全网最详细中英文ChatGPT接口文档(四)30分钟快速入门ChatGPT——Models模型
@

Models
Overview 概述
The OpenAI API is powered by a diverse set of models with different capabilities and price points. You can also make limited customizations to our original base models for your specific use case with fine-tuning.
OpenAI API由一组具有不同功能和价位的模型提供支持。您还可以通过微调针对您的特定使用情形对我们的原始基本模型进行有限的自定义。

We have also published open source models including Point-E, Whisper, Jukebox, and CLIP.
我们还发布了开源模型,包括Point-E、Whisper、Jukebox和CLIP。
Visit our model index for researchers to learn more about which models have been featured in our research papers and the differences between model series like InstructGPT and GPT-3.5.
请访问我们的模型索引,以了解更多关于我们的研究论文中介绍了哪些模型,以及InstructGPT和GPT-3.5等模型系列之间的差异。
GPT-4 Limited beta
GPT-4 is a large multimodal model (accepting text inputs and emitting text outputs today, with image inputs coming in the future) that can solve difficult problems with greater accuracy than any of our previous models, thanks to its broader general knowledge and advanced reasoning capabilities. Like gpt-3.5-turbo, GPT-4 is optimized for chat but works well for traditional completions tasks.
GPT-4是一个大型的多模态模型(今天接受文本输入并输出文本,未来会有图像输入),由于其更广泛的一般知识和先进的推理能力,它可以比我们以前的任何模型更准确地解决难题。与 gpt-3.5-turbo 一样,GPT-4也针对聊天进行了优化,但也适用于传统的完成任务。
GPT-4 is currently in a limited beta and only accessible to those who have been granted access. Please join the waitlist to get access when capacity is available.
GPT-4目前处于有限的测试阶段,只有那些被授予访问权限的人才能访问。请加入等待名单,以便在容量可用时获得访问权限。

For many basic tasks, the difference between GPT-4 and GPT-3.5 models is not significant. However, in more complex reasoning situations, GPT-4 is much more capable than any of our previous models.
对于许多基本任务,GPT-4和GPT-3. 5模型之间的差异并不显著。然而,在更复杂的推理情况下,GPT-4比我们以前的任何模型都要强大得多。
GPT-3.5
GPT-3.5 models can understand and generate natural language or code. Our most capable and cost effective model in the GPT-3.5 family is gpt-3.5-turbo which has been optimized for chat but works well for traditional completions tasks as well.
GPT-3.5模型可以理解并生成自然语言或代码。GPT-3.5系列中功能最强大、最具成本效益的模型是 gpt-3.5-turbo ,它已针对聊天进行了优化,但也适用于传统的完成任务。

