4-[多进程]-互斥锁、Queue队列、生产者消费者
1.互斥锁
(1)为什么需要互斥锁
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,
而共享带来的是竞争,竞争带来的结果就是错乱,如下
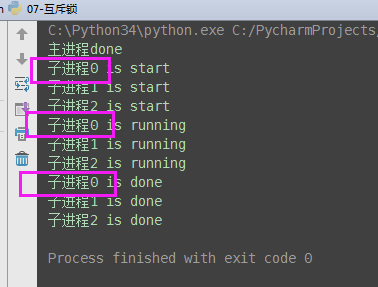
#并发运行,效率高,但竞争同一打印终端,带来了打印错乱
from multiprocessing import Process
import os,time
def work():
print('%s is running' %os.getpid())
time.sleep(2)
print('%s is done' %os.getpid()) if __name__ == '__main__':
for i in range(3):
p=Process(target=work)
p.start()
(2)如何加锁
如何控制,就是加锁处理。而互斥锁的意思就是互相排斥, 如果把多个进程比喻为多个人,互斥锁的工作原理就是多个人都要去争抢同一个资源:卫生间,一个人抢到卫生间后上一把锁,其他人都要等着,等到这个完成任务后释放锁,其他人才有可能有一个抢到...... 所以互斥锁的原理,就是把并发改成穿行,降低了效率,但保证了数据安全不错乱
#由并发变成了串行,牺牲了运行效率,但避免了竞争
from multiprocessing import Process,Lock
import os,time
def work(lock):
lock.acquire() #加锁
print('%s is running' %os.getpid())
time.sleep(2)
print('%s is done' %os.getpid())
lock.release() #释放锁
if __name__ == '__main__':
lock=Lock()
for i in range(3):
p=Process(target=work,args=(lock,))
p.start()

2、模拟抢票练习
(1)多个进程共享同一文件,我们可以把文件当数据库,用多个进程模拟多个人执行抢票任务

#文件db.txt的内容为:{"count":1}
#注意一定要用双引号,不然json无法识别
from multiprocessing import Process
import time,json
def search(name):
dic=json.load(open('db.txt'))
time.sleep(1)
print('\033[43m%s 查到剩余票数%s\033[0m' %(name,dic['count']))
def get(name):
dic=json.load(open('db.txt'))
time.sleep(1) #模拟读数据的网络延迟
if dic['count'] >0:
dic['count']-=1
time.sleep(1) #模拟写数据的网络延迟
json.dump(dic,open('db.txt','w'))
print('\033[46m%s 购票成功\033[0m' %name)
def task(name):
search(name)
get(name)
if __name__ == '__main__':
for i in range(10): #模拟并发10个客户端抢票
name='<路人%s>' %i
p=Process(target=task,args=(name,))
p.start()
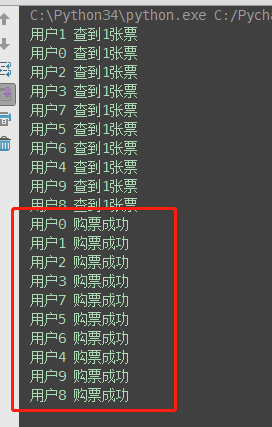
并发运行,效率高,但竞争写同一文件,数据写入错乱,只有一张票,卖成功给了10个人
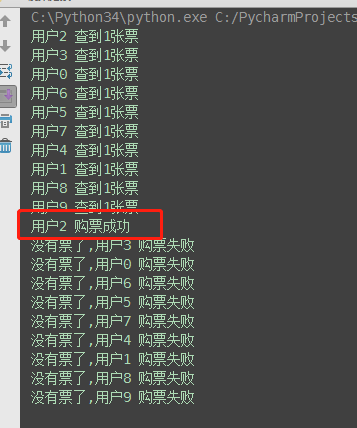
(2)加锁处理:购票行为由并发变成了串行,牺牲了运行效率,但保证了数据安全



4、互斥锁与join
join方法:可以将并发变成串行,join是将一个任务整体串行,
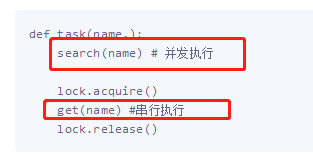
互斥锁的原理:也是将并发变成串行,互斥锁的好处则是可以将一个任务中的某一段代码串行,比如只让task函数中的get任务串行 join将并发改成穿行,确实能保证数据安全,但问题是连查票操作也变成只能一个一个人去查了,
很明显大家查票时应该是并发地去查询而无需考虑数据准确与否,
此时join与互斥锁的区别就显而易见了

