深度优先搜索算法-dfs讲解
迷宫问题
有一个迷宫:
S**.
....
***T
(其中字符S表示起点,字符T表示终点,字符*表示墙壁,字符.表示平地。你需要从S出发走到T,每次只能向上下左右相邻的位置移动,不能走出地图,也不能穿过墙壁,每个点只能通过一次。)
现在需要你求出是否可以走出这个迷宫
我们将这个走迷宫过程称为dfs(深度优先搜索)算法。
思路
当我们搜索到了某一个点,有这样3种情况:
1.当前我们所在的格子就是终点。
2.如果不是终点,我们枚举向上、向下、向左、向右四个方向,依次去判断它旁边的四个点是否可以作为下一步合法的目标点,如果可以,那么我们就进行这一步,走到目标点,然后继续进行操作。
3.当然也有可能我们走到了“死胡同”里(上方、下方、左方、右方四个点都不是合法的目标点),那么我们就回退一步,然后从上一步所在的那个格子向其他未尝试的方向继续枚举。
怎样才能算“合法的目标点”?
1.必须在所给定的迷宫范围内
2.不能是迷宫边界或墙。
3.这个点在搜索过程中没有被走过(这样做是因为,如果一个点被允许多次访问,那么肯定会出现死循环的情况——在两个点之间来回走。)
实现代码
#include <iostream>
using namespace std;
int n, m;
string maze[105];
int sx, sy;
bool vis[105][105];
int dir[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};//四个方向的方向数组
bool in(int x, int y) {
return 0 <= x && x < n && 0 <= y && y < m;
}
bool dfs(int x, int y) {
vis[x][y] = 1;//点已走过标记
if (maze[x][y] == 'T') {//到达终点
return 1;
}
for (int i = 0; i < 4; ++i) {
int tx = x + dir[i][0];
int ty = y + dir[i][1];
if (in(tx, ty) && !vis[tx][ty] && maze[tx][ty] != '*') {
/*
1.in(tx, ty) : 即将要访问的点在迷宫内
2.!vis[tx][ty] : 点没有走过
3.maze[tx][ty] != '*' : 不是墙
*/
if (dfs(tx, ty)) {
return 1;
}
}
}
return 0;
}
int main() {
cin >> n >> m;
for (int i = 0; i < n; ++i) {
cin >> maze[i];
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (maze[i][j] == 'S') {
//记录起点的坐标
sx = i;
sy = j;
}
}
}
if (dfs(sx, sy)) {
puts("Yes");
} else {
puts("No");
}
return 0;
}
深搜的剪枝优化
可行性剪枝
剪枝,顾名思义,就是通过一些判断,砍掉搜索树上不必要的子树。有时候,在搜索过程中我们会发现某个结点对应的子树的状态都不是我们要的结果,那么我们其实没必要对这个分支进行搜索,直接“砍掉”这棵子树(直接 return退出),就是"剪枝"。
我们举一个例子:
给定n个整数,要求选出K个数,使得选出来的K个数的和为sum。
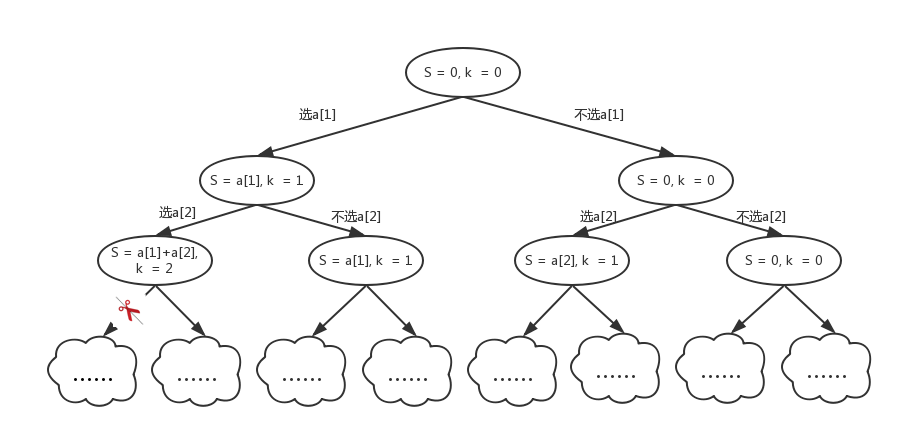
