Ubuntu-16.04-Desktop +Hadoop2.7.5+Eclipse-Neon的云计算开发环境的搭建(伪分布式方式)
|
主控终端 |
|
|
主机名 |
ubuntuhadoop.smartmap.com |
|
IP |
192.168.1.60 |
|
Subnet mask |
255.255.255.0 |
|
Gateway |
192.168.1.1 |
|
DNS |
218.30.19.50 |
|
61.134.1.5 |
|
|
Search domains |
smartmap.com |
1. 设置网络IP
sudo
nmtui

sudo
/etc/init.d/networking restart
2. 设置主机名
sudo
hostnamectl set-hostname=ubuntuhadoop.smartmap.com
sudo
gedit /etc/hosts
127.0.0.1 localhost
#
127.0.0.1 ubuntuhadoop.smartmap.com
#
127.0.0.1 ubuntuhadoop
192.168.1.60 ubuntuhadoop
192.168.1.60 ubuntuhadoop.smartmap.com
# The
following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
3. 关闭防火墙
sudo
ufw disable
4. 安装VMwareTool
https://www.linuxidc.com/Linux/2016-04/130807.htm
5. 安装SSH
5.1. 安装SSH服务
sudo
apt-get install -y openssh-server
5.2. 设置SSH
sudo
vi /etc/ssh/sshd_config
PermitRootLogin yes
5.3. 启动SSH服务
sudo
service ssh start
sudo
service ssh restart
5.4. 节点间无密码互访
5.4.1. zyx用户
cd
~
ssh-keygen
-t rsa
cp
.ssh/id_rsa.pub .ssh/authorized_keys
5.4.2. root用户
sudo
su – root
cd
~
ssh-keygen
-t rsa
cp
.ssh/id_rsa.pub .ssh/authorized_keys
exit
6. 设置vim(Ubuntu中的vim太难用了)
sudo
gedit /etc/vim/vimrc.tiny
" set
compatible
set
nocompatible
set
backspace=2
"
vim: set ft=vim:
7. 安装JDK
7.1. 加入Oracle的JDK仓库
sudo
add-apt-repository ppa:webupd8team/java
7.2. 更新
sudo
apt-get update
7.3. 安装
sudo
apt-get install oracle-java8-installer
注意:java默认安装在 /usr/lib/jvm文件夹下
7.4. 环境变量配置
sudo
gedit /etc/profile
export
JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JRE_HOME=$JAVA_HOME/jre
export
CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.5
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
export
LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/amd64/server:/usr/local/lib:$HADOOP_HOME/lib/native
export
JAVA_LIBRARY_PATH=$LD_LIBRARY_PATH:$JAVA_LIBRARY_PATH
souce
/etc/profile
8. 安装Hadoop
8.1. 解压hadoop
sudo
mkdir /usr/local/hadoop
sudo
tar zxvf hadoop-2.7.5.tar.gz -C /usr/local/hadoop
8.2. 创建目录
mkdir
/home/zyx/tmp
mkdir
/home/zyx/dfs
mkdir
/home/zyx/dfs/name
mkdir
/home/zyx/dfs/data
mkdir
/home/zyx/dfs/checkpoint
mkdir
/home/zyx/yarn
mkdir
/home/zyx/yarn/local
8.3. 修改Hadoop的配置文件
各配置文件在/usr/local/hadoop/hadoop-2.7.5/etc/hadoop/目录下
8.3.1. hadoop-env.sh
# The
java implementation to use.
