安装部署 OpenPAI Install OpenPAI on Ubuntu
介绍
不管是机器学习的老手,还是入门的新人,都应该装备上尽可能强大的算力。除此之外,还要压榨出硬件的所有潜力来加快模型训练。OpenPAI作为GPU管理的利器,不管是一块GPU,还是上千块GPU,都能够做好调度,帮助加速机器学习的模型训练过程。
关于什么是OpenPAI,请参考介绍视频:微软开源GPU集群管理利器。
本文提供了简化的OpenPAI安装步骤。如果有更复杂的安装要求或部署环境,请参考官网。
准备工作
环境要求如下:
- 推荐Ubuntu 16.04 LTS(暂不支持CentOS等其它Linux系统)。
- 静态IP地址。
- 能够访问外网,可下载Docker Hub的镜像文件。
- 为集群中每台机器提供统一的用户名密码,并有sudo权限。
- 有统一的时间同步服务(默认即可)。
- 推荐干净环境进行安装。如果已经安装了Docker,API版本必须大于等于1.26。
- 各台计算机之间网络可达。
根据官方文档,集群节点的内存至少12G,推荐分配多一点,本例中分配了32G。
https://github.com/Microsoft/pai/wiki/Resource-Requirement
For SingleBox installation, we reserve 40G memory for OS and Kubernetes, memory for user jobs is total_mem - 40g. For cluster installation, each PAI-Worker reserve 12G memory for OS and K8S, memory for user jobs is total_mem - 12g.

可以看到刚搭好的master节点已经使用了不少内存
安装过程
0. 修改docker 源
新版的 Docker 使用 /etc/docker/daemon.json(Linux) 或者 %programdata%\docker\config\daemon.json(Windows) 来配置 Daemon。
请在该配置文件中加入(没有该文件的话,请先建一个):
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
1. 安装用于配置的docker
即管理、安装整个OpenPAI的docker(在官方文档中称为dev-box)。以后的管理、配置工作都会在这个docker中进行。
登录进某台计算机(可选用集群中的机器),确保有sudo权限。然后按顺序执行下列命令。
安装docker,如果安装有更新的版本可跳过。
sudo apt-get -y install docker.io ssh ntp
注意:集群安装时需要用另外一台独立于集群的专门电脑来安装!
Notice that dev-box should run on a machine outside of PAI cluster, it shouldn't run on any PAI cluster node.
# 拉取,并启动dev-box
sudo docker run -itd -e COLUMNS=$COLUMNS -e LINES=$LINES -e TERM=$TERM -v /var/lib/docker:/var/lib/docker -v /var/run/docker.sock:/var/run/docker.sock -v /pathHadoop:/pathHadoop -v /pathConfiguration:/cluster-configuration --pid=host --privileged=true --net=host --name=dev-box docker.io/openpai/dev-box # 登录dev-box
sudo docker exec -it dev-box /bin/bash
2. 配置安装环境
以下脚本需要修改一下安装环境相关的信息。machines表示GPU集群的服务器IP,ssh-username和ssh-password分别代表登录这些服务器要用到的用户名、密码。
注意:第一台会作为master节点,其余节点作为worker。关于master/worker可参考视频介绍。暂时推荐不要用GPU服务器做master角色,或将worker角色部署到master上,因为这样可能会造成资源紧张,从而造成master进程的内存不够用。所以,master节点可以用没有GPU的服务器,推荐8核16G或以上配置。
cd /pai/pai-management cat << EOF > quick-start.yaml
machines:
- 192.168.1.2
- 192.168.1.3 ssh-username: <用户名>
ssh-password: <密码>
EOF CONFIG_PATH=/cluster-configuration
rm $CONFIG_PATH/*
3. 安装节点
根据quick-start的基本信息,在/cluster-configuration目录中生成配置文件。配置文件的具体内容可参考github,这里就不详细介绍了。
python paictl.py cluster generate-configuration -i quick-start.yaml -o $CONFIG_PATH
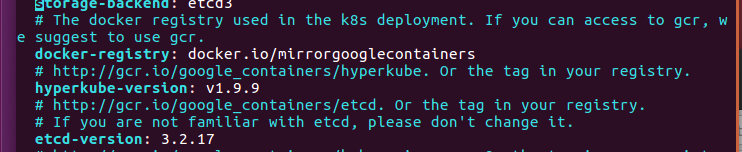
如果不能访问 gcr.io 运行下一步会导致以下错误
Unable to find image 'gcr.io/google_containers/hyperkube:v1.9.9' locally The connection to the server xxxxx:8080 was refused - did you specify the right host or port?
