python----python使用mysql
Python操作MySQL主要使用两种方式:
原生模块 pymsql
ORM框架 SQLAchemy
pymql
pymsql是Python中操作MySQL的模块,在windows中的安装:
pip install pymysql
入门:我们连接虚拟机中的centos中的mysql,然后查询test数据库中student表的数据
import pymysql #创建连接
conn = pymysql.connect(host='192.168.123.207',port=3306,user='root',passwd='root',db="test"); #创建游标
cursor = conn.cursor() #执行sql,并返回受影响的行数
effect_row = cursor.execute("select * from student") print(effect_row)
运行结果:
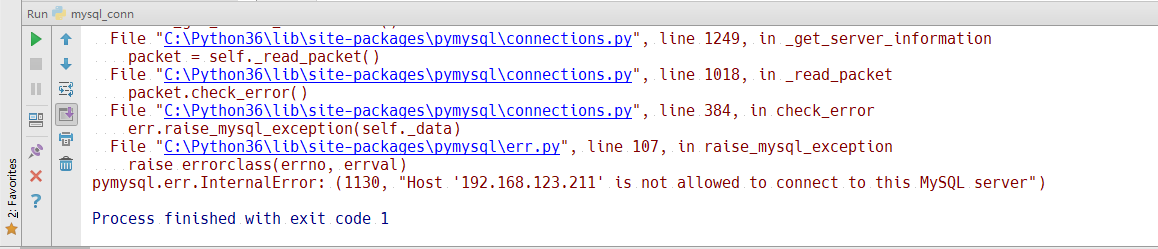
需要给权限
mysql> grant all on *.* to 'root'@'%' identified by 'root';
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
这个时候我们在运行上面的程序我们就可以看到,运行成功

这是说明查询到了5条数据,那如果我们需要查看这五条具体的数据是什么,我们要用:
print(cursor.fetchone())
cursor.fetchone()是一条一条的把数据取出来
 这里我们用了两条cursor.fetchone()
这里我们用了两条cursor.fetchone()
如果我们想要只取出前3条数据:
print('>>>>>',cursor.fetchmany(3))

一次性取出所有数据:
print('------',cursor.fetchall())

如果我们要插入多条数据:
import pymysql #创建连接
conn = pymysql.connect(host='192.168.123.207',port=3306,user='root',passwd='root',db="test"); #创建游标
cursor = conn.cursor()
data = [
("N1",23,"2015-01-01","M"),
("N2",24,"2015-01-02","F"),
("N3",25,"2015-01-03","M"),
]
#执行sql,并返回受影响的行数
effect_row = cursor.executemany("insert into student (name,age,register_date,gender)values(%s,%s,%s,%s)",data) conn.commit()

注:executemany默认会启动一个事务,如果没有conn.commit(),数据将不会被插入成功
sqlalchemy ORM
1.ORM介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说类似python这种面向对象的程序来说一切皆对象,我们实例化一个对象,通过点的形式来调用里面的函数。orm相当于把数据库给实例化了,数据库都是关系型的,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
优点:
1.隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句
2.ORM使我们构造固化数据结构变得简单易行
2.sqlalchemy安装
安装:
pip install sqlalchemy

3.sqlalchemy基本使用
首先我们看一下我们没有用orm之前我们创建一个数据表是这个样的:
create table student(
id int auto_increment,
name char(32) not null,
age int not null,
register_date date not null,
primary key(id)
);
使用了orm,实现上面的表的创建,代码如下:
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String engine = create_engine("mysql+pymysql://root:root@192.168.123.207/test",encoding='utf-8',echo=True)
Base = declarative_base()#生成orm基类 class User(Base):
__tablename__ = 'user'#表名
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64)) Base.metadata.create_all(engine)#创建表结构