#
export JAVA_HOME=${JAVA_HOME}
export
JAVA_HOME=/usr/lib/jvm/java-8-oracle
export
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.5
export
PATH=$PATH:/usr/local/hadoop/hadoop-2.7.5/bin
8.3.2. yarn-env.sh
#
some Java parameters
#
export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export
JAVA_HOME=/usr/lib/jvm/java-8-oracle
8.3.3. core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.60:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zyx/tmp</value>
</property>
</configuration>
8.3.4. hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.1.60:50070</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>192.168.1.60</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.60:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zyx/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/zyx/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/zyx/dfs/checkpoint</value>
</property>
</configuration>
8.3.5. mapred-site.xml
sudo
cp /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml.template
/usr/local/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.3.6. yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.60</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/zyx/yarn/local</value>
</property>
</configuration>
8.3.7. slave
sudo
gedit /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/slaves
192.168.1.60
9. Hadoop启动
9.1. HDFS文件的格式化
注意在zyx用户下
hadoop
namenode -format
9.2. DFS服务的启动与关停
注意在root用户下
cd
/usr/local/hadoop/hadoop-2.7.5/sbin/
sudo
./start-dfs.sh
sudo
./stop-dfs.sh
9.3. 查看数据节点信息
hadoop
dfsadmin -report
9.4. YARN服务的启动与关停
注意在root用户下
cd
/usr/local/hadoop/hadoop-2.7.5/sbin/
sudo
./start-yarn.sh
sudo
./stop-yarn.sh
9.5. 查看本机上已启动的服务
sudo
jps
9.6. HDFS的Web UI管理界面
http://192.168.1.60:50070/dfshealth.html#tab-overview

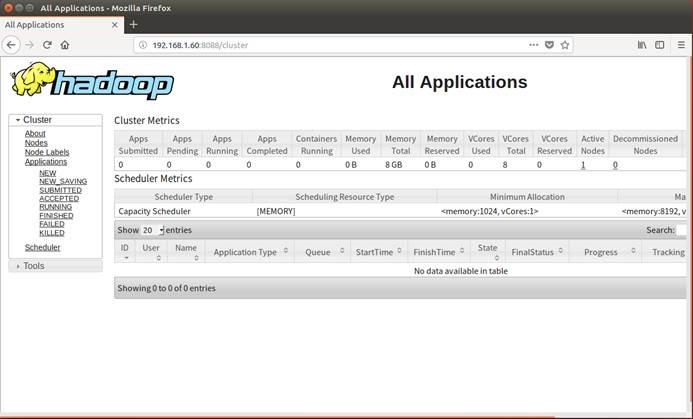
9.7. MapReduce应用的Web
UI管理界面
http://192.168.1.60:8088/cluster
10. 安装Eclipse
10.1. 解压eclipse
sudo
mv /home/zyx/software/eclipse-java-neon-3-linux-gtk-x86_64.tar.gz
/opt/
sudo
tar zxvf /opt/eclipse-java-neon-3-linux-gtk-x86_64.tar.gz
sudo
mkdir /opt/eclipse/workspace
10.2. 安装插件
sudo
mv /home/zyx/software/hadoop-eclipse-plugin-2.7.3.jar /opt/
sudo
cp /opt/hadoop-eclipse-plugin-2.7.3.jar /opt/eclipse/dropins/
ls
-la dropins/
10.3. 启动Eclipse
cd
/opt/eclipse/
sudo
./eclipse
11. 准备数据
11.1. 查找应用数据
sudo
cp /usr/local/hadoop/hadoop-2.7.5/NOTICE.txt /home/zyx/test.txt
sudo
chown zyx:zyx /home/zyx/test.txt
