SIMD数据并行(二)——多媒体SIMD扩展指令集
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multiple Data,单指令流多数据流)。其中MIMD的表现形式主要有多发射、多线程、多核心,在当代设计的以处理能力为目标驱动的处理器中,均能看到它们的身影。同时,随着多媒体、大数据、人工智能等应用的兴起,为处理器赋予SIMD处理能力变得愈发重要,因为这些应用存在大量细粒度、同质、独立的数据操作,而SIMD天生就适合处理这些操作。
SIMD结构有三种变体:向量体系结构、多媒体SIMD指令集扩展和图形处理单元。本文集中围绕多媒体SIMD指令集扩展进行描述。
多媒体SIMD指令集扩展
1. 简介
上世纪90年代,随着互联网的普及,音频、图片、视频等多媒体应用迅速崛起,为应对多媒体密集的计算需求,Intel于1996年率先将多媒体SIMD扩展指令集引入通用处理器,在其奔腾处理器上集成了 SIMD 扩展部件 MMX。
多媒体应用中通常存在大量同质、独立的访存和计算操作,且使用的数据类型一般都很窄(如图形系统使用8位表示三基色的每一种颜色,使用8位表示透明度;音频采样位宽通常为8位或16位)。SIMD扩展指令集具有独立的长位宽向量寄存器(64/128/256/512/1024......),允许将原来需要多次装载的连续内存地址数据一次性装载到向量寄存器中,并使用分裂模式将长的向量寄存器当作多个独立的窄位宽元素,通过一条SIMD扩展指令实现对SIMD向量寄存器中所有数据元素的并行处理。这种执行方式非常适合于处理计算密集、数据相关性少的音视频解码等多媒体程序。
SIMD扩展部件仅需要在原来标量部件的基础上复制几份同样的处理单元,不需要增加太多的额外硬件,就能对多媒体等特定应用带来显著的性能提升,且不增加通信以及cache和内存的开销,因此即使在多核时代,SIMD扩展部件仍然是程序加速的重要手段之一。
2. 实现形式
寄存器分裂:将长向量寄存器的比特位均匀“分裂”成多个窄位宽(8/16/32/64)元素,当作独立数据进行操作。一般的多媒体SIMD扩展指令集均支持定点的有符号和无符号数据操作,部分处理器支持单、双精度的浮点操作。
下图举了一个128位宽寄存器的例子:
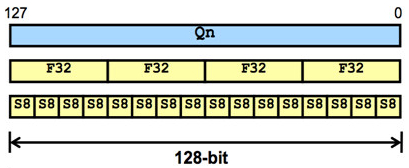
图1 将128位宽的寄存器分裂成4个32位单精度浮点寄存器或16个8位宽有符号定点寄存器
并行车道:SIMD扩展部件负责访存、计算等操作的功能单元均支持多个并行子单元的同时处理,因此一条SIMD扩展指令可一次性操作多个元素。
下图显示了一个功能单元以四车道并行执行的例子:
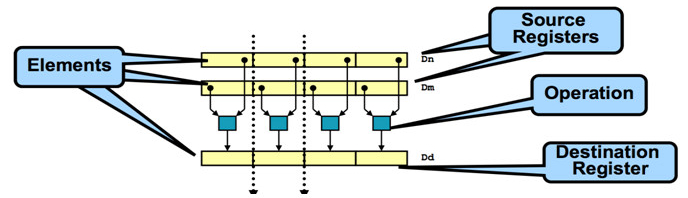
图2 SIMD多媒体扩展指令执行示意图
3. 主要特征
SIMD扩展指令在实现机制上与普通的标量指令没有太多差别。在SIMD扩展指令集上均可以实现标量指令集支持的各种操作,如存取操作、算数运算、逻辑运算、比特操作,以及常用的饱和处理、四舍五入、条件执行等功能。
SIMD扩展指令特殊之处在于并行元素的处理。除部分计算子单元支持条件执行外,各子单元的访存和计算操作都将严格同步执行,一方面迫使使用它的程序需要具备可并行化的特征,另一方面带来访存上的一些问题。