用orm创建一条数据:
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String
from sqlalchemy.orm import sessionmaker engine = create_engine("mysql+pymysql://root:root@192.168.123.207/test",encoding='utf-8',echo=True)
Base = declarative_base()#生成orm基类 class User(Base):
__tablename__ = 'user'#表名
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64)) Base.metadata.create_all(engine)#创建表结构 Session_class = sessionmaker(bind=engine)#创建与数据库的会话session class ,注意这里返回给session的是一个类,不是实例
Session = Session_class()#生成session实例 user_obj = User(name = "xiaoming" , password = "")#生成你要创建的数据对象
user_obj2 = User(name = "jack" , password = "")#生成你要创建的数据对象
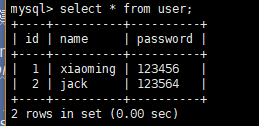
print(user_obj.name,user_obj.id)#此时还没有创建对象,打印一下会发现id还是None Session.add(user_obj)
Session.add(user_obj2) print(user_obj.name,user_obj.id)#此时也依然还没有创建 Session.commit()#现在才统一提交,创建数据
插入数据是使用sessionmaker,通过绑定上面创建的连接创建出一个类,生成session实例(相当于之前的cursor),用面向对象的方式创建两条记录,然后添加,最后commit就可以了

下面我们来看看数据库的增删改查:
查询:
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String
from sqlalchemy.orm import sessionmaker engine = create_engine("mysql+pymysql://root:root@192.168.123.207/test",encoding='utf-8')
Base = declarative_base()#生成orm基类 class User(Base):
__tablename__ = 'user'#表名
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64)) Base.metadata.create_all(engine)#创建表结构 Session_class = sessionmaker(bind=engine)#创建与数据库的会话session class ,注意这里返回给session的是一个类,不是实例
Session = Session_class()#生成session实例
data=Session.query(User).filter_by(name="xiaoming").all()
#print(data[0].name,data[0].password)
print(data)
如果只是Session.query(User).filter_by(name="xiaoming"),只会看到一条sql语句:
 filter_by()查出来的是一个列表,是一组数据
filter_by()查出来的是一个列表,是一组数据
加上.all()
 这个是一个对象,这也看不出来是那个,所以我们要手动去调出数据
这个是一个对象,这也看不出来是那个,所以我们要手动去调出数据
我们用print(data[0].name,data[0].password):
 这样就查出了数据
这样就查出了数据
现在是查一条数据,如果filter_by()里面什么都不写:
data=Session.query(User).filter_by().all()

我们就查出了好几条数据,我们要循环才能看出来具体的数据。我们想要直接看到谁是谁,我们怎么办呢?
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String
from sqlalchemy.orm import sessionmaker engine = create_engine("mysql+pymysql://root:root@192.168.123.207/test",encoding='utf-8')
Base = declarative_base()#生成orm基类 class User(Base):
__tablename__ = 'user'#表名
id = Column(Integer,primary_key=True)
name = Column(String(32))
password = Column(String(64)) def __repr__(self):
return "<%s name:%s>" % (self.id,self.name)
Base.metadata.create_all(engine)#创建表结构 Session_class = sessionmaker(bind=engine)#创建与数据库的会话session class ,注意这里返回给session的是一个类,不是实例
Session = Session_class()#生成session实例 data=Session.query(User).filter_by().all() print(data)
我们添加了__repr__()函数,这样看看运行结果:

这样就显现出我们查询的结果了。就相当于,如果你要查看什么数据,以什么格式的方式显示,就可以在__repr__这个函数中设置
在这里,我们用filter_by().all()查询出所有的数据,那我们用filter_by().first(),就可以查询出数据库中的第一条数据
上面我们用filter_by(name="xiaoming")查询出了姓名为xiaoming的数据,那我们想要查询用户id>1的数据应该怎么查询呢?
data=Session.query(User).filter(User.id>1).all()
多个条件查询:再加几个filter
data=Session.query(User).filter(User.id>1).filter(User.id<3).all()
修改:
data=Session.query(User).filter(User.id>1).first()
print(data)
data.name = "Jack Chen"
data.password = ""
Session.commit()
查询到你要修改的这个数据,然后想修改面向对象里的数据一样,对数据进行修改,最后commit()就可以了

删除:
data = Session.query(User).filter_by(name = 'Rain').first()
Session.delete(data)
Session.commit()
同样的,先查询到要删除的数据,然后对数据进行删除,最后提交commit
回滚:
fake_user = User(name = 'Rain',password = "")
Session.add(fake_user)
print(Session.query(User).filter(User.name.in_(['jack','rain'])).all())#这时候看看session里有了刚刚添加的数据 Session.rollback()#此时你rollback一下 print(Session.query(User).filter(User.name.in_(['jack','rain'])).all())#再查就发现刚刚添加的数据就没有了
运行结果看看:

这个时候可以看到一开始我们是能够看到刚刚插入的数据,但是回滚之后我们就看不到了,我们到数据库中看看:

我们插入一条数据看看
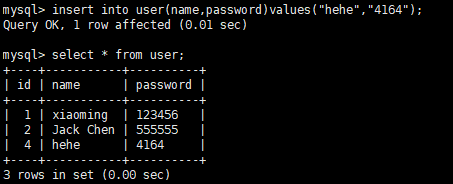
可以看出我们插入的数据的id是4,这样看来确实是先插入进去,然后回滚之后删除的
分组 统计:
统计:
Session.query(User).filter(User.name.in_(['xiaoming','rain'])).count()
分组:
from sqlalchemy import func
print(Session.query(func.count(User.name),User.name).group_by(User.name).all())

join多表查询:
Session.query(User,Student).filter(User.id == Student.id).all() Session.query(User).join(Student).all()#这种写法必须要求两个表有外键关联

外键关联
我们先创建两个表student,study_record:
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,DATE,ForeignKey
from sqlalchemy.orm import sessionmaker engine = create_engine("mysql+pymysql://root:root@192.168.123.207/xumingdb",encoding='utf-8')
Base = declarative_base()#生成orm基类 class Student(Base):
__tablename__ = 'student'#表名
id = Column(Integer,primary_key=True)
name = Column(String(32),nullable=False)
register_date = Column(DATE,nullable=False) def __repr__(self):
return "<%s name:%s>" % (self.id,self.name) class StudyRecord(Base):
__tablename__ = 'study_record'#表名
id = Column(Integer,primary_key=True)
day = Column(Integer,nullable=False)
status = Column(String(32),nullable=False)
stu_id = Column(Integer,ForeignKey("student.id")) def __repr__(self):
return "<%s day:%s>" % (self.id,self.day)
Base.metadata.create_all(engine)#创建表结构
外键表的创建,要用到ForeignKey("student.id")里面就直接是表名.字段名
然后向两个表中插入数据:
Base.metadata.create_all(engine)#创建表结构
Session_class = sessionmaker(bind=engine)
session = Session_class() s1 = Student(name = "xiaoming",register_date="2015-06-07")
s2 = Student(name = "huahua",register_date="2015-06-08")
s3 = Student(name = "caicai",register_date="2015-06-09")
s4 = Student(name = "zhazha",register_date="2015-06-04") study_obj1 = StudyRecord(day = 1,status = "YES",stu_id=1)
study_obj2 = StudyRecord(day = 2,status = "NO",stu_id=1)
study_obj3 = StudyRecord(day = 3,status = "YES",stu_id=1)
study_obj4 = StudyRecord(day = 1,status = "YES",stu_id=2)
session.add_all([s1,s2,s3,s4])
session.add_all([study_obj1,study_obj2,study_obj3,study_obj4]) session.commit()
批量插入用add_all,里面用一个列表放入要插入的数据,注意的是,因为建立了外键,所以在添加数据的时候,study_record的数据一定要在student表数据插入之后才能够被插入,如果一起插入就会报错
现在我们要查询xiaoming一共上了几节课,那应该怎么做呢:
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,DATE,ForeignKey
from sqlalchemy.orm import sessionmaker,relationship engine = create_engine("mysql+pymysql://root:root@192.168.123.207/xumingdb",encoding='utf-8')
Base = declarative_base()#生成orm基类 class Student(Base):
__tablename__ = 'student'#表名
id = Column(Integer,primary_key=True)
name = Column(String(32),nullable=False)
register_date = Column(DATE,nullable=False) def __repr__(self):
return "<%s name:%s>" % (self.id,self.name) class StudyRecord(Base):
__tablename__ = 'study_record'#表名
id = Column(Integer,primary_key=True)
day = Column(Integer,nullable=False)
status = Column(String(32),nullable=False)
stu_id = Column(Integer,ForeignKey("student.id")) student = relationship("Student",backref="my_study_record") def __repr__(self):