解决方法:
编辑 $CONFIG_PATH 下的配置文件 kubernetes-configuration.yaml

将
# The docker registry used in the k8s deployment. If you can access to gcr, we suggest to use gcr. docker-registry: gcr.io/google_containers
改为 change to :
docker-registry: docker.io/mirrorgooglecontainers
安装kubenetes
python paictl.py cluster k8s-bootup -p $CONFIG_PATH
自动安装好后的 master 节点上的 docker images 至少应该有这些

如果没有这些,建议清空 image 重来
docker ps -a
docker images
docker rm 'container id'
docker rmi 'image id'
安装并启动OpenPAI相关服务
python paictl.py service start -p $CONFIG_PATH
运行最后一步时,如果网速很慢或服务器很多,可能会等待很久。完成后,即可在浏览器中试着访问第一台服务器的web地址。因为服务器还需要启动一会儿,可能并不能马上看到结果。等一会儿,或者多试几次即可。
默认的用户名、密码如下,可点击右上方的login连接登录。建议第一时间改掉。
安装好后访问
masterip:9090
masterip:9286
admin
admin-password
装好后界面
好了!大功告成!
可以参考github中的任务模板来配置自己的任务模板。也可以看看Github中的文档来探索更多高级功能。接下来就可以学习如何从Tools for AI来提交任务了。
如果集群比较小,可以给集群去掉end-to-end测试用例,从而节省资源。(参考常见问答)
常见问题
遇到问题,可在官网提交Issue。
如何删除end-to-end测试任务?
如果没有足够的服务器资源,建议在部署过程中删除掉end-to-end测试。否则,它会定期进入队列,以测试系统是否可用。在dev-box中运行:
python paictl.py service delete -p $CONFIG_PATH -n end-to-end-test
安装过程中出现 ... is not ready yet. Please wait for a moment!,该怎么办?
这种一般是网络问题造成的,可以进入以下网址(注意替换master IP),将出现pull image错误的pods删掉,加快Kubernetes重新pull的速度。
http://<替换成master的IP>:9090/#!/pod?namespace=default
安装部署 OpenPAI Install OpenPAI on Ubuntu的更多相关文章
- vue.js的安装部署+cnpm install 安装过程卡住不动----亲测可用
1.到Node.js的官网下载node node.js的下载地址,下载完成后,我在d盘新建一个文件夹“node”, 安装到node目录下(安装之后环境变量自动配置了,自己无需再配),比如我的安装路径是 ...
- redis cluster安装部署(测试环境)
redis 应用于web前端,做缓存和数据存取的速度是挺可观的,最近看了一些资料,手痒了,就弄了一个测试环境,两台方案,试用一下. ##Redis 集群部署## 一,方案调研: 参考博客: http: ...
- OpenPAI大规模人工智能平台安装部署文档
环境要求: 如果需要图形界面,需要在Ubuntu系统安装,否则centos系统安装时是没有问题的(web端和命令行进行任务提交) 安装过程需要有另外一台控制端机器(注意:区别于集群所在的任何一台服务器 ...
- 在Ubuntu 12.10 上安装部署Openstack
OpenStack系统有几个关键的项目,它们能够独立地安装但是能够在你的云计算中共同工作.这些项目包括:OpenStack Compute,OpenStack Object Storage,OpenS ...
