《Streaming Systems》第一章: Streaming 101
数据的价值在其产生之后,将随着时间的流逝逐渐降低。因此,为了获得最大化的数据价值,尽可能实时、快速地处理新产生的数据就显得尤为重要。实时数据处理将在越来越多的场景中体现出更大的价值所在 —— 实时即未来。
什么是流?
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式产生的。只不过受限于数据处理手段,流式数据最终被积累成批,存储到数据库或文件系统中,以供后续的查询分析。
这就是大部分静态数据处理程序的基础架构,查询和分析的结果是滞后于数据产生很多时间的,更糟糕的是,当有新的数据到达时,查询和分析往往需要拉取全量的数据以更新统计结果,随着数据量累积越来越大,查询分析过程显得越来越笨重、耗时。
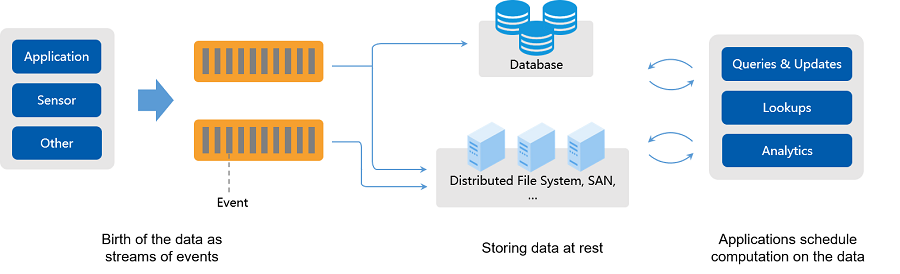
流式数据的特点是:没有预定的开始或结束,即无界,至少理论上来说,它的输入永远不会结束,这就要求流处理系统能够持续不断地对新到达的数据进行处理。因此流处理系统是指能处理无界数据集的数据处理系统。
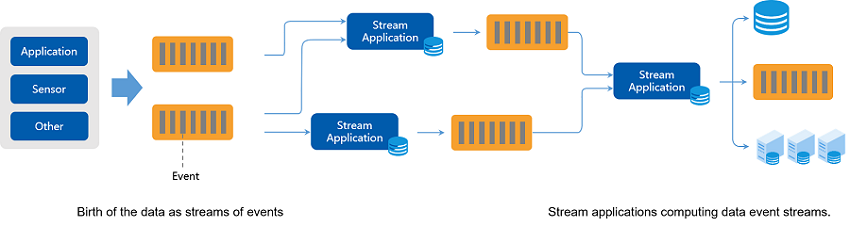
流处理程序具有以下特点:
- 流处理程序从流中接收到事件时,即可对该事件做出反应:可以触发动作,更新聚合或其他统计,或 “记住” 该事件以供将来参考。
- 一个数据流可以分流给多个流计算程序,一个流计算程序也可以联合处理多个数据流,对数据流的每次计算都可能产生其他事件数据流。
- 流处理允许开发人员构建应用程序,使用分析结果来响应数据中的洞察力——直接采取行动。例如,基于分析模型将银行交易分类为欺诈,然后自动阻止交易;根据传感器数据的实时分析结果调整机器的参数;根据有关用户行为的模型向用户发送推送通知。
被极度夸大的流处理的局限性
在很长一段时间里,很多针对流系统的论述都是低延时但是结果不精确,反之批处理才能提供精确的计算结果,这其实都是对流计算系统的误解。来看一下流处理系统的发展过程:
第一代流处理引擎(2011 年)专注以毫秒级延迟处理数据并保证系统故障时事件不丢失,但是未对流式应用结果的准确性和一致性提供内置保障。和批处理引擎相比,第一代流处理引擎通过牺牲结果的准确性来换取低延迟,以当时的眼光看待流处理,计算快速和结果准确二者不可兼得,因此才有了所谓的 Lambda 架构。
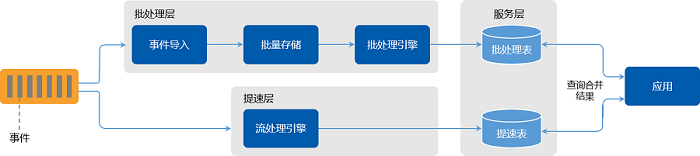
Lambda 架构在传统周期性批处理架构的基础上添加了一个由低延迟流处理引擎所驱动的 “提速层”。到来的数据会同时发往流处理引擎和写入批量存储。流处理引擎会近乎实时地计算出近似结果,并将其写入“提速表” 中。批处理引擎周期性地处理批量存储的数据,将精确结果写入批处理表,随后将 “提速表” 中对应的非精确结果删除。为了获取最终结果,应用需要将 “提速表” 中的近似结果和批处理表中的精确结果合并。