如上图,当k=2的时候,如果已经选了2个数,再往后选更多的数是没有意义的。所以我们可以直接减去这个搜索分支,对应上图中的剪刀减去的那棵子树。
又比如,如果所有的数都是正数,如果一旦发现当前和的值都已经大于sum了,那么之后不管怎么选,选择数的和都不可能是sum了,就可以直接终止这个分支的搜索。
例:从1,2,3,⋯,30这30个数中选8个数,使得和为200。
我们可以加如下剪枝
if (数字个数 > 8) return ;
if (总和 > 200) return ;
经过尝逝后发现:
没有剪枝

加剪枝:

最优性剪枝
我们再看一个问题:
有一个n×m大小的迷宫。其中字符
S表示起点,字符T表示终点,字符*表示墙壁,字符.表示平地。你需要从S出发走到T,每次只能向上下左右相邻的位置移动,并且不能走出地图,也不能走进墙壁。保证迷宫至少存在一种可行的路径,输出S走到T的最少步数。

对于求最优解(从起点到终点的最小步数)这种问题,通常可以用最优性剪枝,比如在求解迷宫最短路的时候,如果发现当前的步数已经超过了当前最优解,那从当前状态开始的搜索都是多余的,因为这样搜索下去永远都搜不到更优的解。通过这样的剪枝,可以省去大量冗余的计算。
此外,在搜索是否有可行解的过程中,一旦找到了一组可行解,后面所有的搜索都不必再进行了,这算是最优性剪枝的一个特例。
现在我们考虑用dfs来解决这个问题,第一个搜到的答案res并不一定是正解,但是正解一定小于等于res。于是如果当前步数大于等于res就直接剪枝。
在dfs函数内加入如下代码
if (目前步数 >= res) return ;
if (目前所处的位置字符 == 'T') {
答案 = 目前步数;//因为我们在刚才已经进行了一次剪枝,所以我们现在是可以保证目前答案大于之前答案的
return ;
}
好啦,到这里就结束了捏~
求赞qwq
深度优先搜索算法-dfs讲解的更多相关文章
- 图的深度优先搜索算法DFS
1.问题描写叙述与理解 深度优先搜索(Depth First Search.DFS)所遵循的策略.如同其名称所云.是在图中尽可能"更深"地进行搜索. 在深度优先搜索中,对最新发现的 ...
- 深度优先搜索算法(DFS)以及leetCode的subsets II
深度优先搜索算法(depth first search),是一个典型的图论算法.所遵循的搜索策略是尽可能“深”地去搜索一个图. 算法思想是: 对于新发现的顶点v,如果它有以点v为起点的未探测的边,则沿 ...
- 深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念 与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历.这种搜索算法所遵循的搜索策略是尽可能"深"地搜索一个图.它的基本思想如下:首先访问图中某一个起始 ...
- [数据结构]深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念 与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历.这种搜索算法所遵循的搜索策略是尽可能"深"地搜索一个图.它的基本思想如下:首先访问图中某一个起始 ...
- 广度优先遍历-BFS、深度优先遍历-DFS
广度优先遍历-BFS 广度优先遍历类似与二叉树的层序遍历算法,它的基本思想是:首先访问起始顶点v,接着由v出发,依次访问v的各个未访问的顶点w1 w2 w3....wn,然后再依次访问w1 w2 w3 ...
