深入理解 Python 虚拟机:字典(dict)的优化
深入理解 Python 虚拟机:字典(dict)的优化
在前面的文章当中我们讨论的是 python3 当中早期的内嵌数据结构字典的实现,在本篇文章当中主要介绍在后续对于字典的内存优化。
字典优化
在前面的文章当中我们介绍的字典的数据结构主要如下所示:
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
PyDictKeyEntry dk_entries[1];
};
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;
用图示的方式表示如下图所示:
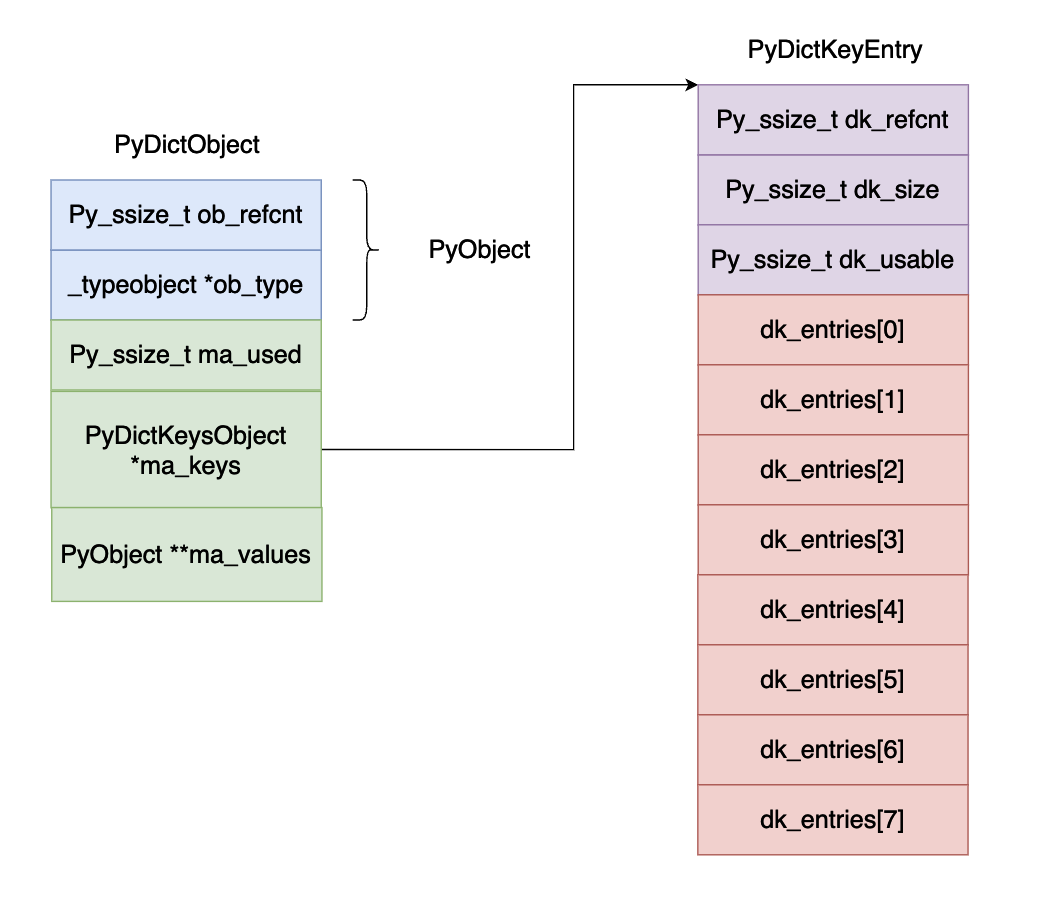
所有的键值对都存储在 dk_entries 数组当中,比如对于 "Hello" "World" 这个键值对存储过程如下所示,如果 "Hello" 的哈希值等于 8 ,那么计算出来对象在 dk_entries 数组当中的下标位 0 。

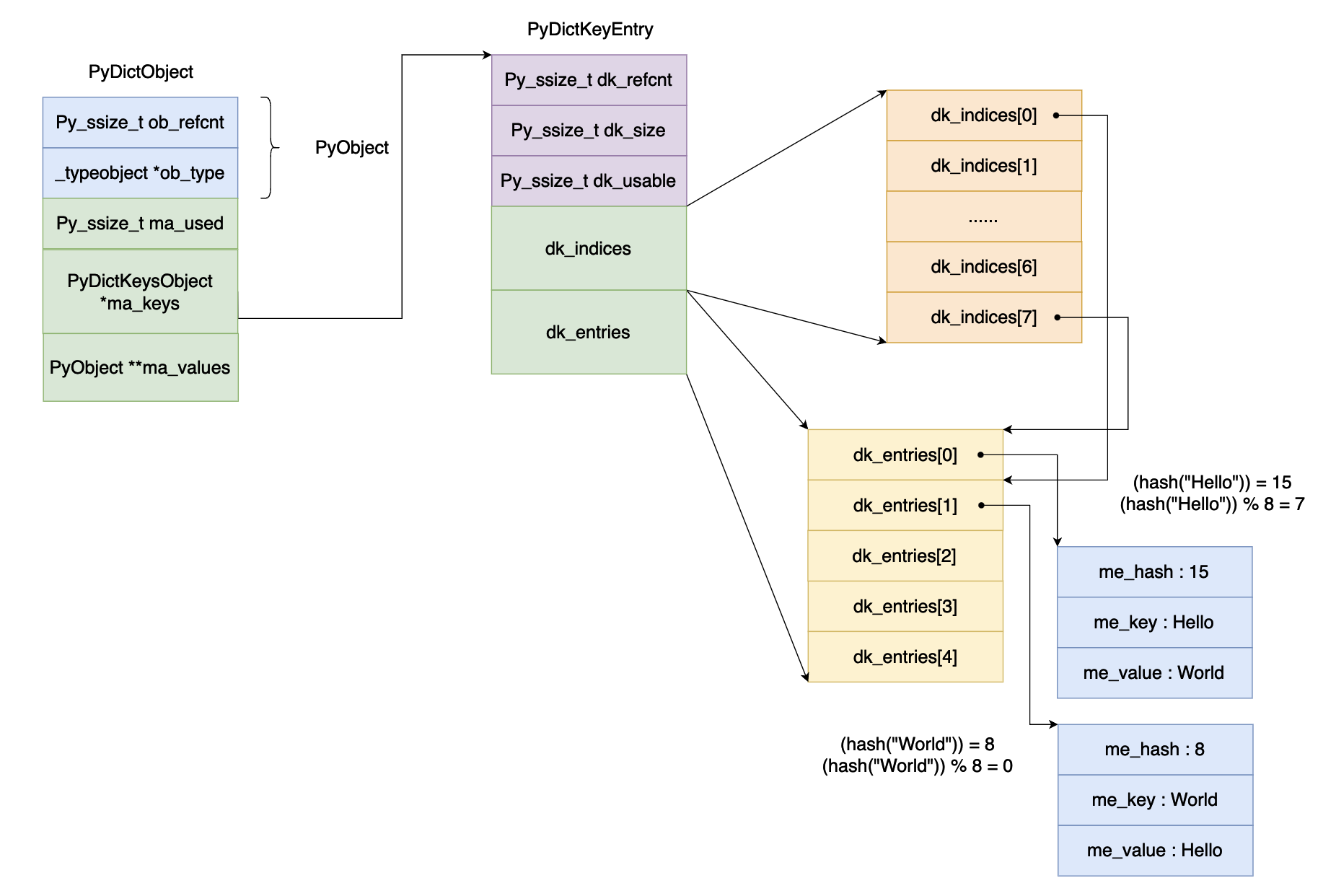
在前面的文章当中我们谈到了,在 cpython 当中 dk_entries 数组当中的一个对象占用 24 字节的内存空间,在 cpython 当中的负载因子是 \(\frac{2}{3}\) 。而一个 entry 的大小是 24 个字节,如果 dk_entries 的长度是 1024 的话,那么大概有 1024 / 3 * 24 = 8K 的内存空间是浪费的。为了解决这个问题,在新版的 cpython 当中采取了一个策略用于减少内存的使用。具体的设计如下图所示:

在新的字典当中 cpython 对于 dk_entries 来说如果正常的哈希表的长度为 8 的话,因为负载因子是 \(\frac{2}{3}\) 真正给 dk_entries 分配的长度是 5 = 8 / 3,那么现在有一个问题就是如何根据不同的哈希值进行对象的存储。dk_indices 就是这个作用的,他的长度和真正的哈希表的长度是一样的,dk_indices 是一个整型数组这个数组保存的是要保存对象在 dk_entries 当中的下标,比如在上面的例子当中 dk_indices[7] = 0,就表示哈希值求余数之后的值等于 7,0 表示对象在 dk_entries 当中的下标。