11.2. 将数据放入HDFS中
hadoop
fs -mkdir /input
hadoop
fs -put /home/zyx/test.txt /input
hadoop
fs -chmod -R 777 /input/test.txt
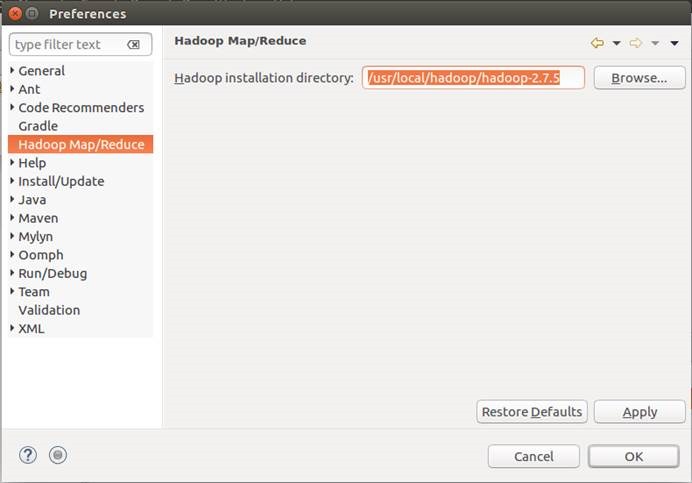
12. 配置Eclipse中的Hadoop设置
12.1. 设置Hadoop安装路径
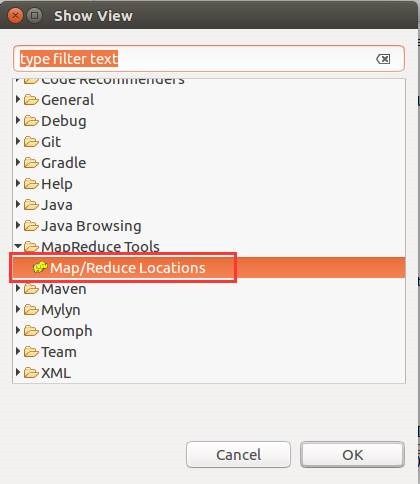
12.2. 设Eclipse的Hadoop视图

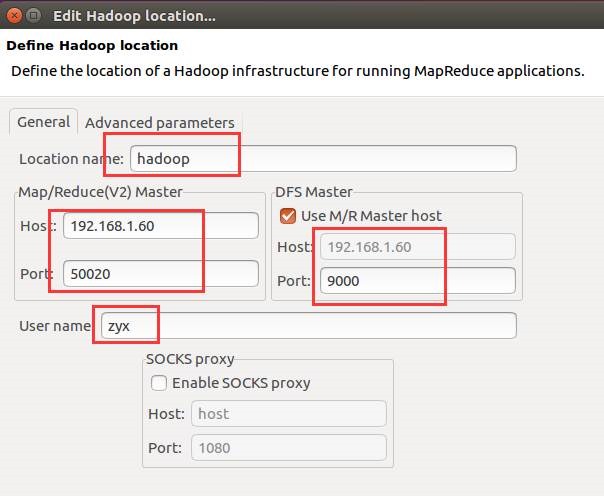
12.3. 连接HDFS

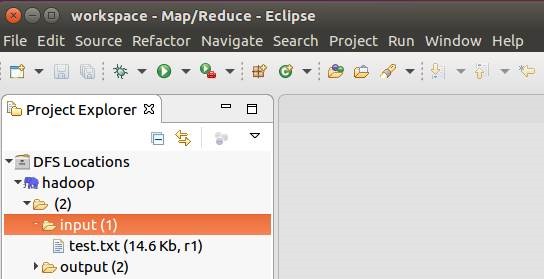
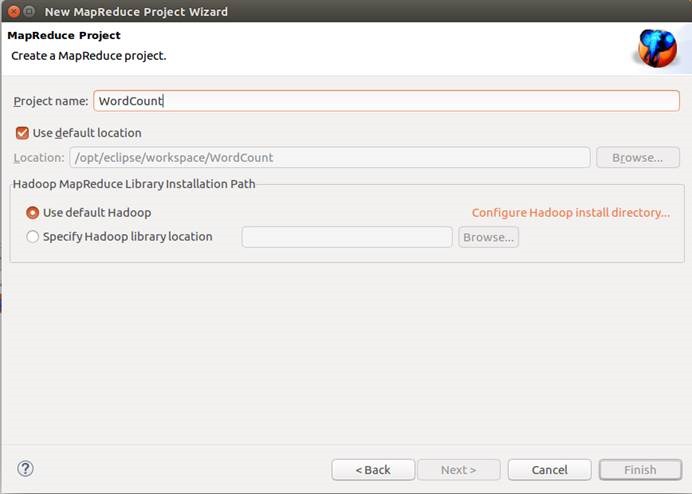
12.4. 新建MapReduce工程

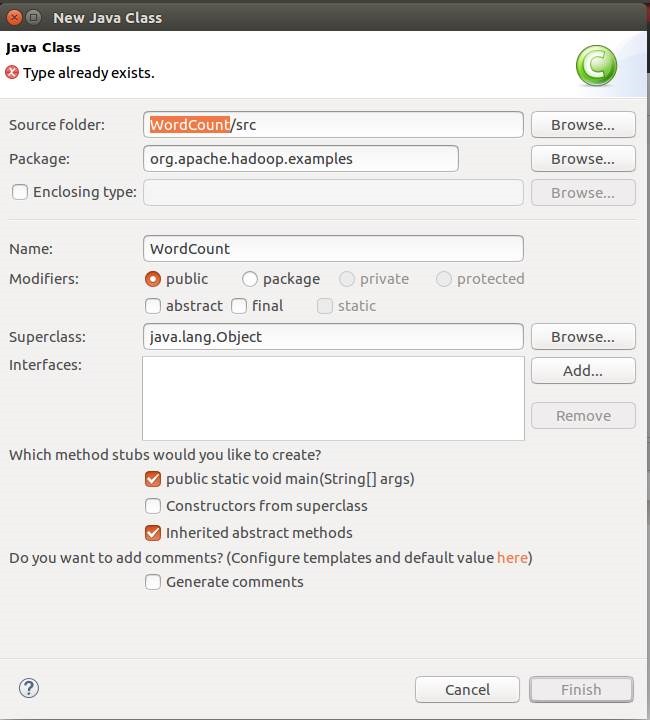
12.5. 新建运行的类

WordCount类中的内容
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import
org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import
org.apache.hadoop.mapreduce.Reducer;
import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public
class WordCount {
public
static
class
TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private
final
static
IntWritable one
= new IntWritable(1);
private
Text word
= new Text();
public
void
map(Object key,
Text value,
Context context)
throws IOException, InterruptedException {
StringTokenizer itr
= new
StringTokenizer(value.toString());
while
(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word,
one);
}
}
}
public
static
class
IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private