5、互斥锁总结


6、队列的使用Queue
进程彼此之间互相隔离,要实现进程间通信(IPC),
multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的
创建队列的类(底层就是以管道和锁定的方式实现):
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
参数介绍:
maxsize是队列中允许最大项数,省略则无大小限制。
但需要明确:
1、队列内存放的是消息而非大数据
2、队列占用的是内存空间,因而maxsize即便是无大小限制也受限于内存大小
主要方法介绍:
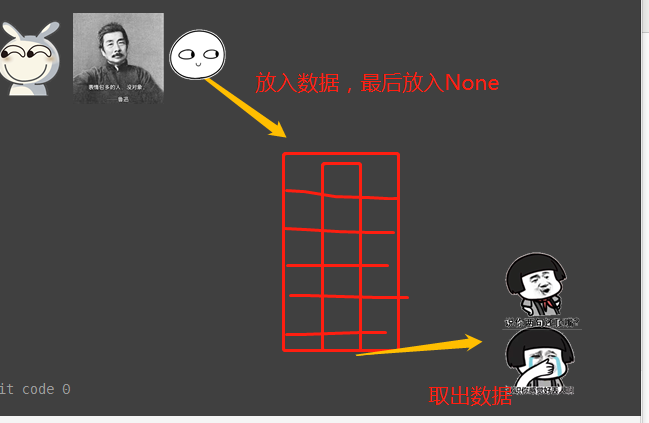
q.put方法用以插入数据到队列中。
q.get方法可以从队列读取并且删除一个元素。
队列的使用

7、生产者消费者模型介绍
(1)为什么要使用生产者消费者模型
生产者指的是生产数据的任务,消费者指的是处理数据的任务,
在并发编程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。
同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。
为了解决这个问题于是引入了生产者和消费者模式。
(2)什么是生产者和消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,
所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取, 阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这个阻塞队列就是用来给生产者和消费者解耦的

8、生产者消费者模型实现
(1)版本1:简易版
from multiprocessing import Process,Queue
import time # 生产者函数
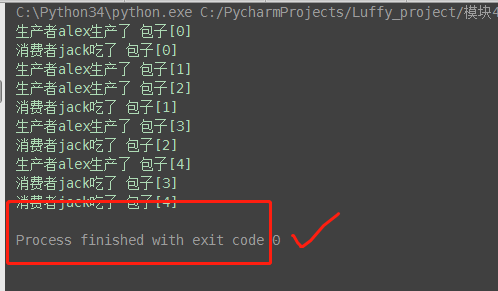
def producer(name, q):
for i in range(5):
time.sleep(0.5)
print('生产者%s生产了 包子[%s]' % (name, i))
q.put('包子[%s]' % i) # 消费者函数
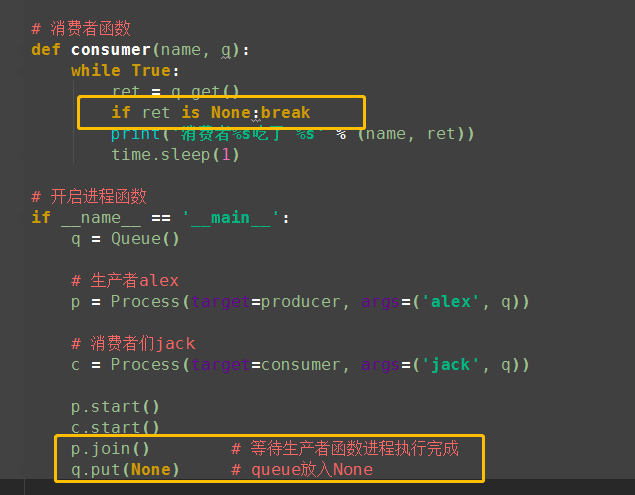
def consumer(name, q):
while True:
ret = q.get()
print('消费者%s吃了 %s' % (name, ret))
time.sleep(1) # 开启进程函数
if __name__ == '__main__':
q = Queue() # 生产者alex
p = Process(target=producer, args=('alex', q)) # 消费者jack
c = Process(target=consumer, args=('jack', q)) p.start()
c.start()


