Redis 之深入江湖-复制原理
一.前言
上一篇文章Redis 之复制-初入江湖中,讲了关于Redis复制配置,如:如何建立配置、如何断开复制、关于链接的安全性等等,那么本篇文章将深入的去说一下关于Redis复制原理,如下:
- 复制过程
- 数据同步
- 全量复制
- 部分复制
- 心跳
- 异步复制
二.复制过程
在从节点执行slaveof命令后,复制过程便开始运作,下面将会详细的讲解建立复制的完整流程,如下图所示:
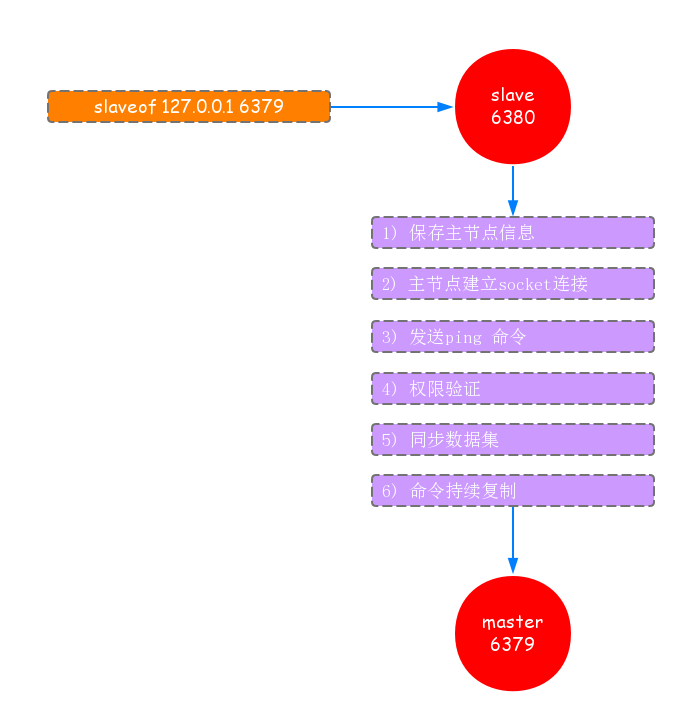
从上图中,可以看出复制的一个大致流程:
- 保存master(主节点)信息:从节点执行slaveof后只保存主节点的地址信息后便直接返回,这时建立复制的流程还没开始.
- slave(从节点)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,从节点会建立一个socket连接主节点.如果从节点无法建立连接,定时任务会无限重试直到连接成功,或者执行slaveof no one取消复制.
- 发送ping命令,如果发送ping命令后(目的:1)检测主从之间网络套节字持否可用;2)检测主节点当前是否可接受处理命令),从节点没有收到主节点的pong回复或者连接超时,比如网络超时或者主节点阻塞无法响应,从节点会断开复制连接,下次定时任务会继续发起重连.
- 权限验证.如果主节点设置了requirepass参数,那么就需要密码进行权限验证;如果验证失败,复制将终止.从节点会重新发起复制流程.
- 同步数据集.权限验证通过后,进行数据同步,对于首次建立复制的场景,主节点会把持有的数据全部发给从节点,这个操作耗时最长.(在Redis2.8版本之后,同步操作分两种情况:全量和部分,下面将会说到)
- 命令持续复制.当主节点把当前所有数据同步给从节点后,便完成了复制的整个流程,后面主节点将持续把写命令发给从节点,以保持数据的一致性.
三.数据同步
在上面的复制整个流程中,有一个步骤是“同步数据集”,这个通过过程分为:全量复制和部分复制.
全量复制:一般用于初次复制场景,Redis早期支持的复制功能便只有全量复制,它会把主节点的所有数据一次性发给从节点,当数据量较大时,这会给主从节点之间的各个方面带来很大的开销.
部分复制:用于处理在主从复制中因网络闪断等原因造成数据丢失的场景,当从节点再次连上主节点后,如果条件允许,主节点会补发之前丢失的数据给从节点.因为补发的数据远远小于全量数据,可以有效的避免复制过程中的过高开销.