现在我们再插入一个数据 "World" "Hello" 键值对,假设 "World" 的哈希值等于 8,那么对哈希值求余数之后等于 0 ,那么 dk_indices[0] 就是保存对象在 dk_entries 数组当中的下标的,图中对应的下标为 1 (因为 dk_entries 数组当中的每个数据都要使用,因此直接递增即可,下一个对象来的话就保存在 dk_entries 数组的第 3 个(下标为 2)位置)。
内存分析
首先我们先来分析一下数组 dk_indices 的数据类型,在 cpython 的内部实现当中并没有一刀切的直接将这个数组当中的数据类型设置成 int 类型。
dk_indices 数组主要有以下几个类型:
- 当哈希表长度小于 0xff 时,dk_indices 的数据类型为 int8_t ,即一个元素值占一个字节。
- 当哈希表长度小于 0xffff 时,dk_indices 的数据类型为 int16_t ,即一个元素值占 2 一个字节。
- 当哈希表长度小于 0xffffffff 时,dk_indices 的数据类型为 int32_t ,即一个元素值占 4 个字节。
- 当哈希表长度大于 0xffffffff 时,dk_indices 的数据类型为 int64_t ,即一个元素值占 8 个字节。
与这个相关的代码如下所示:
/* lookup indices. returns DKIX_EMPTY, DKIX_DUMMY, or ix >=0 */
static inline Py_ssize_t
dictkeys_get_index(const PyDictKeysObject *keys, Py_ssize_t i)
{
Py_ssize_t s = DK_SIZE(keys);
Py_ssize_t ix;
if (s <= 0xff) {
const int8_t *indices = (const int8_t*)(keys->dk_indices);
ix = indices[i];
}
else if (s <= 0xffff) {
const int16_t *indices = (const int16_t*)(keys->dk_indices);
ix = indices[i];
}
#if SIZEOF_VOID_P > 4