We recommend using gpt-3.5-turbo over the other GPT-3.5 models because of its lower cost.
我们建议使用 gpt-3.5-turbo 而不是其他GPT-3.5模型,因为它的成本更低。
OpenAI models are non-deterministic, meaning that identical inputs can yield different outputs. Setting temperature to 0 will make the outputs mostly deterministic, but a small amount of variability may remain.
OpenAI模型是不确定的,这意味着相同的输入可能产生不同的输出。将温度设置为0将使输出基本上具有确定性,但可能仍存在少量变化。
Feature-specific models 特定功能的模型
While the new gpt-3.5-turbo model is optimized for chat, it works very well for traditional completion tasks. The original GPT-3.5 models are optimized for text completion.
虽然新的 gpt-3.5-turbo 模型针对聊天进行了优化,但它对传统的完成任务也非常有效。原始GPT-3.5模型针对文本完成进行了优化。
Our endpoints for creating embeddings and editing text use their own sets of specialized models.
我们用于创建嵌入和编辑文本的端点使用它们自己的专用模型集。
Finding the right model 寻找合适的模型
Experimenting with gpt-3.5-turbo is a great way to find out what the API is capable of doing. After you have an idea of what you want to accomplish, you can stay with gpt-3.5-turbo or another model and try to optimize around its capabilities.
试验 gpt-3.5-turbo 是了解API功能的好方法。当你对你想要完成的事情有了一个想法之后,你可以继续使用 gpt-3.5-turbo 或其他模型,并尝试围绕它的功能进行优化。
You can use the GPT comparison tool that lets you run different models side-by-side to compare outputs, settings, and response times and then download the data into an Excel spreadsheet.
您可以使用GPT比较工具,该工具允许您并行运行不同的模型,以比较输出、设置和响应时间,然后将数据下载到Excel电子表格中。
DALL·E Beta
DALL·E is a AI system that can create realistic images and art from a description in natural language. We currently support the ability, given a prommpt, to create a new image with a certain size, edit an existing image, or create variations of a user provided image.
DALL·E是一个人工智能系统,可以从自然语言的描述中创造出逼真的图像和艺术。我们目前支持的能力,给予提示,以创建一个新的图像与一定的大小,编辑现有的图像,或创建一个用户提供的图像的变化。
The current DALL·E model available through our API is the 2nd iteration of DALL·E with more realistic, accurate, and 4x greater resolution images than the original model. You can try it through the our Labs interface or via the API.
通过我们的API提供的当前DALL·E模型是DALL·E的第二次迭代,具有比原始模型更真实、更准确和分辨率高4倍的图像。您可以通过我们的实验室界面或通过API进行尝试。
Whisper Beta
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification. The Whisper v2-large model is currently available through our API with the whisper-1 model name.
Whisper是一种通用的语音识别模型。它是在一个大的数据集上训练的,并且是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。Whisper v2-large模型目前可通过我们的API获得,模型名称为 whisper-1 。
Currently, there is no difference between the open source version of Whisper and the version available through our API. However, through our API, we offer an optimized inference process which makes running Whisper through our API much faster than doing it through other means. For more technical details on Whisper, you can read the paper.
目前,Whisper的开源版本和通过我们的API提供的版本之间没有区别。然而,通过我们的API,我们提供了一个优化的推理过程,这使得通过我们的API运行Whisper比通过其他方式快得多。想了解更多关于Whisper的技术细节,你可以阅读报纸。
Embeddings 嵌入
Embeddings are a numerical representation of text that can be used to measure the relateness between two pieces of text. Our second generation embedding model, text-embedding-ada-002 is a designed to replace the previous 16 first-generation embedding models at a fraction of the cost. Embeddings are useful for search, clustering, recommendations, anomaly detection, and classification tasks. You can read more about our latest embedding model in the announcement blog post.
嵌入是文本的数字表示,可用于度量两段文本之间的相关性。我们的第二代嵌入模型 text-embedding-ada-002 旨在以很小的成本取代之前的16个第一代嵌入模型。嵌入对于搜索、聚类、推荐、异常检测和分类任务非常有用。您可以在公告博客中阅读更多关于我们最新嵌入模型的信息。
Codex Limited beta
The Codex models are descendants of our GPT-3 models that can understand and generate code. Their training data contains both natural language and billions of lines of public code from GitHub. Learn more.
Codex模型是GPT-3模型的后代,可以理解和生成代码。他们的训练数据既包含自然语言,也包含来自GitHub的数十亿行公共代码。 了解更多信息。
They’re most capable in Python and proficient in over a dozen languages including JavaScript, Go, Perl, PHP, Ruby, Swift, TypeScript, SQL, and even Shell.
他们最擅长Python,精通十几种语言,包括JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL,甚至Shell。
We currently offer two Codex models:
我们目前提供两种Codex模型:

For more, visit our guide on working with Codex.
欲了解更多信息,请访问我们的Codex使用指南。
Moderation 审核
The Moderation models are designed to check whether content complies with OpenAI's usage policies. The models provide classification capabilities that look for content in the following categories: hate, hate/threatening, self-harm, sexual, sexual/minors, violence, and violence/graphic. You can find out more in our moderation guide.
审核模型被设计用来检查内容是否符合OpenAI的使用策略。这些模型提供了分类功能,可按以下类别查找内容:仇恨、仇恨/威胁、自残、性、性/未成年人、暴力和暴力/图形。您可以在我们的审核指南中找到更多信息。
Moderation models take in an arbitrary sized input that is automatically broken up to fix the models specific context window.
审核模型接受任意大小的输入,这些输入被自动分解以修复模型特定的上下文窗口。