Redis的同步有2个命令,分别是:sync 和 psync,前者是 redis 2.8 之前的同步命令,后者是 redis 2.8 为了优化 sync 新设计的命令.我们会重点关注 2.8版本以后的 psync 命令.psync 命令的运行需要三个组件支持:(1)主从节点各自复制偏移量;(2)主节点复制积压缓冲区;(3)主节点运行id.
1).主从节点的复制偏移量
1.参与复制的主从节点都会维护自身复制偏移量.统计信息在使用info replication命令查看中的master_repl_offset指标中.
2.从节点(slave)每秒钟上报自身复制偏移量给主节点,因此主节点也会保存从节点的偏移量.
3.从节点在接收到主节点发送的命令后,也会累加自身的偏移量.
4.通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致,如下图所示.
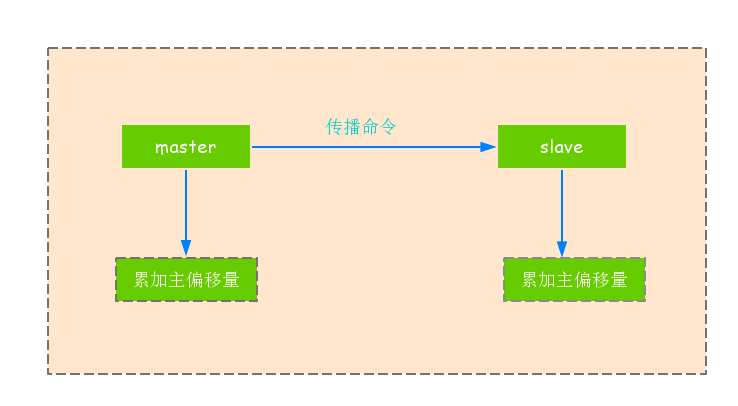
注:可以通过主节点的统计信息,计算出master_repl_offset-slave_offset字节量,判断主从节点复制相差的数据量,根据这个产值判定当前复制的健康度.如果主从之间复制偏移量相差较大,则可能是网络延迟或命令阻塞等原因引起的.
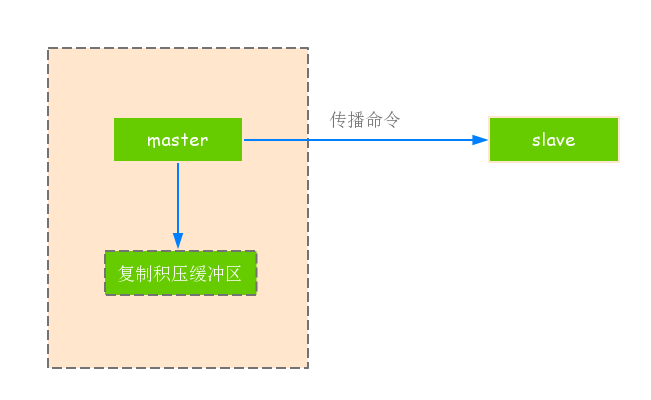
2).复制积压缓冲区
(1)复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB.当主节点有连接的从节点(slave)被创建时,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区,如下图所示.
(2)由于缓冲区本质上是先进先出的定长队列,所以能实现保存最近已复制数据的功能,用于部分复制和复制命令丢失的数据补救,可以通过 info replication 查看相关信息.
3).主节点运行ID
(1)每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运行ID.
(2)运行ID的主要作用是用来唯一识别的Redis节点,比如从节点保存主节点运行ID识别自己正在复制的是哪个主节点.如果只是使用ip+port的方式识别主节点,那么主节点重启变更了整体数据集(如替换RDB/AOF文件),从节点再基于偏移量复制数据将是不安全的,因此当运行ID变化后从节点将做全量复制.
(3)上面提到的是主节点重启变更,那么重启不改变运行ID呢?这时可以使用 debug reload 命令重新加载RDB并保持运行ID不变,从而有效避免不必要的全量复制.