当需要并行处理的元素个数小于一条SIMD扩展指令所能支持的并行操作个数,或是面临非连续访存的并行处理需求时,强行使用SIMD扩展指令可能会带来内存越界的问题。早期的SIMD向量存取指令只能访问在内存中连续对齐的数据,因此当程序中存在不对齐或不连续内存引用时,需要通过移位或者重组等辅助指令才能组成向量。在向量重组指令能力较弱或者根本不支持向量重组指令时,强制将不连续的访存数据组成向量可能带来大的开销,甚至导致向量化没有收益。
但随着处理器技术的发展,目前已有处理器已经能支持非对齐的访存操作,并添加了大量用于数据重组的指令,部分处理器还支持集散(gather-scatter)内存访问,这给SIMD向量化发掘提供了坚实的基础。
SIMD扩展指令集支持的计算功能也在不断丰富,如今很多处理器支持的SIMD扩展指令达上百条之多。很多指令的设计初衷早已跨越多媒体应用处理范畴,延伸到信号处理、科学计算等需要高性能计算能力的领域。
在各处理器上的应用情况
Intel对多媒体SIMD扩展指令集的应用很具代表性。1996 年,Intel 在其奔腾处理器上集成了 SIMD 扩展部件 MMX,其向量寄存器为64位宽。后来又相继推出了 SSE(128位宽),AVX(256位宽),IMCI 和 AVX-512(512位宽)。

图3 Intel x86处理器的多媒体SIMD扩展指令集演进历程
其他 SIMD 扩展部件还包括摩托罗拉 PowerPC 处理器的 AltiVec、Sun 公司 SPARC 处理器中的 VIS、HP 公司 PA-RISC 处理器中的 MAX、DEC 公司 Alpha 处理器中的 MVI-2、MIPS公司 V 处理器中的 MDMX、AMD处理器中的3DNow!、ARM内核中的NEON、CEVA公司的VCU 等。
SIMD 扩展部件最初仅用于多媒体领域和数字信号处理器中,后来,研究人员将SIMD 扩展部件应用到高性能计算机中,如,IBM 的超级计算机 BlueGene/L 和国产的神威蓝光超级计算机中都集成短向量扩展部件。国产处理器中,龙芯、迈创以及魂芯一号都含有 SIMD 扩展部件。
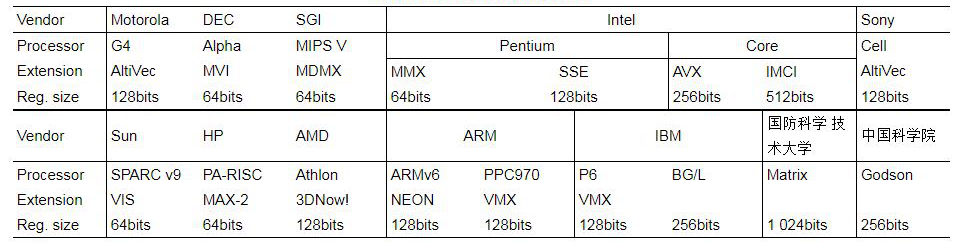
图4 带有SIMD扩展部件的处理器
很多通用指令集也支持SIMD形式的访存和计算操作,但它们支持的寄存器位宽有限,通过将通用寄存器(32/16位宽)分裂成16/8位的更小单元进行独立的并行操作,如ARM指令集、TIC64X指令集,等。这种SIMD指令在实现机制上和多媒体SIMD扩展指令并无多少区别,不过考虑到多媒体SIMD扩展指令集针对特殊应用场景而“扩展”的用意,还是暂不把他们归为多媒体SIMD扩展指令。
如何发挥SIMD扩展指令集的效能
多媒体SIMD扩展指令集必须要有软件的支持。与标量部件相比,SIMD扩展部件的收益来自于向量运算和向量访存。因此将程序尽可能向量化成SIMD指令可执行的形式,是提高SIMD整体效益的关键。
对于软件开发者而言,有大概5种方式来利用多媒体SIMD扩展指令集的并行加速功能:
使用汇编语言编写代码。包括在汇编源文件中书写汇编指令,或是在高级语言中嵌入扩展汇编;
使用内嵌指令函数。一般SIMD扩展指令集设计商都会提供各汇编指令的封装函数,编程者只需调用这些函数就能实现汇编指令的插入,将复杂的寄存器分配的任务交给编译器来完成;
