用Fluent实现MySQL到ODPS数据集成
安装ruby
首先通过 /etc/issue 命令查看当前使用centos是哪个版本:
[hadoop@hadoop03 ~]$ cat /etc/issue

由于centos版本是6.6,安装ruby时就要选择在centos 6.X环境,具体安装步骤参考如下所示即可!
yum install gcc-c++ patch readline readline-devel zlib zlib-devel libyaml-devel libffi-devel openssl-devel make bzip2 autoconf automake libtool bison iconv-devel wget tar
wget https://ruby.taobao.org/mirrors/ruby/ruby-2.2.3.tar.gz
cd ruby-2.2.3
./configure
查看验证

安装fluent-plugin-sql插件(输入源)

准备MySQL表及数据
其中id是主键,自增
备注:
grant ALL PRIVILEGES ON *.* to dong@"172.16.1.158" identified by "123456" WITH GRANT OPTION;
flush privileges;
准备ODPS测试表
编辑fluent.conf配置文件
state_file /var/run/fluentd/sql_state 配置项 (path to a file to store last rows该文件默认不存在,需要提前创建好!)
state_file stores last selected rows to a file (named state_file) to not forget last row when Fluentd restarts.
[root@hadoop03 ~]# vi /etc/fluent/fluent.conf --编辑fluent.conf配置文件
启动fluent
fluentd --启动命令
如果安装Fluentd 用的是Ruby Gem,可以创建一个配置文件运行下面命令。发出一个终止信号将会重新安装配置文件。(如果修改了配置文件—fluent.conf 文件,ctrl c 终止进程,然后在配置文件下重新启动)
$ ctrl c
$ fluentd -c fluent.conf

运行过程遇到异常及排查

(2)在fluent.conf配置正确基础上运行fluentd启动命令,又报以下异常:
这个问题是mysql插件需要用到mysql adapter适配器,需要安装mysql adapter适配器,执行以下命令:
[root@hadoop03 fluent]# yum install mysql-devel
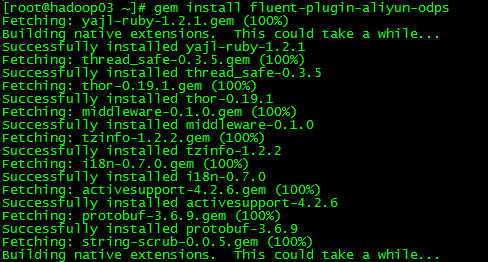
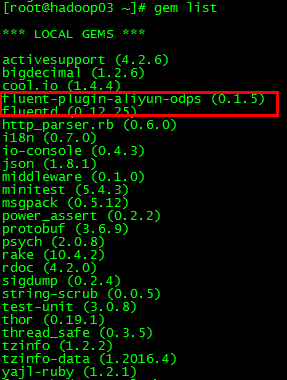
gem安装插件时遇到异常及排查

