HashMap+双向链表手写LRU缓存算法/页面置换算法
import java.util.Hashtable;
class DLinkedList {
String key; //键
int value; //值
DLinkedList pre; //双向链表前驱
DLinkedList next; //双向链表后继
}
public class LRUCache {
private Hashtable<String,DLinkedList> cache = new Hashtable<String,DLinkedList>();
private int count;
private int capacity;
private DLinkedList head, tail;
public LRUCache(int capacity) {
this.count = 0;
this.capacity = capacity;
head = new DLinkedList();
head.pre = null;
tail = new DLinkedList();
tail.next = null;
head.next = tail;
tail.pre = head;
}
public int get(String key) {
DLinkedList node = cache.get(key);
if(node == null) return -1;
this.moveToHead(node);
return node.value;
}
public void set(String key,int value) {
DLinkedList node = cache.get(key);
if(node == null) {
DLinkedList newNode = new DLinkedList();
newNode.key = key;
newNode.value = value;
this.cache.put(key, newNode);
this.addNode(newNode);
++count;
if(count>capacity) {
DLinkedList tail = this.popTail();
this.cache.remove(tail.key);
--count;
}
}
else {
node.value = value;
this.moveToHead(node);
}
}
private void addNode(DLinkedList node) {
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
private void removeNode(DLinkedList node) {
DLinkedList pre = node.pre;
DLinkedList next = node.next;
pre.next = next;
next.pre = pre;
}
private void moveToHead(DLinkedList node) {
this.removeNode(node);
this.addNode(node);
}
private DLinkedList popTail() {
DLinkedList res = tail.pre;
this.removeNode(res);
return res;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
DLinkedList node = head;
while(node != null){
sb.append(String.format("%s:%s ", node.key,node.value));
node = node.next;
}
return sb.toString();
}
public static void main(String[] args) {
LRUCache lru = new LRUCache(3);
lru.set("1", 7);
System.out.println(lru.toString());
lru.set("2", 0);
System.out.println(lru.toString());
lru.set("3", 1);
System.out.println(lru.toString());
lru.set("4", 2);
System.out.println(lru.toString());
lru.get("2");
System.out.println(lru.toString());
lru.set("5", 3);
System.out.println(lru.toString());
lru.get("2");
System.out.println(lru.toString());
lru.set("6", 4);
System.out.println(lru.toString());
/*
0ull:0 1:7 null:0
null:0 2:0 1:7 null:0
null:0 3:1 2:0 1:7 null:0
null:0 4:2 3:1 2:0 null:0
null:0 2:0 4:2 3:1 null:0
null:0 5:3 2:0 4:2 null:0
null:0 2:0 5:3 4:2 null:0
null:0 6:4 2:0 5:3 null:0
*/
}
}
那么如何设计一个LRU缓存,使得放入和移除都是 O(1) 的,我们需要把访问次序维护起来,但是不能通过内存中的真实排序来反应,有一种方案就是使用双向链表。
整体的设计思路是,可以使用 HashMap 存储 key,这样可以做到 save 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点,如图所示。
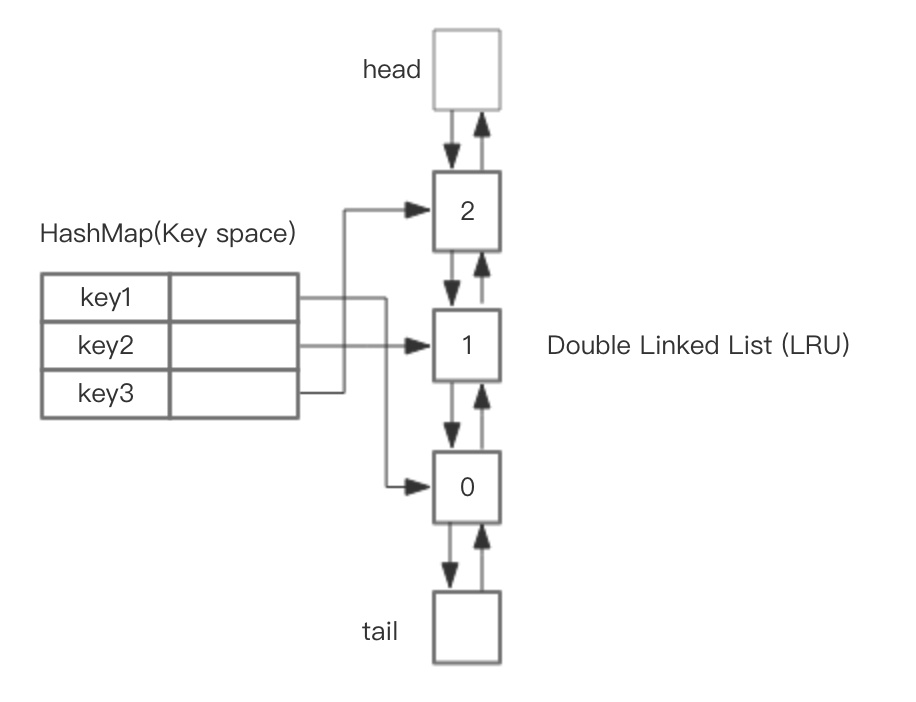
LRU 存储是基于双向链表实现的,下面的图演示了它的原理。其中 head 代表双向链表的表头,tail 代表尾部。首先预先设置 LRU 的容量,如果存储满了,可以通过 O(1) 的时间淘汰掉双向链表的尾部,每次新增和访问数据,都可以通过 O(1)的效率把新的节点增加到对头,或者把已经存在的节点移动到队头。
下面展示了,预设大小是 3 的,LRU存储的在存储和访问过程中的变化。为了简化图复杂度,图中没有展示 HashMap部分的变化,仅仅演示了上图 LRU 双向链表的变化。我们对这个LRU缓存的操作序列如下:
save("key1", 7)
save("key2", 0)
save("key3", 1)
save("key4", 2)
get("key2")
save("key5", 3)
get("key2")
save("key6", 4)
相应的 LRU 双向链表部分变化如下:
 s = save, g = get
s = save, g = get
总结一下核心操作的步骤:
- save(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
- get(key),通过 HashMap 找到 LRU 链表节点,因为根据LRU 原理,这个节点是最新访问的,所以要把节点插入到队头,然后返回缓存的值。
【https://zhuanlan.zhihu.com/p/34133067】
HashMap+双向链表手写LRU缓存算法/页面置换算法的更多相关文章
- 页面置换算法 - FIFO、LFU、LRU
缓存算法(页面置换算法)-FIFO. LFU. LRU 在前一篇文章中通过leetcode的一道题目了解了LRU算法的具体设计思路,下面继续来探讨一下另外两种常见的Cache算法:FIFO. LFU ...