(2)版本2:解决阻塞问题
但上述解决方式,在有多个生产者和多个消费者时,我们则需要用一个很low的方式去解决,有几个消费者就需要发送几次结束信号:相当low,例如
10、JoinableQueue([maxsize]):发送结束信号
其实我们的思路无非是发送结束信号而已,有另外一种队列提供了这种机制
JoinableQueue([maxsize])
这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
参数介绍
maxsize是队列中允许最大项数,省略则无大小限制。
方法介绍
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
q.task_done():使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常
q.join():生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止
基于JoinableQueue实现生产者消费者模型
from multiprocessing import Process,Queue, JoinableQueue
import time # 生产者函数
def producer(name, q):
for i in range(3):
time.sleep(0.8)
print('生产者%s生产了 包子[%s]' % (name, i))
q.put('包子[%s]' % i)
q.join() # 等到消费者把自己放入队列中的所有的数据都取走之后,生产者才结束 # 消费者函数
def consumer(name, q):
while True:
time.sleep(1)
ret = q.get()
if ret is None:break
print('消费者%s吃了 %s' % (name, ret))
q.task_done() # 发送信号给q.join(),说明已经从队列中取走一个数据并处理完毕了 # 开启进程函数
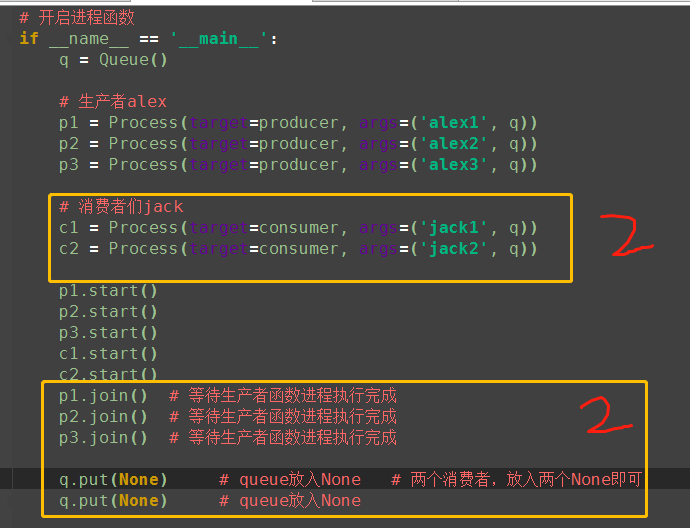
if __name__ == '__main__':
q = JoinableQueue() # 生产者alex
p1 = Process(target=producer, args=('alex1', q))
p2 = Process(target=producer, args=('alex2', q))
p3 = Process(target=producer, args=('alex3', q)) # 消费者们jack
c1 = Process(target=consumer, args=('jack1', q))
c2 = Process(target=consumer, args=('jack2', q))
c1.daemon = True
c2.daemon = True # 设置守护进程 p1.start()
p2.start()
p3.start()
c1.start()
c2.start()
p1.join() # 等待生产者函数进程执行完成
p2.join() # 等待生产者函数进程执行完成
p3.join() # 等待生产者函数进程执行完成