- Ubuntu 16.04+.Net Core+Docker+Uginx安装部署
前言 最近公司的项目打算移植到.Net Core平台,所以调研了一下.Net Core在Linux下的安装部署.本篇文章会一步步的描述从安装到配置到部署的全部过程.在文章的结构和内容里,笔者借鉴了很多 ...
- Ubuntu 18.04 安装部署Net Core、Nginx全过程
Ubuntu 18.04 安装部署Net Core.Nginx全过程 环境配置 Ubuntu 18.04 ,Nginx,.Net Core 2.1, Let's Encrypt 更新系统 sudo a ...
- Ubuntu下安装部署MongoDB以及设置允许远程连接
最近因为项目原因需要在阿里云服务器上部署MongoDB,操作系统为Ubuntu,网上查阅了一些资料,特此记录一下步骤. 1.运行apt-get install mongodb命令安装MongoDB服务 ...
- hadoop2 Ubuntu 下安装部署
搭建Hadoop环境( 我以hadoop 2.7.3 为例, 系统为 64bit Ubuntu14.04 ) hadoop 2.7.3 官网下载 , 选择自己要安装的版本.注意每个版本对应两个下载选项 ...
- Ubuntu中安装部署Intel CS WebRTC
1环境要求 组件 版本要求 OS CentOS* 7.4, Ubuntu 14.04/16.04 LTS Node 8.11.* (推荐8.11.1) MongoDB 2.4.9 Boost 1.65 ...
随机推荐
- 支付宝小程序自定义弹窗插件|支付宝dialog插件|model插件
支付宝小程序自定义弹窗组件wcPop|小程序自定义对话框|actionSheet弹窗模板 支付宝小程序官方提供的alert提示框.dialog对话框.model弹窗功能比较有限,有些都不能随意自定义修 ...
- RDLC_部署到不同的浏览器
首先我用的是vs2015 的reportview插件 在数据库中应该配置报表的服务器地址,在项目中添加ReportViewer 插件,单独用一个页面显示接收报表 <form id="f ...
- 八、Linux上常用网络操作
1. 主机名配置 hostname 查看主机名 hostname xxx 修改主机名 重启后无效 如果想要永久生效,可以修改/etc/sysconfig/network文件 2. IP地址配置 set ...
- Install MySql on CentOS
Installing & Configuring MySQL Server This Howto will show you how to install MySQL 5.x, start t ...
- JVM-Java GC分析
如何获取JavaGC日志 用动态命令查看: jstat -gc 1262 2000 20 每隔20秒输入一次日志,总共输入20次 设置GC参数打印出日志 -XX:+PrintGC 输出GC日志 -X ...
- mysql数据库修改字符编码问题
遇到这种情况,现有项目的数据库已经建好,数据表也已经创建完成. 问题来的,数据库不能插入中文,调试时候发现中文数据从发送请求到最后请求处理完成这些步骤,中文还没有发生乱码. 只有在存储到数据库后查询数 ...
- mongodb 数据库备份脚本
写了小shell bash, 用于给mongodb数据进行备份 #!/bin/bash #backup MongoDB #文件目录 #backup MongoDB #!/bin/bash #backu ...
- 值得收藏的TCP套接口编程文章
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由jackieluo发表于云+社区专栏 TCP客户端-服务器典型事件 下图是TCP客户端与服务器之间交互的一系列典型事件时间表: 首先启 ...
- JAVA 图像操作辅助类
package util; import java.awt.Component; import java.awt.Image; import java.awt.MediaTracker; import ...
- java内存中的对象
前记:几天前,在浏览网页时偶然的发现一道以前就看过很多遍的面试题,题目是:“请说出‘equals’和‘==’的区别”,当时我觉得我还是挺懂的,在心里答了一点(比如我们都知道的:‘==’比较两个引用是否 ...