注:debug reload命令会阻塞当前Redis节点主线程,阻塞期间会生成本地RDB快照并清空数据之后再加载RDB文件.因此对于大量数据的主节点和无法容忍阻塞的应用场景,是要谨慎使用的.
4).psync命令
从节点使用psync命令完成部分复制和全量复制功能.命令格式:psync {runId} {offset},其参数含义如下:
- runId:从节点所复制主节点的运行ID
- offset:当前从节点已复制的数据偏移量
psync的执行流程如下:

流程说明:
- slave(从节点)发送sync命令给主节点,参数runId是当前从节点保存的主节点运行ID,如果没有则默认为-1.offset 是从节点保存的复制偏移量,如果是第一次复制则为 -1.
- master(主节点)根据sync参数和自身数据的情况决定响应结果:
- 如果回复+FULLRESYNC {runId} {offset} ,那么从节点将触发全量复制流程。
- 如果回复 +CONTINUE,从节点将触发部分复制.
- 如果回复 +ERR,说明主节点不支持 2.8 的 psync 命令,将使用 sync 执行全量复制.
四.全量复制
全量复制是Redis最早支持的复制方式,也是主从第一次建立复制是必须要走的流程.触发全量复制的命令是 sync 和 psync.前面已经说过,redis 2.8 之前使用 sync 只能执行全量不同, 之后同时支持全量同步和部分同步.
流程如图:
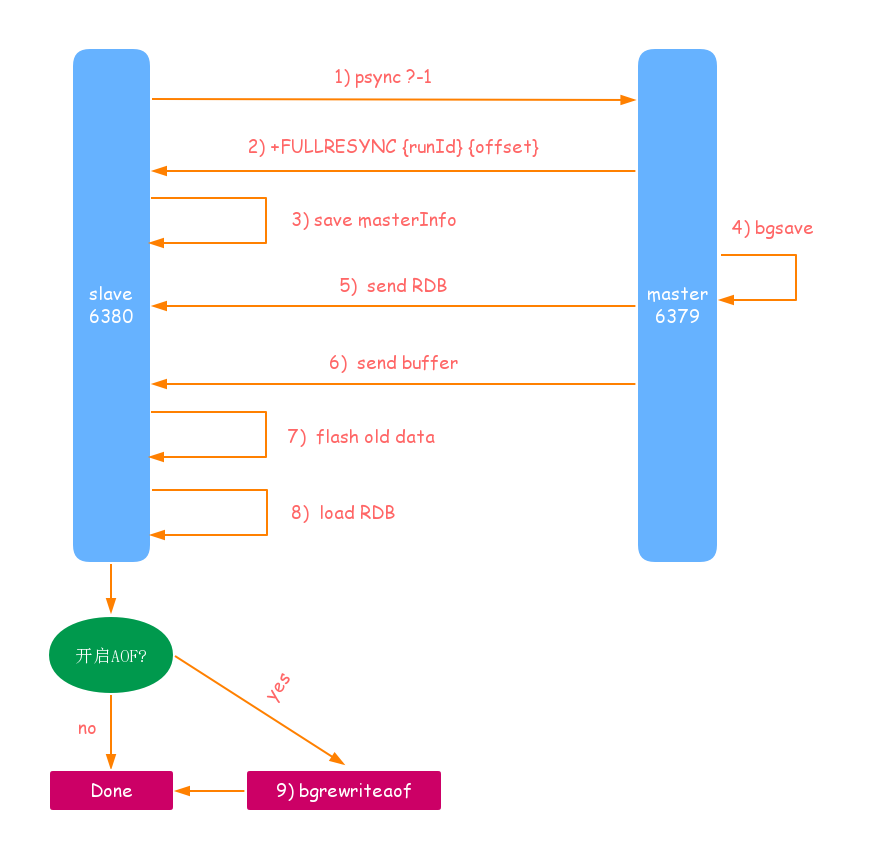
流程说明:
- 发送psync命令进行同步数据,由于是第一次进行复制,从节点还没有复制偏移量和主节点运行ID,所以发送:psysc ?-1.
- 主节点根据psysc ?-1 当前为全局复制,回复 +FULLRESYNC 响应.