return "<%s day:%s status:%s>" % (self.student.name,self.day,self.status) Base.metadata.create_all(engine)#创建表结构
Session_class = sessionmaker(bind=engine)
session = Session_class()
stu_obj = session.query(Student).filter(Student.name=='xiaoming').first()
print(stu_obj.my_study_record)
session.commit()
注意上面代码标红的这个语句,我们引入了relationship,然后这个允许你在study_record表里通过backref字段反向查出所有它在student表里的关联项,实现了一个双向查找,即关联student表,在studyrecord中通过student字段就可以查 student表中的所有字段,反过来,我们可以在student表中通过 my_study_record字段反查studyrecord里面的数据,然后代表着我们在下面查到的xiaoming,可以.my_study_record就可以查询出在studyrecord表中还有xiaoming的id的数据项
多外键关联
首先我们创建两个表customer和address两个表,其中customer表中有address的两个外键:
import sqlalchemy
from sqlalchemy import Integer, ForeignKey, String, Column
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:root@192.168.123.207/xumingdb",encoding='utf-8')
Base = declarative_base() class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String(64)) billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id")) billing_address = relationship("Address")
shipping_address = relationship("Address") class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
street = Column(String(64))
city = Column(String(64))
state = Column(String(64))
def __repr__(self):
return self.street
Base.metadata.create_all(engine) # 创建表结构
然后我们向两个表中插入数据:
from day12 import sqlalchemy_multi_fk from sqlalchemy.orm import sessionmaker Session_class = sessionmaker(bind=sqlalchemy_multi_fk.engine)
session = Session_class() addr1 = sqlalchemy_multi_fk.Address(street="XiZangBeiLu",city="ShangHai",state="ShangHai")
addr2 = sqlalchemy_multi_fk.Address(street="YuHu",city="XiangTan",state="HuNan")
addr3 = sqlalchemy_multi_fk.Address(street="ZhongXinZhen",city="SuQian",state="JiangSu")
session.add_all([addr1,addr2,addr3]) c1 = sqlalchemy_multi_fk.Customer(name="xiaoming",billing_address=addr1,shipping_address=addr2)
c2 = sqlalchemy_multi_fk.Customer(name="jack",billing_address=addr3,shipping_address=addr3)
session.add_all([c1,c2])
session.commit()
这样插入会出现一个错误:
sqlalchemy.exc.AmbiguousForeignKeysError: Could not determine join condition between parent/child tables on relationship Customer.billing_address - there are multiple foreign key paths linking the tables. Specify the 'foreign_keys' argument, providing a list of those columns which should be counted as containing a foreign key reference to the parent table.
说白了就是我们现在在做关联查询的时候,有两个字段同时关联到了Address表中 ,在做反向查询的时候它分不清楚谁是谁,通过address反向查的时候分不清哪个字段代表billing_address,哪个字段是代表了shipping_address.那我们怎么解决呢?
billing_address = relationship("Address",foreign_keys=[billing_address_id])
shipping_address = relationship("Address",foreign_keys=[shipping_address_id])
在创建反向查询的语句中添加foreign_keys参数就可以了
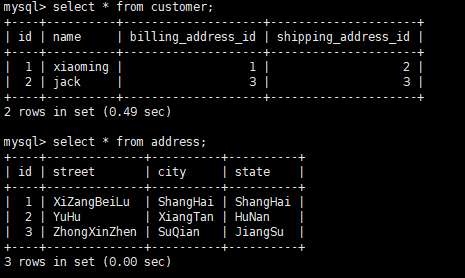
添加数据成功!!
这个时候我们要查询customer的地址:
obj = session.query(sqlalchemy_multi_fk.Customer).filter(sqlalchemy_multi_fk.Customer.name=="xiaoming").first()
print(obj.name,obj.billing_address,obj.shipping_address)

多对多关系
现在让我们设计一个能描述“图书”与“作者”的关系的表结构,需求是:
1.一本书可以有好几个作者一起出版
2.一个作者可以写好几本书
首先我们看一下一般的思路 :