Lambda 架构最初是以改善原始批量分析架构中结果的高延迟为目标,然而自身却有很多明显的缺点。首先,该架构需要在拥有不同 API 的两套独立处理系统之上实现两套语义相同的应用逻辑;其次,流处理引擎的计算结果只是近似的;最后,Lambda 架构很难配置和维护。
第二代流处理引擎(2013 年),提供了更加完善的故障处理机制,即便出现故障,也能保证每条记录仅参与一次结果运算。但部分改进(例如更高的吞吐和更完善的故障处理机制)是以增加处理延迟为代价的,并且处理结果仍依赖于事件到来的时间和顺序。
第三代流处理引擎(2015 年)解决了结果对事件到来时间及顺序的依赖问题。不要小看这一特性,这意味着系统只需依靠数据本身计算结果,历史数据当做 “实时” 数据进行处理,流是批的超集,这为 “流处理” 和 “批处理” 的统一奠定了基础。另一项改进是无需让用户在延迟和吞吐之间做出困难的抉择,可以兼顾高吞吐和低延迟。这些特性让人们渐渐意识到,经过良好的设计,流处理系统完全可以保证低延时,并且提供正确的结果。这使得 Lambda 架构彻底沦为历史,流处理系统摘掉了 “快速但不准确” 的帽子。
事件时间 vs. 处理时间
数据处理系统中,通常有两个时间域:
事件时间:事件发生的时间,即业务时间。
处理时间:系统发现事件,开始对事件进行处理的时间。
并非所有场景都关心事件时间,但关心事件时间的场景绝对不在少数。 例如分析用户行为随时间的变化情况、和 money 有关的绝大部分应用、异常检测等等,不一而足。
理想情况下,事件时间和处理时间是相等的,意味着事件一发生就立即被捕获处理。但这毕竟是理想状态,实际上往往受到网络拥堵、共享 CPU 等因素的影响,导致事件时间和处理时间之间会存在偏差。事件时间和处理时间的关系如下图所示:
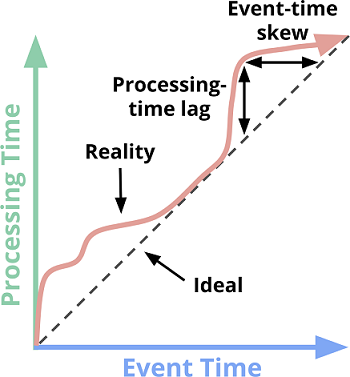
图中横轴为事件时间,纵轴为处理时间。黑色虚线的斜率为 1,表示理想情况下事件时间等于处理时间。红色实线始终位于黑色虚线之上,表示实际情况中处理时间总是大于事件时间。红色实线和黑色虚线的垂直距离表示的含义是:事件发生后经过多久才被系统处理,即系统时滞(Processing-time lag)。红色实线和黑色虚线的水平距离的含义是:系统此刻正在处理的事件和理想情况下系统应该处理的事件之间的时间差(Event-time skew),它表征了系统的实际情况和理想状态之间的差距。
数据处理的一般模式
咱们先来看看目前数据处理的一般模式。先从经典的批处理系统开始,再到专门为流计算设计的系统为止,逐步揭开流处理系统的演进步骤。
有界数据
如何处理有界数据,相信大家都很熟悉了,如下图所示,左边的非结构化数据,经过某种数据处理引擎(例如 MapReduce),变成右边的结构化数据。