- 从节点接受主节点的响应并保存运行ID和offset.
- 主节点执行 bgsave 并保存 RDB 到本地.
- 主节点发送RDB文件到从节点,从节点把所接收的RDB文件保存到本地,并将其作为从节点的数据文件.
- 对于从节点接受RDB文件快照到完成期间,主节点依然响应读写命令,因此主节点会把这段时间内的数据保存到复制客户端缓冲区内,当从节点加载完RDB文件后,主节点会再把缓冲区内的数据发给从节点,保证主从之间数据一致性.
- 从节点接受完主节点传来的全部数据后,会清空自身旧数据.
- 从节点清空数据后开始加载RDB文件,对于较大的RDB文件,这一步还是非常耗时的.
- 从节点成功加载完 RBD 后,如果当前节点开启了 AOF,会立刻做 bgrewriteaof操作.
以上加粗的部分是整个全量同步耗时的地方.
注:
- 如果线上RDB 文件数据量在 6G左右的主节点,并且是千兆网卡,Redis 的默认超时机制(60 秒),会导致全量复制失败.可以通过调大 repl-timeout 参数来解决此问题.
- Redis 虽然支持无盘复制,生成的RDB文件不保存到本地,而是直接通过网络发送给从节点,不过无盘复制还处于试验阶段,所以生产环境一定慎用。
五.部分复制
部分复制主要是Redis针对全量复制的过高开销,所做的一些优化.在slave(从节点)正在向master(主节点)时,如果出现网络闪断或者命令丢失等异常情况发生时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分,则直接打给从节点,这样便可以保持主从节点复制的一致性.补发的这部分数据远远小于全量数据,所以开销很小.部分复制流程图如下:
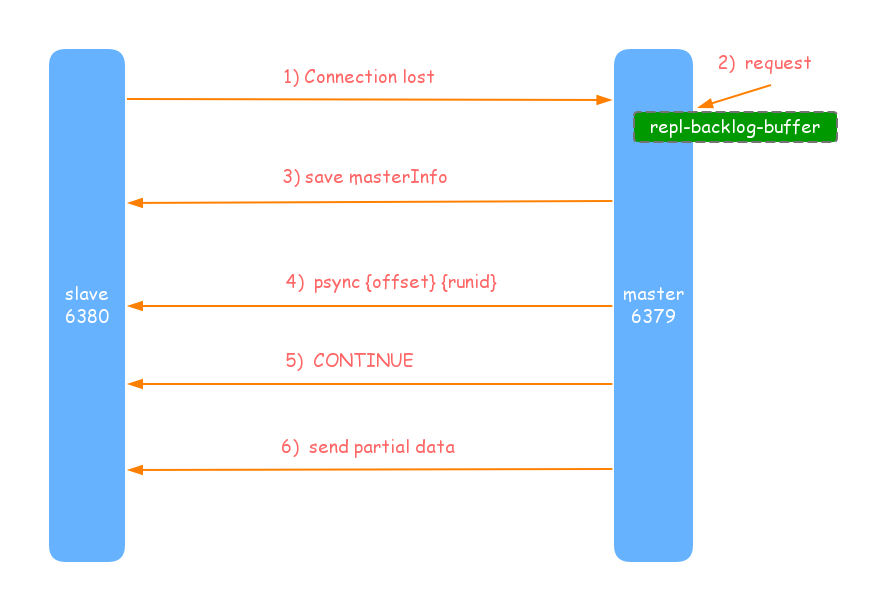
- 当主从节点之间网络出现中断时,如果超过repl-timeout时间,主节点会认为从节点故障并中断复制连接.
- 主节点连接中断期间,主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在复制积压缓冲区,依然可保存最近一段时间的数据,默认为1MB.
- 当从节点网络恢复后,从节点会在此连上主节点.
- 当主从连接恢复后,因为之前从节点保存了自身已复制的offset和运行ID,所以会把把其当作psync参数发给主节点.