IntWritable result
= new IntWritable();
public
void
reduce(Text key,
Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int
sum = 0;
for
(IntWritable val
: values) {
sum
+= val.get();
}
result.set(sum);
context.write(key,
result);
}
}
public
static
void
main(String[] args)
throws Exception {
Configuration conf
= new Configuration();
Job job
= Job.getInstance(conf,
"word
count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,
new
Path(args[0]));
FileOutputFormat.setOutputPath(job,
new
Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
12.6. 新建日志配置文件log4j.properties
在src/目录下新建日志配置文件log4j.properties
其内容如下:
log4j.rootLogger=debug,
stdout,
R
#log4j.rootLogger=stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
#log4j.appender.stdout.layout.ConversionPattern=%5p -
%m%n
log4j.appender.stdout.layout.ConversionPattern=%d
%p
[%c]
-
%m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=log4j.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
#log4j.appender.R.layout.ConversionPattern=%p %t %c -
%m%n
log4j.appender.R.layout.ConversionPattern=%d
%p
[%c]
-
%m%n
#log4j.logger.com.codefutures=DEBUG
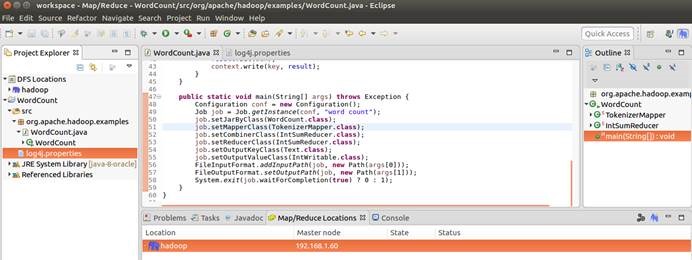
12.7. 运行
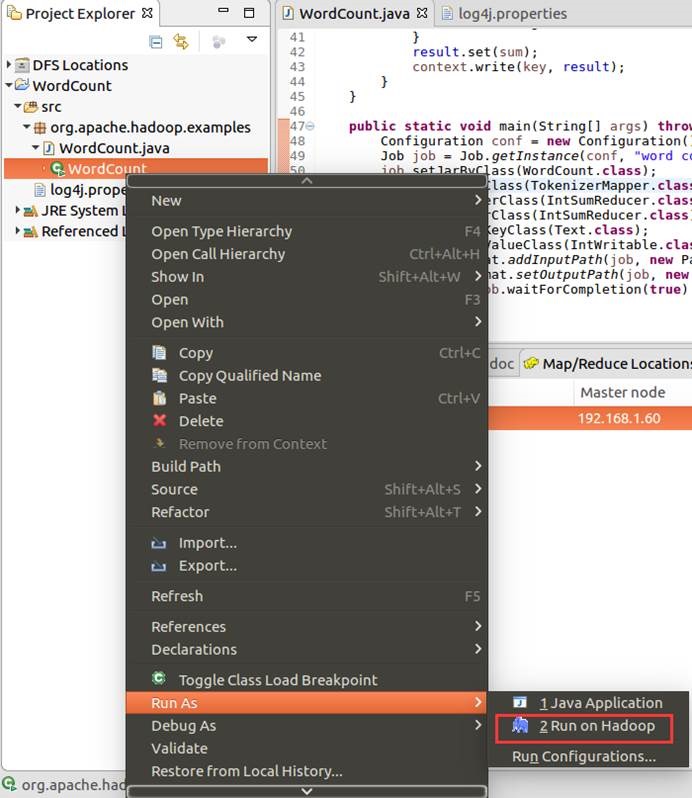