GPT-3
GPT-3 models can understand and generate natural language. These models were superceded by the more powerful GPT-3.5 generation models. However, the original GPT-3 base models (davinci, curie, ada, and babbage) are current the only models that are available to fine-tune.
GPT-3模型能够理解和生成自然语言。这些型号被更强大的GPT-3.5代模型所取代。但是,原始GPT-3基本模型(davinci、 curie 、 ada 和 babbage )是当前唯一可进行微调的模型。

Model endpoint compatibility 模型端点兼容性

This list does not include our first-generation embedding models nor our DALL·E models.
此列表不包括我们的第一代嵌入模型和DALL·E模型。
Continuous model upgrades 持续模型升级
With the release of gpt-3.5-turbo, some of our models are now being continually updated. In order to mitigate the chance of model changes affecting our users in an unexpected way, we also offer model versions that will stay static for 3 month periods. With the new cadence of model updates, we are also giving people the ability to contribute evals to help us improve the model for different use cases. If you are interested, check out the OpenAI Evals repository.
随着 gpt-3.5-turbo 的发布,我们的一些模型现在正在不断更新。为了减少模型更改以意外方式影响用户的可能性,我们还提供了将在3个月内保持静态的模型版本。随着模型更新的新节奏,我们还让人们能够贡献评估,以帮助我们针对不同的用例改进模型。如果您感兴趣,请查看OpenAI Evals存储库。
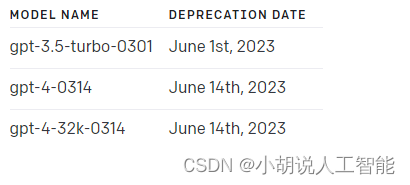
The following models are the temporary snapshots that will be deprecated at the specified date. If you want to use the latest model version, use the standard model names like gpt-4 or gpt-3.5-turbo.
以下模型是将在指定日期弃用的临时快照。如果要使用最新的模型版本,请使用标准模型名称,如 gpt-4 或 gpt-3.5-turbo 。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
全网最详细中英文ChatGPT接口文档(四)30分钟快速入门ChatGPT——Models模型的更多相关文章
- rbac介绍、自动生成接口文档、jwt介绍与快速签发认证、jwt定制返回格式
今日内容概要 RBAC 自动生成接口文档 jwt介绍与快速使用 jwt定制返回格式 jwt源码分析 内容详细 1.RBAC(重要) # RBAC 是基于角色的访问控制(Role-Based Acces ...
- django接口文档自动生成
django-rest_framework接口文档自动生成 只针对用到序列化和返序列化 一般还是用第三方yipi 一.安装依赖 pip3 install coreapi 二.设置 setting.py ...
- 在.Net Core中使用Swagger制作接口文档
在实际开发过程中后台开发人员与前端(移动端)接口的交流会很频繁.所以需要一个简单的接口文档让双方可以快速定位到问题所在. Swagger可以当接口调试工具也可以作为简单的接口文档使用. 在传统的asp ...
- Django使用swagger生成接口文档
参考博客:Django接入Swagger,生成Swagger接口文档-操作解析 Swagger是一个规范和完整的框架,用于生成.描述.调用和可视化RESTful风格的Web服务.总体目标是使客户端和文 ...