- 主节点连接到psync命令后,首先核对参数runId是否一致,如果一致说明之前复制的是当前主节点,然后根据offset参数在自身复制积压缓冲区中进行查找,如果偏移量之后的数据存在缓冲区中,则想从节点发送 +CONTINUE 响应,表示进行部分复制.
- 主节点根据偏移量吧复制积压缓冲区里数据发给从节点,以保证主从复制进入正常状态.
六.心跳
主从节点在建立复制后,他们之间维护着长连接,并且彼此发送心跳.如图:
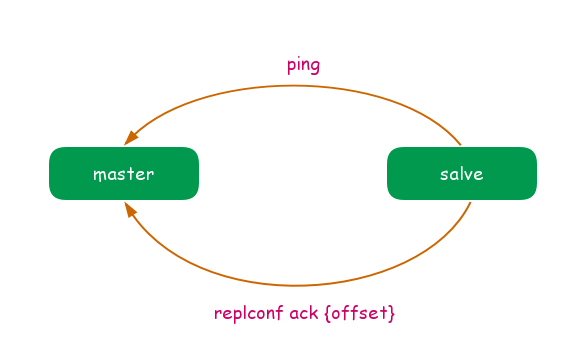
主从心跳判断机制:
- 主从节点彼此都有心跳检测机制,各自模拟成对方的客户端急性通信,通过 client list 命令查看复制相关客户端信息,主节点的连接状态为 flags = M,从节点的连接状态是 flags = S.
- 主节点默认每隔10秒对从节点发送ping命令,判断从节点的存活状态和连接状态,可通过修改配置 repl-ping-slave-period 控制发送频率.
- 从节点在主线程每隔1秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量.
- 主节点收到 replconf 信息后,判断从节点超时时间,如果超过 repl-timeout 设置的值(默认值为60 秒),则判断从节点下线,并断开复制客户端连接.
replconf的作用:
- 实时监测主从节点的网络状态
- 上报自身的偏移量,检查复制数据是否丢失
- 实现保证从节点的数量和延迟功能,通过min-slaves-to-write,min-slaves-max-lag参数配置定义
注意:为了降低主从延迟,一般把 Redis 主从节点部署在相同的机房/同城机房,避免网络延迟带来的网络分区造成的心跳中断等情况.
七.异步复制
主节点不但负责数据读写,还负责把写命令同步给从节点.写命令的发送过程是异步完成的,也就是说主节点自身处理完写命令后直接返回给客户端,并不等待从节点复制完成,如下图所示:
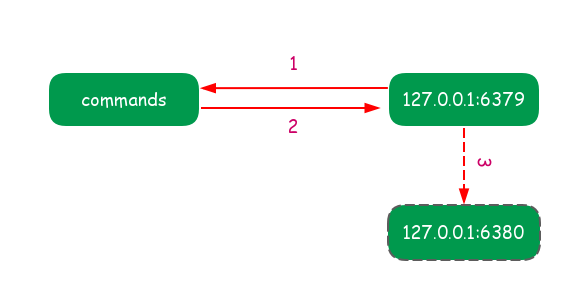
异步复制的流程如下:
- 主节点接受处理命令
- 命令处理完之后返回响应结果
- 对于修改命令异步发送给从节点,从节点在主线程中执行复制的命令.
八.回顾
本篇文章,大略分析了下复制过程、数据同步、全量复制、部分复制、心跳、异步复制等方面的原理.
参考:《Redis开发与运维》
版权声明:尊重博主原创文章,转载请注明出处 https://www.cnblogs.com/hsdy
Redis 之深入江湖-复制原理的更多相关文章
- 深入理解redis复制原理
原文:深入理解redis复制原理 1.复制过程 2.数据间的同步 3.全量复制 4.部分复制 5.心跳 6.异步复制 1.复制过程 从节点执行 slaveof 命令. 从节点只是保存了 slaveof ...
- 搞懂Redis复制原理
前言 与大多数db一样,Redis也提供了复制机制,以满足故障恢复和负载均衡等需求.复制也是Redis高可用的基础,哨兵和集群都是建立在复制基础上实现高可用的.复制不仅提高了整个系统的容错能力,还可以 ...
