Hive学习之路 (二十)Hive 执行过程实例分析
一、Hive 执行过程概述
1、概述
(1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等
(2)操作符 Operator 是 Hive 的最小处理单元
(3)每个操作符代表一个 HDFS 操作或者 MapReduce 作业
(4)Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分 布式两种模式
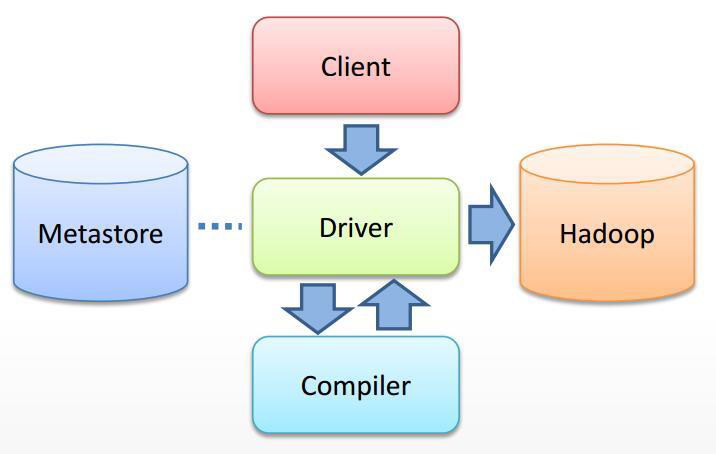
2、Hive 操作符列表
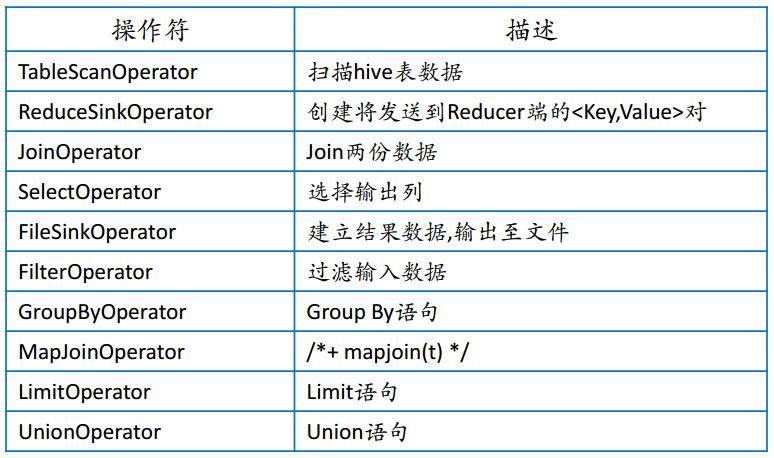
3、Hive 编译器的工作职责
(1)Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree)
(2)Semantic Analyzer:将抽象语法树转换成查询块
(3)Logic Plan Generator:将查询块转换成逻辑查询计划
(4)Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划
(5)Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs)
(6)Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划
4、优化器类型
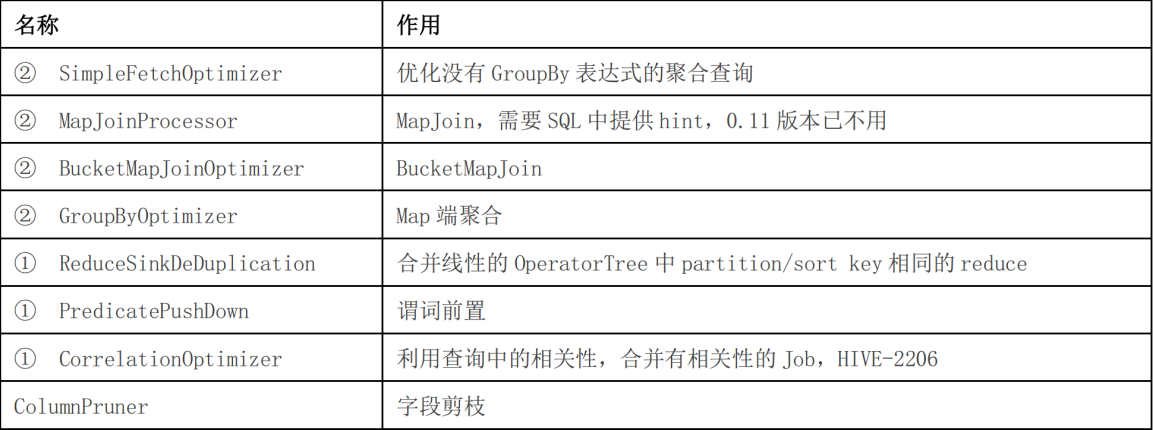
上表中带①符号的,优化目的都是尽量将任务合并到一个 Job 中,以减少 Job 数量,带②的 优化目的是尽量减少 shuffle 数据量
二、join
1、对于 join 操作
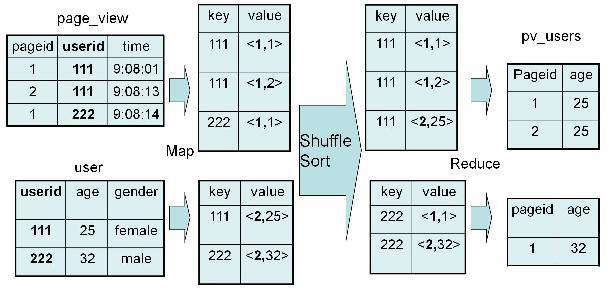
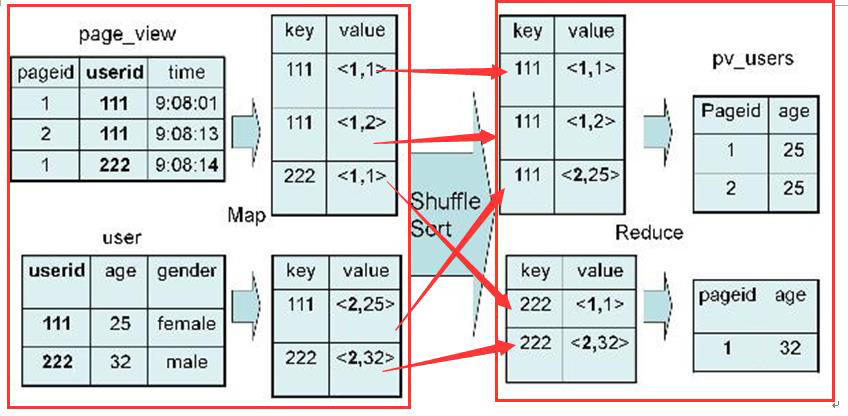