- ShiWangMeSDK Android版接口文档 0.2.0 版
# ShiWangMeSDK Android版接口文档 0.2.0 版 android 总共有 14 个接口,分别涉及到初始化和对界面的一些细节的控制.下面详细介绍接口,如果没有特殊说明,接口都在 S ...
- 使用swagger实现web api在线接口文档
一.前言 通常我们的项目会包含许多对外的接口,这些接口都需要文档化,标准的接口描述文档需要描述接口的地址.参数.返回值.备注等等:像我们以前的做法是写在word/excel,通常是按模块划分,例如一个 ...
- SpringBoot整合Swagger2,再也不用维护接口文档了!
前后端分离后,维护接口文档基本上是必不可少的工作.一个理想的状态是设计好后,接口文档发给前端和后端,大伙按照既定的规则各自开发,开发好了对接上了就可以上线了.当然这是一种非常理想的状态,实际开发中却很 ...
- Asp.Net Core 轻松学-利用 Swagger 自动生成接口文档
前言 目前市场上主流的开发模式,几乎清一色的前后端分离方式,作为服务端开发人员,我们有义务提供给各个客户端良好的开发文档,以方便对接,减少沟通时间,提高开发效率:对于开发人员来说,编写接口文档 ...
- webapi 利用webapiHelp和swagger生成接口文档
webapi 利用webapiHelp和swagger生成接口文档.均依赖xml(需允许项目生成注释xml) webapiHelp:微软技术自带,仅含有模块.方法.请求-相应参数的注释. swagge ...
- 使用sphinx制作接口文档并托管到readthedocs
此sphinx可不是彼sphinx,此篇是指生成文档的工具,是python下最流行的文档生成工具,python官方文档即是它生成,官方网站是http://www.sphinx-doc.org,这里是一 ...
随机推荐
- JS篇(005)-== 和 === 的不同
答案:==是抽象相等运算符,而===是严格相等运算符.==运算符是在进行必要的类型转换后,再比较.===运算符不会进行类型转换,所以如果两个值不是相同的类型,会直接返回false.使用==时,可能发生 ...
- 错题记录:C51同一个hex文件偶尔效果不行 的处理方法
51单片机很多方面和C语言有区别,经验下来,总结以下:1.关于变量报错:报错的原因大多是因为编译器C++版本不同,所以变量我都推荐使用驼峰命名法;2.如果同一个hex文件,或者改的代码自己认为没问题 ...
- nebula命令行无法查看配置信息
版本为nebula2.0.1 正在部署集群,节点数比较多,直接在一个节点配置好配置文件,分发到其他节点, 为了减少后续修改配置文件时再为配置文件添加--local_config=true,所以直接加上 ...
- 创建一个简单的signalr项目
1:新建一个empty的MVC项目 2:如果没有安装过signalr过那么要通过Nuget安装signalr 3:新建一个controller 然后建一个view =>index 4:新建一个s ...
- 学习笔记||使用Vue时踩过的坑1.0
vue介绍:https://cn.vuejs.org/v2/guide/ 1.安装npm install时,长时间停留在fetchMetadata: sill mapToRegistry uri ht ...
- 打包python文件为exe程序 vscode
一.项目下虚拟环境下载pyinstaller.exe 打包 1.检查是否下载 pyinstaller: 如果没有在vscode终端输入:pip3 install pyinstaller 安装成功后下 ...
- HTTP-看这一篇就够了
HTTP和HTTPS有什么区别 1.传输过程中信息是否加密,HTTP是超文本传输协议,信息是明文传输,HTTPS是具有安全性的SSL加密的超文本传输协议,信息是加密传输: 2.服务端使用的端口号不一致 ...
- Linux软件防火墙iptables
Netfilter组件 内核空间,集成在linux内核中 官网文档:https://netfilter.org/documentation/ 扩展各种网络服务的结构化底层框架 内核中选取五个位置放了五 ...
- nuxt,js中关于服务端不能使用localStorage和cookie的解决方案
参考链接:https://www.npmjs.com/package/cookie-universal-nuxt 1.安装下载 npm i --save cookie-universal-nuxt 2 ...
- P1296 奶牛的耳语
P1296 奶牛的耳语 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 本题核心思路: 1.读入后要排序以达到剪枝的目的 2.模拟,遇到不能再交流就转入下一头牛,否则计数器加一 3. ...