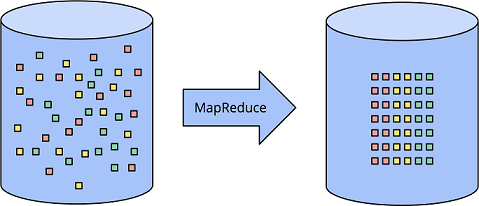
这个模型本身确非常简单,但是能处理的场景非常多。与之相比,无界数据的处理方式就复杂的多了。我们先从典型的批处理系统开始,再到专门为流计算设计的系统为止,来逐步揭开流处理系统演进的步骤。
无界数据:批
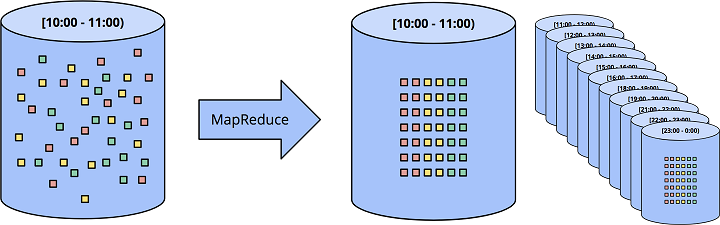
当我们第一次面对无界数据流的时候,首先想到的是使用传统的批处理引擎来处理无界数据流。最常见也最容易想到的办法,就是通过切片的方式,将无界数据流,切分成一个个有界数据集,再进行计算。
固定时间窗口
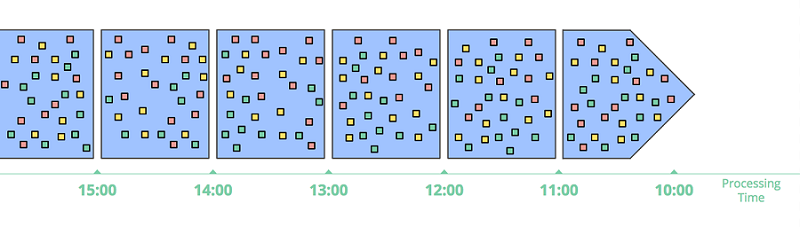
最常用的切片方式,是将数据切成固定大小的窗口(也叫滚动窗口),然后对每个窗口中的数据进行处理。这种方式对源头数据在事件时间上有序的场景是有用的。比如已经被切分成文件的日志等。
在现实世界中,绝大部分场景还是要处理数据完整性问题,因为数据到达流计算系统时可能会迟到,体现是在事件时间上乱序。因此必须有机制能够使这些迟到的数据重新计算,才能保证结果的正确性(比如,等到所有事件都到达时再进行计算,或者,拿到晚到数据时,重新对某个小窗口的数据进行计算)。
会话
固定时间窗口的数据切分方式在处理会话窗口的时候就不再有效了。首先了解下什么是会话(session)和会话窗口(session window)。会话是指一段时间内发生的一系列连续的活动,会话发生的这段时间被称之为会话窗口,会话时间长短不一,因此会话窗口大小不同。当使用固定时间窗口的数据分片方式处理会话数据的时候,很可能将属于一个会话的事件分割到两个不同批次之中(如下图红色标记所示),这无疑会给后续的数据分析带来困难。当然我们可以通过增大每批数据条数,来尽量减少会话窗口被截断的次数,但是这会导致延时增加。当然也可以在分批的时候,使用更复杂的会话检测机制,将同一会话窗口的数据都分在同一批,但这又会增加系统设计的复杂度。
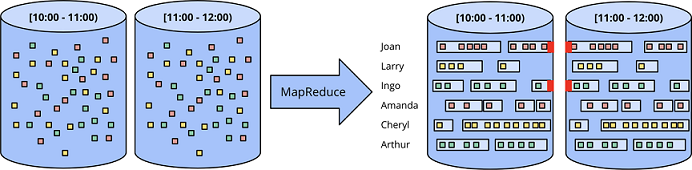
无论何种方式,用传统批处理来处理会话窗口的效果都不好。更优雅的方式是用流系统来处理会话窗口。稍后我们会详细讨论。
无界数据:流
流计算系统是专门为处理无界数据而生的。真实的数据具有以下几个特点:
- 高度无序:在事件时间上,高度无序。如果用户需要按照事件时间顺序分析数据,就需要在时间上做某种数据shuffle。
- 事件时间偏差不固定,也就是不能指望说在某段时间内,事件时间 X 之前的数据都会到齐。
处理以上特点的数据的方式,可以分为 时间无关型 和 时间相关型。典型的时间无关型流处理有过滤、内联等。时间相关型流处理方式有根据处理时间划分窗口、根据事件时间划分窗口。
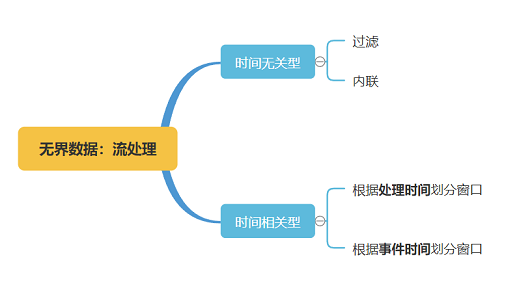