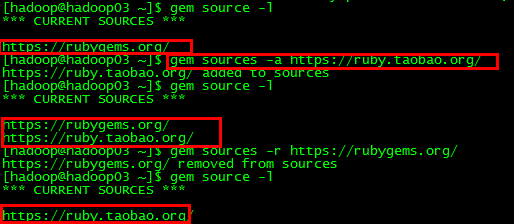
由于gem源引起,需要加上淘宝源后要把原来那个rubygems那个删掉
gem sources -r https://rubygems.org/
gem sources -a https://ruby.taobao.org/
没有写入执行权限
用Fluent实现MySQL到ODPS数据集成的更多相关文章
- 数据集成工具Kettle、Sqoop、DataX的比较
数据集成工具很多,下面是几个使用比较多的开源工具. 1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).H ...
- Spring 4 MVC+Hibernate 4+MySQL+Maven使用注解集成实例
Spring 4 MVC+Hibernate 4+MySQL+Maven使用注解集成实例 转自:通过注解的方式集成Spring 4 MVC+Hibernate 4+MySQL+Maven,开发项目样例 ...
- 【ODI】| 数据ETL:从零开始使用Oracle ODI完成数据集成(三)
资料库的创建.体系结构的创建.模型反向工程都已经完成了,下面就是创建以及执行接口来完成工作了. 浏览前两节请点击: [ODI]| 数据ETL:从零开始使用Oracle ODI完成数据集成(一) [OD ...
- 【ODI】| 数据ETL:从零开始使用Oracle ODI完成数据集成(一)
0. 环境说明及软件准备 ODI(Oracle Data Integrator)是Oracle公司提供的一种数据集成工具,能高效地实现批量数据的抽取.转换和加载.ODI可以实现当今大多数的主流关系型数 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- DataPipeline CTO陈肃:从ETL到ELT,AI时代数据集成的问题与解决方案
引言:2018年7月25日,DataPipeline CTO陈肃在第一期公开课上作了题为<从ETL到ELT,AI时代数据集成的问题与解决方案>的分享,本文根据陈肃分享内容整理而成. 大家好 ...
- 资料:MVC框架+SQL Server 数据集成引擎
ylbtech-资料:MVC框架+SQL Server 数据集成引擎 1.返回顶部 1. 功能特点: MVC框架耦合性低视图层和业务层分离,这样就允许更改视图层代码而不用重新编译模型和控制器代码,同样 ...
- 数据集成工具:Teiid实践
数据集成是把不同来源.格式.特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享.数据集成的方式多种多样,这里介绍的 Teiid 是其中的一种:通过抽象和联邦技术,实现分布式数据源的 ...
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
随机推荐
- asp.net 在repeater控件中加按钮
在repeater中加入方法有两种方法: 第一种:是对repeater控件的行添加OnItemCommand事件,添加方法也是有两种 1.在设计页面中,选中repeater控件右击==>属性== ...
- Android学习笔记_55_Tween动画 (渐变、缩放、位移、旋转)
Android 平台提供了两类动画. 一类是Tween动画,就是对场景里的对象不断的进行图像变化来产生动画效果(旋转.平移.放缩和渐变).第二类就是 Frame动画,即顺序的播放事先做好的图像,与gi ...
- TDD:代码可测试设计
1 方法内部代码命令,查询分离. a . 命令方法:执行一系列动作. b. 查询方法: 执行查询动作,并返回值. 2 一个类中有好几个地方都用到了一个或多个全局变量,可以考虑把全局变量封装到另外 ...
- Access用OleDbParameter更新/插入数据
/// <summary> /// 更新一条数据 /// </summary> public void Update(ZPY.Model.News model) { Strin ...
- c语言描述的顺序表实现
//顺序表的实现:(分配一段连续地址给顺序表,像数组一样去操作) #include<stdio.h> #include<stdlib.h> #define OK 1 #defi ...
- js中的throw err的作用
1.阻止程序的运行 2.把错误消息打到控制台
- cefsharp作为采集工具(学习笔记)
cefsharp(webkit内核)浏览器替代webbrowser用来采集页面数据. 需要在页面form加载完毕,用异步方式自动获取sourcecode. 由于国内cefsharp的资料相对比较少,在 ...
- JSP/Servlet开发——第六章 JSP开发业务应用
1. 大容量的数据显示的缺点: ●当数据量较多时,用户需要拖动页面才能浏览更多信息: ●数据定位不便: 2.分页显示: ●既能显示多条数据,又不需要拖动页面,是数据更加清晰直观,页面不再冗长,也不受数 ...
- python 方法解析顺序 mro
一.概要: mor(Method Resolution Order),即方法解析顺序,是python中用于处理二义性问题的算法 二义性: 1.两个基类,A和B都定义了f()方法,c继承A和B那么C调用 ...
- MySQL innodb表使用表空间物理文件复制或迁移表
MySQL InnoDB引擎的表通过拷贝物理文件来进行单表或指定表的复制,可以想到多种方式,今天测试其中2种: 将innodb引擎的表修改为Myisam引擎,然后拷贝物理文件 直接拷贝innodb的表 ...