两个表,然后我们在遇到一本书有多个作者共同参与出版,就把作者id写在一起,但是这样不利于查询
那我们可以再添加一张表:
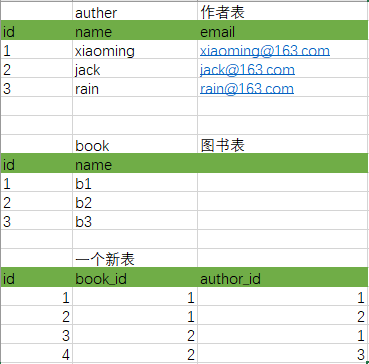
这就实现了双向的一对多,一个作者可以包含多本书,一本书可以包含多个作者。这就形成了多对多。
来看代码的实现:
首先还是先建立数据表:
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:root@192.168.123.207/xumingdb",encoding='utf-8')
Base = declarative_base() Base = declarative_base() book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
) class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books') def __repr__(self):
return self.name class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32)) def __repr__(self):
return self.name
Base.metadata.create_all(engine) # 创建表结构
这里我们使用了另外一种建立表的方式,建立了第三张表book_m2m_auther,这张表建立起来后基本上不需要我们去人为的添加数据,对用户来讲是不用关心这里面有什么数据,是由orm自动帮你维护的。也就不需要给它建立映射关系了。
但是在mysql端其实已经关联上了,因为外键已经建立好了,在orm查询的时候,还要做一个orm级别的 内存对象的映射:relationship,告诉book表和author表在查询数据的时候去哪张表里查询。
所以看上面的红色的代码,通过secondary这个字段去查第三张表。
这个时候就建立好了多对多的关系。我们就可以插入数据看效果:(先把表建立起来再说)
from day12 import sqlalchemy_multitomulti
from sqlalchemy.orm import sessionmaker Session_class=sessionmaker(bind=sqlalchemy_multitomulti.engine)
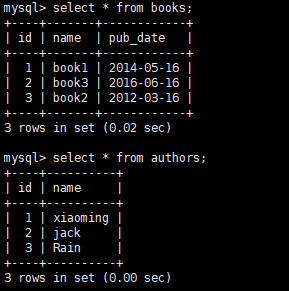
session = Session_class() b1 = sqlalchemy_multitomulti.Book(name="book1",pub_date="2014-05-16")
b2 = sqlalchemy_multitomulti.Book(name="book2",pub_date="2012-03-16")
b3 = sqlalchemy_multitomulti.Book(name="book3",pub_date="2016-06-16") a1 = sqlalchemy_multitomulti.Author(name="xiaoming")
a2 = sqlalchemy_multitomulti.Author(name="jack")
a3 = sqlalchemy_multitomulti.Author(name="Rain") b1.authors = [a1,a3]
b2.authors = [a2,a3]
b3.authors = [a1,a2,a3] session.add_all([b1,b2,b3,a1,a2,a3])
session.commit()
上面红色标记是建立关联关系,这样建立出来之后,book_m2m_author表自动就会有数据。

当然如果我们想要插入中文的书。即插入的数据有中文,我们要怎么做呢:
engine = create_engine("mysql+pymysql://root:root@192.168.123.207/xumingdb?charset=utf8",encoding='utf-8')
Base = declarative_base()
需要在创建数据库连接的时候在数据库后面加上?charset=utf8
现在数据插入之后,最终要实现查询数据:
1.查看作者xiaoming出版了多少本书:
author_obj = session.query(sqlalchemy_multitomulti.Author).filter(sqlalchemy_multitomulti.Author.name=="xiaoming").first()
print(author_obj.books)

2.查看书b2是哪些作者出版的 :
book_obj = session.query(sqlalchemy_multitomulti.Book).filter(sqlalchemy_multitomulti.Book.id==2).first()
print(book_obj.authors)

多对多删除:
在删除数据的时候我们也同样的不需要管book_m2m_author表,sqlalchemy会自动帮我们把对应的数据删除:
通过书删除作者:
author_obj = session.query(sqlalchemy_multitomulti.Author).filter(sqlalchemy_multitomulti.Author.name=="xiaoming").first()
book_obj = session.query(sqlalchemy_multitomulti.Book).filter(sqlalchemy_multitomulti.Book.id==2).first()
book_obj.authors.remove(author_obj)
session.commit()