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;
2、实现过程
Map:
1、以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
2、以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表
3、按照 Key 进行排序
Shuffle:
1、根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中
Reduce:
1、 Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据
3、具体实现过程
三、Group By
1、对于 group by操作
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
2、实现过程
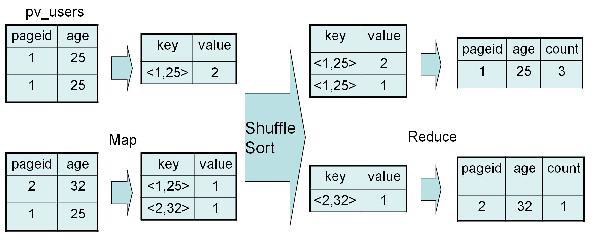
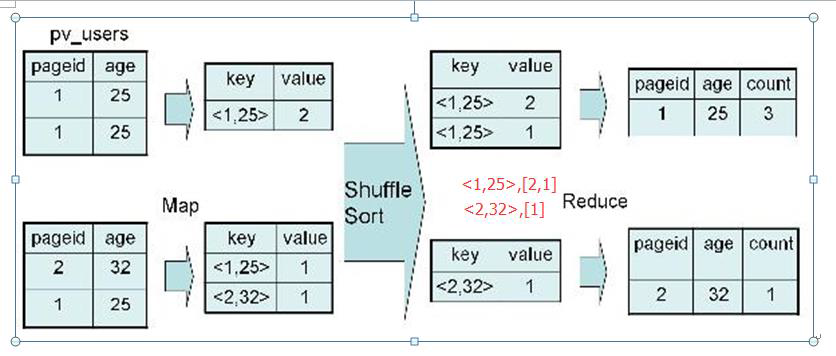
四、Distinct
1、对于 distinct的操作
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;
2、实现过程
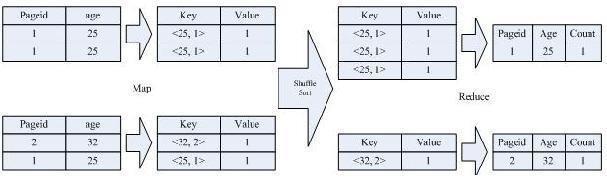
3、详细过程解释
该 SQL 语句会按照 age 和 pageid 预先分组,进行 distinct 操作。然后会再按 照 age 进行分组,再进行一次 distinct 操作
Hive学习之路 (二十)Hive 执行过程实例分析的更多相关文章
- Hive(六)hive执行过程实例分析与hive优化策略
一.Hive 执行过程实例分析 1.join 对于 join 操作:SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.useri ...
