return this;
4 }
5 public ByteBuf readBytes(ByteBuf dst, int length) {
6 if (checkBounds) {
7 if (length > dst.writableBytes()) {
8 throw new IndexOutOfBoundsException(String.format(
9 "length(%d) exceeds dst.writableBytes(%d) where dst is: %s", length, dst.writableBytes(), dst));
10 }
11 }
12 readBytes(dst, dst.writerIndex(), length);
13 dst.writerIndex(dst.writerIndex() + length);
14 return this;
15 }
如何读取所有可读字节:
1 public static void readAllData() {
2 ByteBuf buffer = BYTE_BUF_FROM_SOMEWHERE; //get reference form somewhere
3 while (buffer.isReadable()) {
4 System.out.println(buffer.readByte());
5 }
6 }
如何往可写字节分段写数据:
1 public static void write() {
2 // Fills the writable bytes of a buffer with random integers.
3 ByteBuf buffer = BYTE_BUF_FROM_SOMEWHERE; //get reference form somewhere
4 while (buffer.writableBytes() >= 4) {
5 buffer.writeInt(random.nextInt());
6 }
7 }
Netty ByteBuf 详解的更多相关文章
- netty系列之:netty中的ByteBuf详解
目录 简介 ByteBuf详解 创建一个Buff 随机访问Buff 序列读写 搜索 其他衍生buffer方法 和现有JDK类型的转换 总结 简介 netty中用于进行信息承载和交流的类叫做ByteBu ...
- netty之ByteBuf详解
[ChannelPromise作用:可以设置success或failure 是为了通知ChannelFutureListener]Netty的数据处理API通过两个组件暴露——abstract cla ...
- BAT面试必问细节:关于Netty中的ByteBuf详解
在Netty中,还有另外一个比较常见的对象ByteBuf,它其实等同于Java Nio中的ByteBuffer,但是ByteBuf对Nio中的ByteBuffer的功能做了很作增强,下面我们来简单了解 ...
- Netty学习摘记 —— ByteBuf详解
本文参考 本篇文章是对<Netty In Action>一书第五章"ByteBuf"的学习摘记,主要内容为JDK 的ByteBuffer替代品ByteBuf的优越性 你 ...
- netty解码器详解(小白也能看懂!)
什么是编解码器? 首先,我们回顾一下netty的组件设计:Netty的主要组件有Channel.EventLoop.ChannelFuture.ChannelHandler.ChannelPipe等. ...
- [转帖]技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解
技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解 http://www.52im.net/thread-1309-1-1.html 本文来自腾讯资深研发工程师罗成的技术分享, ...
- Java网络编程和NIO详解9:基于NIO的网络编程框架Netty
Java网络编程和NIO详解9:基于NIO的网络编程框架Netty 转自https://sylvanassun.github.io/2017/11/30/2017-11-30-netty_introd ...
- netty系列之:netty中的Channel详解
目录 简介 Channel详解 异步IO和ChannelFuture Channel的层级结构 释放资源 事件处理 总结 简介 Channel是连接ByteBuf和Event的桥梁,netty中的Ch ...
- Netty 中文教程 Hello World !详解
1.HelloServer 详解 HelloServer首先定义了一个静态终态的变量---服务端绑定端口7878.至于为什么是这个7878端口,纯粹是笔者个人喜好.大家可以按照自己的习惯选择端口.当然 ...
- Netty详解
Netty详解 http://blog.csdn.net/suifeng3051/article/category/2161821
随机推荐
- 计算机网络复习小结(3)-IPv4
IPv4分组 一个IP分组由首部和数据两部分组成,首部前一部分的长度固定,共20B,是所有IP分组必须具有的.在IP数据报首部中有三个关于长度的标记,一个是首部长度,一个是总长度,一个是片偏移,基本单 ...
- FATAL Exited too quickly (process log may have details)的解决方案
作为一个混混的开发,不会啥容器操作.所以一般都是用supervisor来管理一些运行的进程 用了一段时间还是比较好用的,这个软件也是用的Python开发. 但在使用的过程中,status时会出现 FA ...
- 如何申请ios证书
第一次申请ios证书 记录下来 第一步 随便找个可以在线生成ios证书的网站 在这里生成csr文件 https://www.yunedit.com/update/ioszhengshu/list 第 ...
- Vscode插件离线安装教程+中文插件安装失败解决方案
参考地址:https://blog.csdn.net/r657225738/article/details/108460875
- java pta第二次阶段性总结
一.前言 经过这三次的pta训练,我对java再一次有了一个新的认识,这三次比起之前难度更大,所涉及的知识点更多.第4.5次作业是在前几次作业上的再次拓展,由三角形拓展到四边形,再由四边形拓展到五边形 ...
- pytorch 简简单单求个值
能用张量处理就用张量,不要使用for in 跑循环,一个是容易出错,一个是比较浪费时间,应用广播机制的话去做很容易的 1.5 使用mean处理平均值 2. 在处理梯度的时候无法更改自身,因此使用的办法 ...
- 配置Nginx 反向代理 + go在windows 环境下编译运行在linux的文件
在源码根目录下 创建build.bat: set GOOS=linux set GOARCH=amd64 go build -o build/myweb main.go 在终端执行: ./build. ...
- ReSharp的安装和使用教程
1.ReSharp的安装及破解: (1)不多说,直接上下载链接: 链接:https://pan.baidu.com/s/1cJmTQxDS-OHmHs46Q_hbMg 提取码:shiz (2)下载好解 ...
- python——numpy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库. import numpy a = num ...
- Linux下 Jdk版本切换
安装: 甲骨文官网下jdk 上传到云服务器 解压: tar -zxvf jdk-7u79-linux-x64.tar.gz 设置环境变量 vim /etc/profile 末尾加上 export JA ...