- 操作系统-2-存储管理之LRU页面置换算法(LeetCode146)
LRU缓存机制 题目:运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制. 它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - ...
- 操作系统笔记(六)页面置换算法 FIFO法 LRU最近最久未使用法 CLOCK法 二次机会法
前篇在此: 操作系统笔记(五) 虚拟内存,覆盖和交换技术 操作系统 笔记(三)计算机体系结构,地址空间.连续内存分配(四)非连续内存分配:分段,分页 内容不多,就不做index了. 功能:当缺页中断发 ...
- 操作系统页面置换算法(opt,lru,fifo,clock)实现
选择调出页面的算法就称为页面置换算法.好的页面置换算法应有较低的页面更换频率,也就是说,应将以后不会再访问或者以后较长时间内不会再访问的页面先调出. 常见的置换算法有以下四种(以下来自操作系统课本). ...
- 操作系统 页面置换算法LRU和FIFO
LRU(Least Recently Used)最少使用页面置换算法,顾名思义,就是替换掉最少使用的页面. FIFO(first in first out,先进先出)页面置换算法,这是的最早出现的置换 ...
- (待续)C#语言中的动态数组(ArrayList)模拟常用页面置换算法(FIFO、LRU、Optimal)
目录 00 简介 01 算法概述 02 公用方法与变量解释 03 先进先出置换算法(FIFO) 04 最近最久未使用(LRU)算法 05 最佳置换算法(OPT) 00 简介 页面置换算法主要是记录内存 ...
- 页面置换算法(最佳置换算法、FIFO置换算法、LRU置换算法、LFU置换算法)
页面置换产生的原因是:分页请求式存储管理(它是实现虚拟存储管理的方法之一,其中一个特性是多次性-->多次将页面换入或换出内存) 效果最好的页面置换算法:最佳置换算法 比较常用的页面置换算法有:F ...
- 页面置换算法-LRU(Least Recently Used)c++实现
最近最久未使用(LRU)置换算法 #include <iostream> #include <cstdio> #include <cstring> #include ...
- 页面置换算法之Clock算法
1.前言 缓冲池是数据库最终的概念,数据库可以将一部分数据页放在内存中形成缓冲池,当需要一个数据页时,首先检查内存中的缓冲池是否有这个页面,如果有则直接命中返回,没有则从磁盘中读取这一页,然后缓存到内 ...
随机推荐
- Redis学习七:Redis的持久化-总结(Which one)
1.官网建议 2.RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储 3.AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些 命令来恢复原始的数据,AOF命令以red ...
- JAVA编程之——反射Reflect
说到反射,首先要说一下Java中的类和对象. 在Java中万事万物皆对象(有两个 例外,一个是普通数据类型,另一个是静态的东西,静态的东西不是对象的,是属于类的). 在Java中,类也是对象,类是ja ...
- 【CodeForces】961 G. Partitions 斯特林数
[题目]G. Partitions [题意]n个数$w_i$,每个非空子集S的价值是$W(S)=|S|\sum_{i\in S}w_i$,一种划分方案的价值是所有非空子集的价值和,求所有划分成k个非空 ...
- fifo 上使用 select -- 转
http://www.outflux.net/blog/archives/2008/03/09/using-select-on-a-fifo/ The right way to handle on-g ...
- SMTP——MIME
MIME 基础知识 MIME 表示多用途 Internet 邮件扩允协议.MIME 扩允了基本的面向文本的 Internet 邮件系统,以便可以在消息中包含二进制附件. MIME 信息由正常的 Int ...
- JDK1.8源码LinkedList
引用博文链接 : https://www.cnblogs.com/leskang/p/6029780.html LinkedList继承了 AbstractSequentialList抽象类,而不是像 ...
- window.print打印方法实现
vue中使用window.print打印效果 项目要求 打印每页有10行表格,如果接口数据没有十个显示10行 效果图 第一页 第二页 子组件 <template> <div> ...
- IE手工导入证书
打开cer文件->欢迎使用证书导入向导->下一步->将所有的证书放入下列存储->受信任的根证书颁发机构->完成
- dedecms调用文章列表第一篇和下面几篇不同的方法
{dede:arclist row=1 orderby=pubdate infolen=60 limit=0,1} <li class="dot1"><img s ...
- jersey中的405错误 method not allowed