- Hive学习之路 (十八)Hive的Shell操作
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
- Hive(九)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hadoop MapReduce执行过程实例分析
1.MapReduce是如何执行任务的?2.Mapper任务是怎样的一个过程?3.Reduce是如何执行任务的?4.键值对是如何编号的?5.实例,如何计算没见最高气温? 分析MapReduce执行过程 ...
- Hive学习之路 (十二)Hive SQL练习之影评案例
案例说明 现有如此三份数据:1.users.dat 数据格式为: 2::M::56::16::70072, 共有6040条数据对应字段为:UserID BigInt, Gender String, A ...
- Hive学习之路 (十四)Hive分析窗口函数(二) NTILE,ROW_NUMBER,RANK,DENSE_RANK
概述 本文中介绍前几个序列函数,NTILE,ROW_NUMBER,RANK,DENSE_RANK,下面会一一解释各自的用途. 注意: 序列函数不支持WINDOW子句.(ROWS BETWEEN) 数据 ...
- Hive学习之路 (十)Hive的高级操作
一.负责数据类型 1.array 现有数据如下: 1 huangbo guangzhou,xianggang,shenzhen a1:30,a2:20,a3:100 beijing,112233,13 ...
- Hive学习之路 (十九)Hive的数据倾斜
1.什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点 2.Hadoop 框架的特性 A.不怕数据大,怕数据倾斜 B.Jobs 数比较多的作业运行效率相对比较低,如子查询比较 ...
- Hive学习之路 (十六)Hive分析窗口函数(四) LAG、LEAD、FIRST_VALUE和LAST_VALUE
数据准备 数据格式 cookie4.txt cookie1, ::,url2 cookie1, ::,url1 cookie1, ::,1url3 cookie1, ::,url6 cookie1, ...
随机推荐
- 【转】从msql数据库处理高并发商品超卖
今天王总又给我们上了一课,其实mysql处理高并发,防止库存超卖的问题,在去年的时候,王总已经提过:但是很可惜,即使当时大家都听懂了,但是在现实开发中,还是没这方面的意识.今天就我的一些理解,整理一下 ...
- 解决:jsp 页面不全,response 内容不完整
前言:今天 jsp 页面输出不完整这个问题困扰了我几个小时,终于发现问题并解决了. 环境: tomcat 8.0.17 x64 jsp springmvc vue 问题: 本来页面正常,但加了几行代码 ...
- CSS页面重构“鑫三无准则”之“无图片”准则——张鑫旭
一.再说关于“鑫三无准则” “鑫三无准则”这个概念貌似最早是在去年的去年一篇名叫“关于Google圆角高光高宽自适应按钮及其拓展”的文章中提过.这是自己在页面重构的经验中总结出来的一套约束自己CSS的 ...
- K先生的博客
努力,不是为了要感动谁,也不是要做给哪个人看,而是要让自己随时有能力跳出自己厌恶的圈子,并拥有选择的权利. 自己既然选择了这条路,那就要不忘初心坚定的走下去!或许坚持到最后自己会伤痕累累,但,那又怎么 ...
- CSS样式之a标签(原文网址http://www.divcss5.com/shili/s57.shtml)
这是个人在做网站的时候整理的关于a标签的使用方法,整理一下,方便下次使用. 一.a超链接的代码 <a href="http://www.baidu.com" target=& ...
- OpenGL学习--05--纹理立方体--BMP文件格式详解(转载)
http://blog.csdn.net/o_sun_o/article/details/8351037 BMP文件格式详解 BMP文件格式详解(BMP file format) BMP文件格式,又称 ...
- Android实现不同Active页面间的跳转
Intent intent = new Intent(); intent.setClass(ErrorPageActive.this, LoginActive.class); startActivit ...
- textarea高度跟随文字高度而变化
html部分: <textarea id="textarea">哈喽哈喽哈喽哈喽哈喽哈喽哈喽哈喽哈喽哈喽哈喽哈喽</textarea> js部分: < ...
- Ubuntu16安装GPU版本TensorFlow(个人笔记本电脑)
想着开始学习tf了怎么能不用GPU,网上查了一下发现GeForce GTX确实支持GPU运算,所以就尝试部署了一下,在这里记录一下,避免大家少走弯路. 使用个人笔记本电脑thinkpadE570,内存 ...
- maven(19)-生命周期和内置插件
生命周期和依赖一样,是maven中最重要的核心概念.平时在使用maven时并不一定需要知道生命周期,但是只有明白了生命周期,才能真正理解很多重要的命令和插件配置. default生命周期 defaul ...