11、总结

4-[多进程]-互斥锁、Queue队列、生产者消费者的更多相关文章
- #queue队列 #生产者消费者模型
#queue队列 #生产者消费者模型 #queue队列 #有顺序的容器 #程序解耦 #提高运行效率 #class queue.Queue(maxsize=0) #先入先出 #class queue.L ...
- 守护进程,互斥锁,IPC,队列,生产者与消费者模型
小知识点:在子进程中不能使用input输入! 一.守护进程 守护进程表示一个进程b 守护另一个进程a 当被守护的进程结束后,那么守护进程b也跟着结束了 应用场景:之所以开子进程,是为了帮助主进程完成某 ...
- 守护模式,互斥锁,IPC通讯,生产者消费者模型
'''1,什么是生产者消费者模型 生产者:比喻的是程序中负责产生数据的任务 消费者:比喻的是程序中负责处理数据的任务 生产者->共享的介质(队列)<-消费者 2,为何用 实现了生产者与消费 ...
- python2.0_s12_day9之day8遗留知识(queue队列&生产者消费者模型)
4.线程 1.语法 2.join 3.线程锁之Lock\Rlock\信号量 4.将线程变为守护进程 5.Event事件 * 6.queue队列 * 7.生产者消费者模型 4.6 queue队列 que ...
- Python学习笔记——进阶篇【第九周】———线程、进程、协程篇(队列Queue和生产者消费者模型)
Python之路,进程.线程.协程篇 本节内容 进程.与线程区别 cpu运行原理 python GIL全局解释器锁 线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Ev ...
- [并发编程 - socketserver模块实现并发、[进程查看父子进程pid、僵尸进程、孤儿进程、守护进程、互斥锁、队列、生产者消费者模型]
[并发编程 - socketserver模块实现并发.[进程查看父子进程pid.僵尸进程.孤儿进程.守护进程.互斥锁.队列.生产者消费者模型] socketserver模块实现并发 基于tcp的套接字 ...
- 网络编程基础----并发编程 ---守护进程----同步锁 lock-----IPC机制----生产者消费者模型
1 守护进程: 主进程 创建 守护进程 辅助主进程的运行 设置进程的 daemon属性 p1.daemon=True 1 守护进程会在主进程代码执行结束后就终止: 2 守护进程内无法再开启子进程 ...
- Python并发编程03 /僵孤进程,孤儿进程、进程互斥锁,进程队列、进程之间的通信
Python并发编程03 /僵孤进程,孤儿进程.进程互斥锁,进程队列.进程之间的通信 目录 Python并发编程03 /僵孤进程,孤儿进程.进程互斥锁,进程队列.进程之间的通信 1. 僵尸进程/孤儿进 ...
- python 并发编程 多进程 互斥锁 目录
python 并发编程 多进程 互斥锁 模拟抢票 互斥锁与join区别
- python并发编程之多进程(二):互斥锁(同步锁)&进程其他属性&进程间通信(queue)&生产者消费者模型
一,互斥锁,同步锁 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的, 竞争带来的结果就是错乱,如何控制,就是加锁处理 part1:多个进程共享同一打印终 ...
随机推荐
- 如何快速的给你的项目添加icon图标
如何快速的给你的项目添加icon图标 下载软件 如何制作图片 将制作的图标拖到项目当中 设置启动页 注意: 如果手动添加了启动页的话,记得将Launch Screen中的东西清除掉
- 在 vSphere 5.x/6.0 中配置 Network Dump Collector 服务 (2002954)
vmware KB: https://kb.vmware.com/s/article/2002954?lang=zh_CN 重点配置命令: 使用 vSphere Client 连接到 vCenter ...
- Alpha 冲刺报告(8/10)
Alpha 冲刺报告(8/10) 队名:洛基小队 峻雄(组长) 已完成:关于角色属性的脚本编码 明日计划:提升脚本的完成度 剩余任务:角色的属性脚本 困难:缺乏编程经验,很难自己独立完成编写,只能根据 ...
- foreach 计数
foreach(var item in list.Select((x, i) => new { x, i })){ User user = item.x; int Idx = ite ...
- css3画图那些事(三角形、圆形、梯形等)
闲来无事,写写图形.当时巩固一下css3吧..前端小白,写的不好还请前辈多指教. 三角形 { width:; height:; border-bottom: 140px solid red ; bor ...
- sql: having使用,及删除重复数据
写了好几年的sql,having语句基本上很少写,这就有一点尴尬了,现在总结一下having的作用,每日整理一下学习文档. having 通常伴随group by使用,过滤group by的数据集. ...
- NSProxy应用例子
动态代理模式的应用很多,特别是在不能修改被代理类的前提下,要对执行某些方法时需要打log或者捕捉异常等处理时,是一个非常方便的方法.只需要少量修改客户端(场景类)代码和添加一个代理类就可以实现,这个符 ...
- 线性dp
线性dp应该是dp中比较简单的一类,不过也有难的.(矩乘优化递推请出门右转) 线性dp一般是用前面的状态去推后面的,也有用后面往前面推的,这时候把循环顺序倒一倒就行了.如果有的题又要从前往后推又要从后 ...
- JS 兼容大全
//获取浏览器可视区宽度 function getWidth() { if (window.innerWidth){ return window.innerWidth; } else{ if (doc ...
- 集合之subList的缺陷
我们经常使用subString方法来对String对象进行分割处理,同时我们也可以使用subList.subMap.subSet来对List.Map.Set进行分割处理,但是这个分割存在某些瑕疵. 一 ...