接下来我们分别了解一下各种处理方式:
时间无关
时间无关型流处理方式是最简单的处理方式,所有逻辑都是数据驱动的,流处理引擎除了传递数据之外无需考虑其他。
过滤 是一种典型的时间无关型处理方式。如图 1-5 所示,假设您正在处理网络流量日志,并且想要过滤得到来自特定域的所有流量。方式就是依次查看到达的每条记录,判别其是否属于感兴趣的域,是则保留,否则滤除。这种操作只取决于单个元素,与数据有界、无界以及事件时间偏差都没有关系。
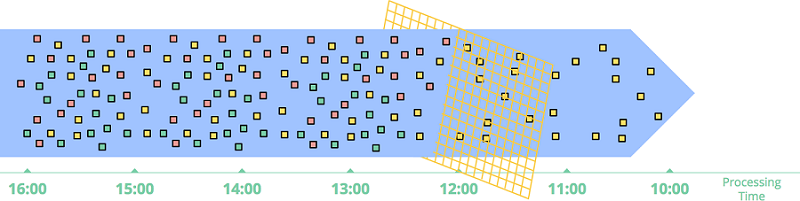
内联 也是一种时间无关型处理方式。当两个流做内联时,需要把两条流的数据都缓存起来,当两边的数据关联上时输出关联结果。当然这种方式要考虑数据 buffer 大小的问题,一般都会按时间来配置数据过期策略。
在做内联的时候,也会面临数据完整性问题:一条流中的数据到了,你怎么知道另一条流中相应的数据是否会到达?实际上,没人能回答这个问题。在实际使用过程中,必须要引入时间的概念。
时间相关
其余两种常用的无界数据的流处理方式,都是窗口的变体,因此我们首先了解一下流处理中的窗口。简单来说,窗口是获得数据源(有界或无界)的概念。窗口将数据源沿着时间边界,切分成有界的数据块,然后对各个数据块进行处理。下图表示了三种窗口类型:
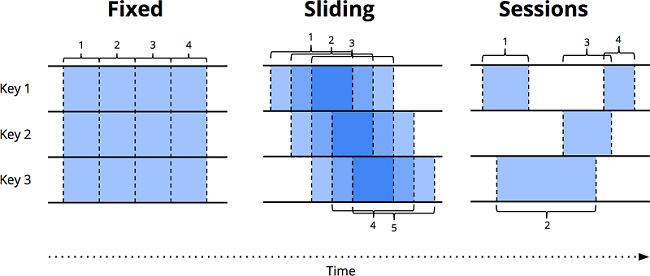
固定窗口(又名滚动窗口)
固定窗口在时间维度上,按照固定长度将无界数据流切片,是一种对齐窗口。窗口紧密排布,首尾无缝衔接,均匀地对数据流进行切分。滑动窗口
滑动时间窗口是固定时间窗口的推广,由窗口大小和窗口间隔两个参数共同决定。当窗口间隔小于窗口大小时,窗口之间会出现重叠;当窗口间隔等于窗口大小时,滑动窗口蜕化为固定窗口;当窗口间隔大于窗口大小时,得到的是一个采样窗口。与固定窗口一样,滑动窗口也是一种对齐窗口。会话窗口
会话窗口是典型的非对齐窗口。会话由一系列连续发生的事件组成,当事件发生的间隔超过某个超时时间时,意味着一个会话的结束。会话很有趣,例如,我们可以通过将一系列时间相关的事件组合在一起来分析用户的行为。会话的长度不能先验地定义,因为会话长度在不同的数据集之间永远不会相同。
Window 可作用于事件时间和处理时间两个时间域。作用于处理时间更常见,我们先来讨论作用于处理时间的窗口。
根据处理时间划分窗口 时,系统需要缓存一定时间的数据。例如,固定窗口大小设置为五分钟时,系统将缓存五分钟的数据,之后将在这五分钟内观察到的所有数据视为一个窗口,将它们发送到下游进行处理。
根据处理时间划分窗口有如下优点:
简单。使用和理解都非常简单,也不涉及数据晚到的问题。仅仅是将数据缓存一段时间再发到下游进行处理。
窗口数据的完整性很容易判别。没有所谓数据晚到的问题了。因为系统能够根据处理时间精确判断窗口是否结束。