else if (s > 0xffffffff) {
const int64_t *indices = (const int64_t*)(keys->dk_indices);
ix = indices[i];
}
#endif
else {
const int32_t *indices = (const int32_t*)(keys->dk_indices);
ix = indices[i];
}
assert(ix >= DKIX_DUMMY);
return ix;
}
现在来分析一下相关的内存使用情况:
| 哈希表长度 | 能够保存的键值对数目 | 老版本 | 新版本 | 节约内存量(字节) |
|---|---|---|---|---|
| 256 | 256 * 2 / 3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2 / 3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
从上面的表格我们可以看到哈希表的长度越大我们节约的内存就越大,优化的效果就越明显。
总结
在本篇文章当中主要介绍了在 python3 当中对于字典的优化操作,主要是通过一个内存占用量比较小的数组去保存键值对在真实保存键值对当中的下标实现的,这个方法对于节约内存的效果是非常明显的。
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址:https://github.com/Chang-LeHung/dive-into-cpython
更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
深入理解 Python 虚拟机:字典(dict)的优化的更多相关文章
- python基础——字典dict
1.概念: (1)字典dict,是一系列的键—值对.每个键key都和一个值value相映射.(字典是python中唯一的映射类型.) (2)每一项item,是一个键值对key—value对. (3)键 ...
- python基础——字典(dict)
字典是另一种可变容器模型,且可存储任意类型对象. 字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 . dict1 = {} ...