12.7.1. 运行环境设置

12.7.1.1. 设置输入与输出
hdfs://192.168.1.60:9000/input/test.txt
hdfs://192.168.1.60:9000/output
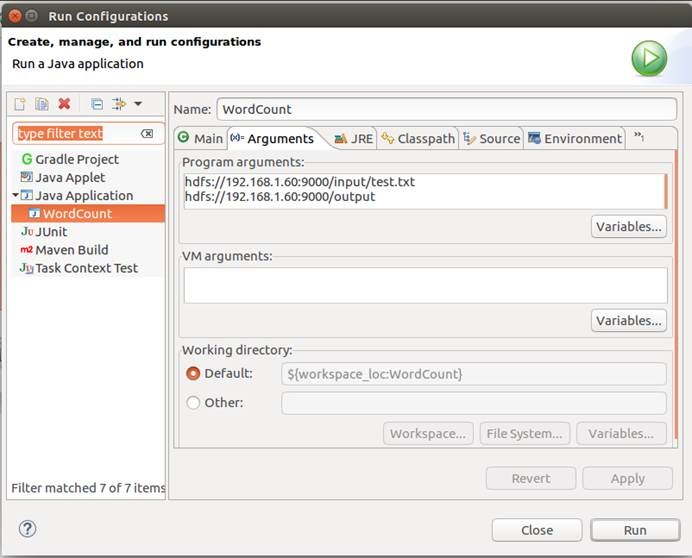
12.7.1.2. 设置环境变量
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.5
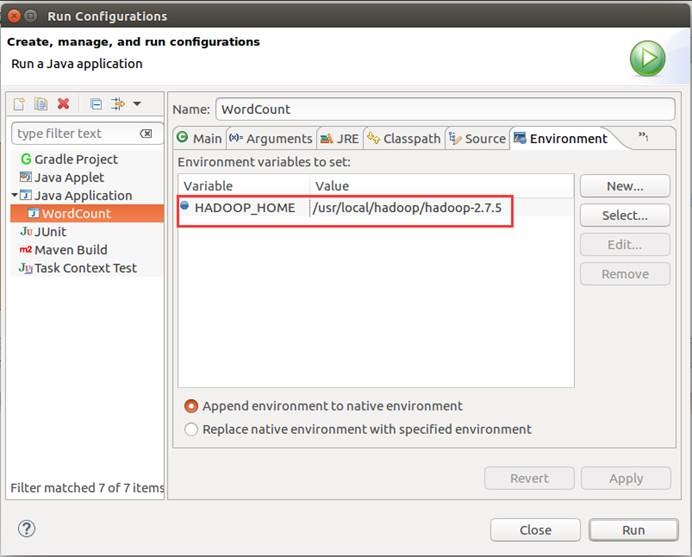
12.8. 启动运行
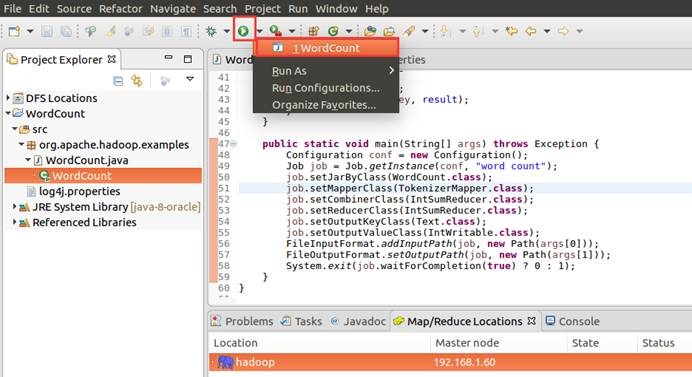
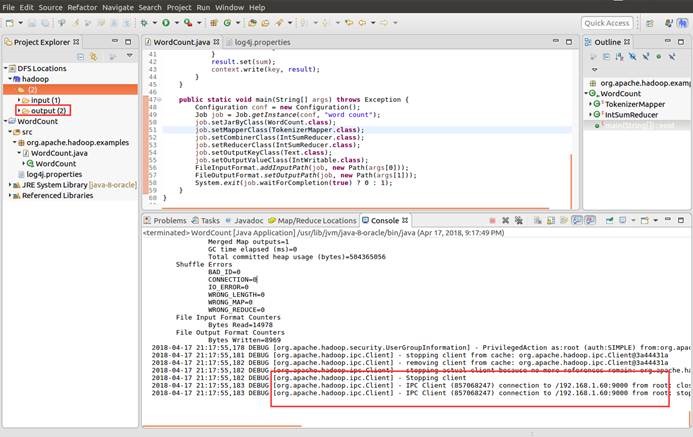
12.9. 查看运行结果

Ubuntu-16.04-Desktop +Hadoop2.7.5+Eclipse-Neon的云计算开发环境的搭建(伪分布式方式)的更多相关文章
- ubuntu 14.04/15.10 安装基于eclipse的android app开发环境
一开始是装了ubuntu15.10,不知道是我的x200机器太old还是iso镜像有问题,总是各种莫名的引导不起来.有时候刚刚装好的干净系统,只install了一个vim和openssh,重启,然后就 ...
- Ubuntu 12.04 Desktop下vncserver配置:Unity以及Xfce4桌面环境
将gnome改成xfce xfce-session 即可 2013-01-30 14:45:34| 分类: Ubuntu | 标签:ubuntu12.04 unity vncserver s ...
- <图文教程>VMware 14上Ubuntu 16.04 desktop版的安装
VMware14安装Ubuntu16.04教程 久闻Linux(这单词念做 林尼克斯??)大名,闲来无事就试着给自己笔记本装一个玩玩,从朋友口中得知可以在Vmware上装虚拟机,就自己试着尝试一下,顺 ...
- 安装 mysql5.7.2 (Ubuntu 16.04 desktop amd64)
1.下载mysql deb https://dev.mysql.com/downloads/mysql/ #移动到/usr/local/src/目录,解压 sudo mv mysql-server_5 ...
- 安装 mysql8.0.13 (Ubuntu 16.04 desktop amd64)
1.下载mysql deb https://dev.mysql.com/downloads/mysql/ #移动到/usr/local/src/目录,解压 sudo mv mysql-server_8 ...