如果要推断出数据源的某些信息,处理时间窗口非常合适。许多监控类的需求都适宜选择这种窗口。比如要计算一个全球范围的 web 服务的每秒的流量,来监控服务是否正常。
根据事件时间划分窗口 的方式在事件本身的发生时间备受关注时显得格外重要。下图所示为将无界数据根据事件时间切分成 1 小时固定时间窗口:
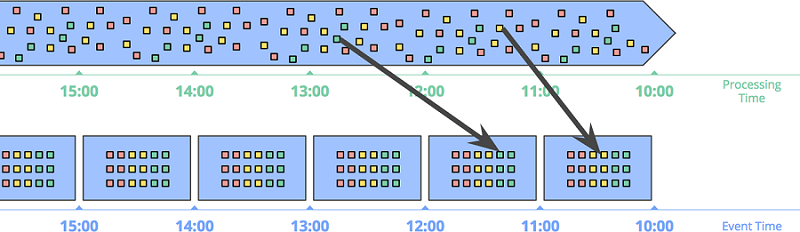
要特别注意箭头中所示的两个事件,两个事件根据处理时间所在的窗口,跟事件时间发生的窗口不是同一个。如果基于处理时间划分窗口的话,结果就是错的。只有基于事件时间进行计算,才能保证数据的正确性。
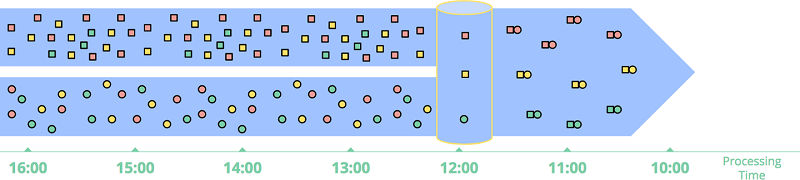
另一个基于事件时间窗口的好处是可以创建动态大小的窗口,比如会话窗口,避免出现上文 无界数据:批 章节例子中所提到的现象:一个 session 窗口的数据,由于窗口大小固定,被切分到不同窗口中,对下游计算造成障碍。
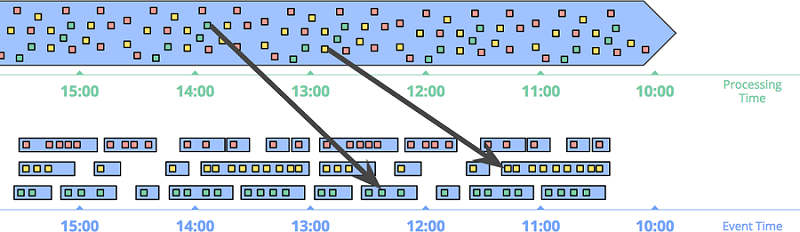
当然,天下没有免费的午餐。事件时间窗口功能很强大,但由于迟到数据的原因,窗口的存在时间比窗口本身的大小要长很多,导致的两个明显的问题是:
缓存:事件时间窗口需要存储更长时间内的数据。
完整性:基于事件时间的窗口,我们也不能判断什么时候窗口的数据都到齐了。很多系统,如 MillWheel,Flink 通过 watermark,能够推断一个相对精确的窗口结束时间。但是这种方式并不能得到完全正确的结果。因此,解决这个问题的更好的方式,应该是让用户能定义何时输出窗口结果,并且定义当迟到数据到来时,如何更新之前窗口计算的结果。
本章小结
在本章中,我们完成了以下工作:
- 澄清了一些术语的定义,专注于‘流’的定义,而不是已有流计算系统的实现。
- 研究了目前 批/流 系统的能力,强调,在功能上,流是批的超集。
- 提出了如果流系统在功能上要超越批系统,需要具备的两个能力,分别是:正确性和在各时间域处理数据的能力。
- 强调了事件时间和处理时间的巨大区别。提出了基于这两个时间处理数据的难点。
- 回顾了主流数据处理系统处理有界和无界数据的方式。
参考
[1] 《Streaming System》 第一章:Streaming 101
[2] What is Stream Processing?
《Streaming Systems》第一章: Streaming 101的更多相关文章
- 《Streaming Systems》第二章: 数据处理中的 What, Where, When, How
本章中,我们将通过对 What,Where,When,How 这 4 个问题的回答,逐步揭开流处理过程的全貌. What:计算什么结果? 也就是我们进行数据处理的目的,答案是转换(transforma ...