- python之字典(dict)创建与使用
字典(dict) 在其他语言中被称为哈希映射(hash map)或者相关数组,它是一种大小可变的键值对集,其中的key.value都是python对象. 特别注意: 1.字典中的key不能重复,key ...
- python中字典dict的操作
字典可存储任意类型的对象,由键和值(key - value)组成.字典也叫关联数组或哈希表. dict = {' , 'C' : [1 , 2 , 3] } dict['A'] = 007 # 修改字 ...
- Python中字典dict
dict字典 字典是一种组合数据,没有顺序的组合数据,数据以键值对形式出现 # 字典的创建 # 创建空字典1 d = {} print(d) # 创建空字典2 d = dict() print(d) ...
- python基础-字典dict
字典-dict 用途: 定义方法:通过{} 来存储数据,通过key:value (键值对)来存储数据,每个键值对通过逗号分隔.在键值对中,key 是不可变的数据类型,value 是任意数据类型 def ...
- python数据类型:字典dict常用操作
字典是Python语言中的映射类型,他是以{}括起来,里面的内容是以键值对的形式储存的: Key: 不可变(可哈希)的数据类型.并且键是唯一的,不重复的. Value:任意数据(int,str,boo ...
- Python的字典dict和set
Python内置了字典:dict的支持,dict全称dictionary: 表达式为dict{key,value} 使用键值对来存储数据 eg: 使用dict来存储姓名和分数 d = {'bob':2 ...
- Python基础:字典(dict)与集合(set)
查找场景下与列表的性能对比 字典与集合之所以高效的原因是:内部结构都是一张哈希表. 平均情况下插入.查找和删除的时间复杂度为 O(1). 假设有数量100,000的产品列表: import time ...
- Python操作字典(dict)
一.字典定义 >>> dict={} 二.字典元素添加 >>> dict['性别']='男' >>> dict {'性别': '男'} >& ...
随机推荐
- 创建Django项目的两种方式
有两种方式可创建django项目: 方式一:命令行 1. cmd 命令行,进入到指定的目录,执行:django-admin startproject mydiary [mydiary 为项目名],创建 ...
- anaconda的环境变量
参考: (40条消息) Anaconda 环境变量手动设置(详细)_一夜星尘的博客-CSDN博客_anaconda环境变量手动设置
- P1138 第 k 小整数
P1138 第 k 小整数 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) dalao 勿喷,适合新手 思路就是排序加查重,最后判断第k小数.思路十分简单. 刚开始我一直想二维循环查 ...
- torch直接更改参数
使用model.layer1.weight.data.copy_(w1) 其中model是自定义的参数名字,layer1是某个具体的层,使用某个具体的w1来修改
- 关于Python文件读取时,默认把\r\n换成\n
Python在非二进制形式读取文件时,自动把\r\n换成\n.(window下换行是\r\n) 建立一个test1.txt文件, aaaa bbbb 1.在utf8方式下读取 读取四个字符 1 f=o ...
- 项目:口令保管箱,批处理文件配置.bat
#! python3 import sys import pyperclip PASSWORDS = {'email': 'F7minlBDDuvMJuxESSKHFhTxFtjVB6', 'blog ...
- applicationContext使用注解代替
创建一个类SpringConfig @Configuration//证明这个类是spring的配置文件类 @ComponentScan("com.itheima")//扫描的哪些包 ...
- 北京金橙子ezcad2和lmc1控制卡二次开发的动态连接库手册
我要吐槽一下金橙子打电话过去一问三不答.要个手册2.0的不给,只给3.0的.而且态度角度***钻,想尽一切办法让你自己用不了.我又不是要做打标卡,只是做个二次开发.有必要这样吗?反正我是不会推荐用户再 ...
- matlab/simulink中的执行顺序问题
关于在simulink中开发一些硬件环境模型,有时候会碰到一些模块的执行先后顺序问题.比如说在一个通过UDP发送指令命令给客户端,要求发送的指令有先后的时间顺序,只有在前一条命令发送完以后,才可以进行 ...
- 什么是 SpringMvc
SpringMvc 是 spring 的一个模块,基于 MVC 的一个框架,无需中间整合层来整合