- Ubuntu 16.04 LTS nodejs+pm2+nginx+git 基础安装及配置环境(未完,未整理)
-.Ubuntu 安装nodejs 以下内容均在命令行,完成,首先你要去你电脑的home目录:cd ~. [sudo] apt-get update [sudo] apt-get upgrade ap ...
- 十一招让Ubuntu 16.04用起来更得心应手(转)
ubuntu 16.04是一种长期支持版本(LTS),是Canonical承诺发布五年的更新版.也就是说,你可以让这个版本在电脑上运行五年! 这样一来,一开始就设置好显得特别重要.你应该确保你的软件是 ...
- 十招让Ubuntu 16.04用起来更得心应手(转)
ubuntu 16.04是一种长期支持版本(LTS),是Canonical承诺发布五年的更新版.也就是说,你可以让这个版本在电脑上运行五年! 这样一来,一开始就设置好显得特别重要.你应该确保你的软件是 ...
- Ubuntu 16.04 LTS 搭建ftp服务器
其实我之前搭建好了,但是最近我上来看好像跟没搭建一样呢,于是我从新搭建一遍? 我的ubuntu版本: cat /etc/issue Ubuntu 16.04 LTS \n \l 1.安装vsftpd( ...
随机推荐
- D03——C语言基础学习PYTHON
C语言基础学习PYTHON——基础学习D03 20180804内容纲要: 1 函数的基本概念 2 函数的参数 3 函数的全局变量与局部变量 4 函数的返回值 5 递归函数 6 高阶函数 7 匿名函数 ...
- 题解 P1731 【生日蛋糕】
题面传送门 如果不懂DFS,请自觉睡觉: 如果不懂剪枝,请自觉睡觉: 啊哈,大家的思路一定和我一样--DFS,找个数组存储半径和高,可是如单单使用DFS不加剪枝的话,10分--20分. 所以,我们来想 ...
- Ubuntu安装PhpStorm并设置快速启动phpstorm
使用sudo apt-get install phpstorm 安装php后,没有在桌面生成phpstorm的快捷方式,如果将phpstorm.sh的链接放到/usr/local/bin ,虽然可以从 ...
- MAC帧格式、IPV4数据报格式、TCP报文格式、UDP数据报格式
1.MAC帧格式 类型:2字节,指出数据域中携带的数据应交给哪些协议实体处理 校验码:校验数据段(采用32位CRC冗余校验方式进行校验) 2.IPV4数据报 版本:IP协议版本,这里为4 首部长度:占 ...
- Android-NDK处理用户交互事件
在 android_main(struct android_app* state)函数里面设置输入事件处理函数:state->onInputEvent = &handleInput;// ...
- Centos 添加用户和用户组
groupadd cheat useradd -g cheat cheat passwd cheat 密码设置jsb_6041
- 从入门到不放弃系列之Koa2
一.Koa2入门 本来是想Express入门的,但是既然都是要学,干嘛不学最新的呢? 其实我想说,我本来只是想学个小程序开发,现在已经陆陆续续开了好多坑了.. 本文参考廖雪峰教程 二.Async 最新 ...
- 玩转mongodb(二):mongodb基础知识
常用基本数据类型: null null用于表示空值或者不存在的字段: {"data":null} 布尔型 布尔类型只有两个值,true和false: {"data&quo ...
- session中用户信息改变问题
问题描述: 在web项目中,我们经常将用户登录信息放在session中用来做后续的权限判断等操作,但最近在项目中发现一个奇怪的现象,session中的用户信息和登录时的信息有了差异. 原因: 在后台代 ...
- babel使用入门以及使用webpack+babel来"编译"你的JS代码
Babel是一个广泛使用的转码器,可以将ES6代码转为ES5,从而在现有的环境中执行. 这是一个开端,以后遇到问题,也会持续记录. 一.babel配置 官网有更详细的配置教程:https://www. ...