- Python数据结构与算法之图的广度优先与深度优先搜索算法示例
本文实例讲述了Python数据结构与算法之图的广度优先与深度优先搜索算法.分享给大家供大家参考,具体如下: 根据维基百科的伪代码实现: 广度优先BFS: 使用队列,集合 标记初始结点已被发现,放入队列 ...
- 深度优先搜索 DFS 学习笔记
深度优先搜索 学习笔记 引入 深度优先搜索 DFS 是图论中最基础,最重要的算法之一.DFS 是一种盲目搜寻法,也就是在每个点 \(u\) 上,任选一条边 DFS,直到回溯到 \(u\) 时才选择别的 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 利用广度优先搜索(BFS)与深度优先搜索(DFS)实现岛屿个数的问题(java)
需要说明一点,要成功运行本贴代码,需要重新复制我第一篇随笔<简单的循环队列>代码(版本有更新). 进入今天的主题. 今天这篇文章主要探讨广度优先搜索(BFS)结合队列和深度优先搜索(DFS ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
随机推荐
- Linux Framebuffer 实验
一.准备 linux虚拟机或ARM开发板 Ubuntu18.04 二.Framebuffer介绍 次笔记主要的目的是实验,所以我不介绍了,有需要的小伙伴可以去看下面博客 Linux LCD Framb ...
- C++初阶(运算符重载汇总+实例)
运算重载符 概念: 运算符重载是具有特殊函数名的函数,也具有其返回值类型,函数名字以及参数列表,其返回值类型与参数列表与普通的函数类似. 函数原型: 返回值 operator操作符(参数列表) 注意: ...
- MyEclipse 中自动安插作者、注释日期等快捷键方法
MyEclipse 中自动插入作者.注释日期等快捷键方法 MyEclipse 中自动插入作者.注释日期等de快捷键方法依次打开然后找到 Window -->Preferences->Jav ...
- 【软考-中级-其他】03、NoSQL和云计算
其他 NoSQL概述 分类 文档存储数据库:MongoDB 采用BSON格式完成存储数据和网络数据交换 BSON格式:JSON的二进制编码格式 逻辑结构包括:数据库.集合(相当于关系数据库的表).文档 ...
- Flutter和Rust如何优雅的交互
前言 文章的图片链接都是在github上,可能需要...你懂得:本文含有大量关键步骤配置图片,强烈建议在合适环境下阅读 Flutter直接调用C层还是蛮有魅力,想想你练习C++,然后直接能用flutt ...
- 0停机迁移Nacos?Java字节码技术来帮忙
摘要:本文介绍如何将Spring Cloud应用从开源Consul无缝迁移至华为云Nacos. 本文分享自华为云社区<0停机迁移Nacos?Java字节码技术来帮忙>,作者:华为云PaaS ...
- 视图 触发器 事务 MVCC 存储过程 MySQL函数 MySQL流程控制 索引的数据结构 索引失效 慢查询优化explain 数据库设计三范式
目录 视图 create view ... as 触发器 简介 创建触发器的语法 create trigger 触发器命名有一定的规律 临时修改SQL语句的结束符 delimiter 触发器的实际运用 ...
- python函数及算法
算法二分法 二分算法图 什么是算法? 算法是高效解决问题的办法. 需求:有一个按照从小到大顺序排列的数字列表,查找某一个数字 # 定义一个无序的列表 nums = [3,4,5,67,8,9,12 ...
- 一文掌握MyBatis的动态SQL使用与原理
摘要:使用动态 SQL 并非一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语言,MyBatis 显著地提升了这一特性的易用性. 本文分享自华为云社区<MyBatis详解 - ...
- Kali Pi 安装 RTL8812AU驱动
今天,我们来实操安装一下昨天的RTL8812的无线网卡驱动. 说明 我们今天使用的网卡是磊科的NW392无线网卡,其主要核心为NW392. 一张32G内存卡 树莓派为树莓派4B 4G-RAM 系统为 ...