这个时候图书2的关联关系会自动少一个
直接删除作者:
author_obj = session.query(sqlalchemy_multitomulti.Author).filter(sqlalchemy_multitomulti.Author.name=="xiaoming").first()
session.delete(author_obj)
session.commit()
python----python使用mysql的更多相关文章
- Python中操作mysql的pymysql模块详解
Python中操作mysql的pymysql模块详解 前言 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持 ...
- python——django使用mysql数据库(二)
上一篇中,我们已经讲述了如何初始化一个django数据库,这一章就来讲讲在实际的项目中如何使用我们初始化的数据库呢? 如还未进行初始化数据库操作,请参考python——django使用mysql数据库 ...
- python——django使用mysql数据库(一)
之前已经写过如何创建一个django项目,现在我们已经有了一个小骷髅,要想这个web工程变成一个有血有肉的人,我们还需要做很多操作.现在就先来介绍如何在django中使用mysql数据库. 前提:已经 ...
- Python 3 and MySQL
http://stackoverflow.com/questions/4960048/python-3-and-mysql up vote61down votefavorite 20 I am usi ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- 使用Python编程语言连接MySQL数据库代码
使用Python编程语言连接MySQL数据库代码,跟大家分享一下: 前几天我用python操作了mysql的数据库,发现非常的有趣,而且python操作mysql的方法非常的简单和快速,所以我把代码分 ...
- python针对于mysql的增删改查
无论是BS还是CS得项目,没有数据库是不行的. 本文是对python对mysql的操作的总结.适合有一定基础的开发者,最好是按部就班学习的人阅读.因为我认为人生不能永远都是从零开始,那简直就是灾难. ...
- Python 連接 MySQL
Python 連接 MySQL MySQL 是十分流行的開源資料庫系統,很多網站也是使用 MySQL 作為後台資料儲存,而 Python 要連接 MySQL 可以使用 MySQL 模組.MySQLdb ...
- Python中使用Mysql(安装篇)
准备工作 import MySQLdb Linux系统自带了Python,但并不是都有这个包,至少我每次拿到一台全新的服务器时候,都发现没有装这个包. 这个东西的下载地址是 http://source ...
- 第一篇:Win10系统搭建Python+Django+Nginx+MySQL 开发环境详解(完美版)
Win10+Python+Django+Nginx+MySQL 开发环境搭建详解 PaulTsao 说明:本文由作者原创,仅供内部参考学习与交流,转载引用请注明出处,用于商业目的请联系作者本人. Wi ...
随机推荐
- 团队作业:第五周 Alpha版本测试与发布
团队:你吼辣么大声干什么嘛 Alpha版本测试报告: bug: 修复的bug: 不能重现的bug: 无 产品设计,非bug: 在双人对战模式中,撞到墙壁会从对面的墙壁穿出,不会死 没能 ...
- react 项目及视频
项目 视频
- JavaScript遍历树结构
遍历 function parseTreeJson(treeNodes){ if(!treeNodes||!treeNodes.length)return; for(let i=0;i<tree ...
- DRF 的 版本,解析器,与序列化
DRF 的 版本,解析器,与序列化 补充 配置文件中的 类的调用: (字符串) v1 = ["view.xx.apth.Role","view.xx.apth.Role& ...
- Tomcat应用服务器被黑客 肉鸡攻击 记录
线上一台应用服务器报警,负载过高,这个就诡异了,因为只是一个普通的服务器,应用使用人员不到10个人,咋会负载高,肯定有问题哪,登陆上去查看, top查看哪个占据的cpu资源比较多 [root@aew0 ...
- Manual Install Cocos2d-x vc template on Windows 7
Manual Installation Process Download the template file from HERE and extract it. Open the file CCApp ...
- 题目一:给出一个n,代表有从1到n的数字[1,2,3,··· n],问可以构成多少种二叉搜索树?
题目一:给出一个n,代表有从1到n的数字[1,2,3,··· n],问可以构成多少种二叉搜索树? 一开始的想法是直接递归构造,时间复杂度是指数上升:后来想法是找规律:先看例子: n = 1, 有一个元 ...
- 设置一个严格的SESSION过期时间
认识一:当我们需要更改session生存时间的时候通行的做法是更改php.ini文件中 1: ; Name of the session (used as cookie name). 2: sessi ...
- sublime 非常好用的注释工具
Sublime在进行前端开发时非常棒,当然也少不了众多的插件支持,DocBlocker是在Sublime平台上开发一款自动补全代码插件,支持JavaScript (including ES6), PH ...
- 【解题报告】[动态规划]-PID69 / 过河卒
原题地址:http://www.rqnoj.cn/problem/69 解题思路: 用DP[i][j]表示到达(i,j)点的路径数,则 DP[0][0]=1 DP[i][j]=DP[i-1][j]+D ...