- Redis 复制原理及特性
摘要 早期的RDBMS被设计为运行在单个CPU之上,读写操作都由经单个数据库实例完成,复制技术使得数据库的读写操作可以分散在运行于不同CPU之上的独立服务器上,Redis作为一个开源的.优秀的key- ...
- Redis从出门到高可用--Redis复制原理与优化
Redis从出门到高可用–Redis复制原理与优化 单机有什么问题? 1.单机故障; 2.单机容量有瓶颈 3.单机有QPS瓶颈 主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/s ...
- Redis复制原理
无论是在集群中还是主从结构中,redis新加入的节点和已有主(从)节点的消息同步都是通过sync命令的形式 下面来实践一下redis的同步机制, 新建主服务器于从服务器 主 从: 这是正常的主从结 ...
- Redis系列四之复制
一.复制基本配置与演示 为了避免单点故障,Redis提供了复制功能,可以实现自动同步的过程. 1.配置 同步后的数据分为两类:一类是主数据库(master),一类是从数据库(slave).主数据库可以 ...
- Redis的主从同步复制
先来看一下Redis的主从同步复制的原理: 在Slave启动并连接到Master之后,它将主动发送一条SYNC命令.此后Master将启动后台存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台 ...
- 进阶的Redis之哈希分片原理与集群实战
前面介绍了<进阶的Redis之数据持久化RDB与AOF>和<进阶的Redis之Sentinel原理及实战>,这次来了解下Redis的集群功能,以及其中哈希分片原理. 集群分片模 ...
- Redisson实现Redis分布式锁的底层原理
一.写在前面 现在面试,一般都会聊聊分布式系统这块的东西.通常面试官都会从服务框架(Spring Cloud.Dubbo)聊起,一路聊到分布式事务.分布式锁.ZooKeeper等知识.所以咱们这篇文章 ...
随机推荐
- MySql 缓存查询原理与缓存监控 和 索引监控
MySql缓存查询原理与缓存监控 And 索引监控 by:授客 QQ:1033553122 查询缓存 1.查询缓存操作原理 mysql执行查询语句之前,把查询语句同查询缓存中的语句进行比较,且是按字节 ...
- Flutter学习之制作底部菜单导航
简介 现在我们的 APP 上面都会在屏幕下方有一排的按钮,点击不同的按钮可以进入不同的界面.就是说在界面的底部会有一排的按钮导航.可看下面的图示. 完成图示 程序工程目录 梳理下实现步骤我们需要实现这 ...
- Linux学习之CentOS(一)----在VMware虚拟机中安装CentOS 7
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/3 ...
- js 时间日期函数小结
Date.prototype.format = function(format){ var o = { "M+" : this.getMonth()+1, //month &quo ...
- spring配置datasource
1.使用org.springframework.jdbc.datasource.DriverManagerDataSource 说明:DriverManagerDataSource建立连接是只要有连 ...
- 11 个 Git 面试题
源自:https://mp.weixin.qq.com/s/ghF27N0XjgG0pw2XpGDCYA 在今年的 Stack Overflow 开发者调查报告中,超过 70% 的开发者使用 Git, ...
- GIT学习---GIT&github的使用
GIT&github入门 版本控制的原理: 根据md5进行文件的校验[MD5的特性就是每次的输入一致则输出也一致],对于每次的修改进行一次快照 版本控制的2个功能: 版本管理 + 协作开 ...
- 《C++ Primer Plus》读书笔记之十—类和动态内存分配
第12章 类和动态内存分配 1.不能在类声明中初始化静态成员变量,这是因为声明描述了如何分配内存,但并不分配内存.可以在类声明之外使用单独的语句进行初始化,这是因为静态类成员是单独存储的,而不是对象的 ...
- shell study
目录 shell记录 执行脚本 变量使用 注释 shell传递参数 运算符 echo printf test 流程控制 if ... else ... for while until case 跳出循 ...
- September 05th 2017 Week 36th Tuesday
I always in the deepest despair, meet the most beautiful sunrise. 我总是在最深的绝望里遇见最美丽的惊喜. Some pessimist ...