- 《Streaming Systems》第三章: Watermarks
定义 对于一个处理无界数据流的 pipeline 而言,非常需要一个衡量数据完整度的指标,用于标识什么时候属于某个窗口的数据都已到齐,窗口可以执行聚合运算并放心清理,我们暂且就给它起名叫 waterm ...
- Streaming Systems笔记
一直心心念的<Streaming Systems>终于有了影印版本,京东110块钱果断买了,很惊喜还是彩印版本. 挖个坑,书看完后写一篇关于流式处理总结的笔记,大体翻看了一遍,总体来说流式 ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第一章:向量代数
原文:Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第一章:向量代数 学习目标: 学习如何使用几何学和数字描述 Vecto ...
- Stealth视频教程学习笔记(第一章)
Stealth视频教程学习笔记(第一章) 本文是对Unity官方视频教程Stealth的学习笔记.在此之前,本人整理了Stealth视频的英文字幕,并放到了优酷上.本文将分别对各个视频进行学习总结,提 ...
- .net架构设计读书笔记--第一章 基础
第一章 基础 第一节 软件架构与软件架构师 简单的说软件架构即是为客户构建一个软件系统.架构师随便软件架构应运而生,架构师是一个角色. 2000年9月ANSI和IEEE发布了<密集性软件架构建 ...
- 简学Python第一章__进入PY的世界
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- python全栈第一章
第一章 Python基础变量定义规则:1.变量名只能是字母数字或者下划线的任意组合2.变量名的第一个字符不能是数字3.关键字不能申明为变量名定义方式:1.驼峰体AgeOfSzp2.下划线隔开Age_o ...
随机推荐
- Spring 和 SpringBoot 有什么不同?
Spring 框架提供多种特性使得 web 应用开发变得更简便,包括依赖注入.数据绑定.切面编程.数据存取等等. 随着时间推移,Spring 生态变得越来越复杂了,并且应用程序所必须的配置文件也令人觉 ...
- 如何给Spring 容器提供配置元数据?
这里有三种重要的方法给Spring 容器提供配置元数据. XML配置文件. 基于注解的配置. 基于java的配置.
- mybatis源码之我见
以前一直想看mybatis的源代码,但是一直没找到入口(傻),最近看教程,有些感悟. 和起以前一样,关键代码我会用红色标记. 首先,先贴下我的dao和mapper,代码很简单,和平时写的hello w ...
- Spark学习摘记 —— RDD转化操作API归纳
本文参考 在阅读了<Spark快速大数据分析>动物书后,大概了解到了spark常用的api,不过书中并没有给予所有api具体的示例,而且现在spark的最新版本已经上升到了2.4.5,动物 ...
- 深入理解FIFO(包含有FIFO深度的解释)
FIFO: 一.先入先出队列(First Input First Output,FIFO)这是一种传统的按序执行方法,先进入的指令先完成并引退,跟着才执行第二条指令. 1.什么是FIFO? FIFO是 ...
- Linux下切换python2和python3
为什么需要有两个版本的Python Python2和Python3不兼容是每个接触过Python的开发者都知道的事,虽说Python3是未来,但是仍然有很多项目采用Python2开发.Linux的许多 ...
- Clickhouse 纯手工迁移表
[应用场景] 由于一些未可知的原因,导致原表不可用,也不能恢复.通过手动迁移的方法来恢复业务 [解决办法] 新建一张 copy 表,把原表的 data 目录复制到新表的data 目录,并 attach ...
- ubantu之Git使用
本文讲述在Ubuntu 14.04 x64环境下,如何安装Git,配置连接GitHub,并且上传本地代码到github. 一. 注册Git账户以及创建仓库 要想使用github第一步当然是注册gith ...
- Android Studio登陆界面+Button不变色问题
今日所学内容: 1.初始相对布局 2.AS登录界面 3.一个可以下载小图标的阿里的网站iconfont-阿里巴巴矢量图标库 用GitHub账号绑定就可以免费下载 4.取颜色工具ColorCop 遇到的 ...
- Java中switch语句+例题输出当前月份
学习目标: 掌握switch的使用 学习内容: 1.switch语法 <font color=#000000 size=3> switch(表达式) { case 常量1: 语句体1; b ...