使用C++类库扩展。这种高级语言提供的类库将偏处理器底层的信息封装起来,留给编程者更接近行为体验的语法和函数接口;
使用库函数。SIMD扩展指令集设计商往往会公开一些典型应用的库函数,这些库函数一般充分挖掘了指令集的特性,效率很高;
使用编译制导语句辅助编译器优化。现今的主流编译器集成有自动向量化算法,能够在编译期间分析代码的可并行性,并生成SIMD扩展汇编指令。不过由于编译器能够从代码中提取的信息有限,对一些复杂的处理过程,即使存在并行开发的可能,编译器也可能无法成功向量化。编译制导语句可以从开发者的角度提供给编译器更多编译期间无法提取的信息,提高编译器将代码向量化的概率。如OpenMP和OpenACC就支持通过添加编译指示的方式发掘程序的SIMD并行性.
另外,由于很多SIMD扩展指令一般都是在一个周期内发出,但是执行结果可能若干个周期才能有效。在做循环的优化中,如果能结合循环展开方式开发软件流水线代码,可以减少由于前后指令相关造成的延迟等待时间,尽可能地挖掘处理器的峰值效率。
处理非整数倍并行长度的应用
在开发中,很容易碰到这样的情况:要对一段具有N并行度的代码进行向量化,已知SIMD扩展指令一次可处理8个这样的元素,但N在编译时未知。这时,应该如何通过手动向量化的方法来编写代码呢?
一种方法就是人为将N扩展为8的整数倍,如N = (N+7)/8,然后进行向量化。这样编写起来很方便,带来的问题就是需要预留足够的内存空间,否则容易引起内存越界。
这里主要介绍一种不需要人为扩展内存边界的方法。假设我们要处理的代码是:
for(i=0; i<N; i++)
{
a[i] = b[i] + c[i];
}
可以这样编写SIMD扩展指令向量化的代码:
v_len = N/8;
for(i=0; i<v_len; i++)
{
v_b = vload(&b[8*i]);
v_c = vload(&c[8*i]);
v_a = vadd(v_b, v_c);
vstore(&a[8*i]);
}
/***收尾处理***/
v_b = vload(&b[N-8]);
v_c = vload(&c[N-8]);
v_a = vadd(v_b, v_c);
vstore(&a[N-8]);
这种方式通过将尾部不足向量长度的元素与前几个元素拼凑成一组整的向量,实现收尾处理,将不会带来内存越界的问题。不过这种方式也有不足之处,就是代码体积将增大一倍左右,且不能处理N小于向量长度的情况。
参考资料
【1】高伟, 赵荣彩, 韩林, 庞建民, 丁锐. SIMD自动向量化编译优化概述[J].软件学报,2015, 26(6): 1265-1284.
【2】John L. Hennessy,David A. Patterson . 计算机体系结构:量化研究方法:第5版[M].北京:人民邮电出版社,2013. (原名《Computer Architecture:A Quantitative Approach》)
【3】David A. Patterson,John L. Hennessy . 计算机组成与设计:硬件/软件接口:第5版[M].北京:机械工业出版社,2015. (原名《Computer Organization and Design:The Hardware/Software Interface》)
·END·
你可能还感兴趣:
欢迎来我的微信公众号做客:信号君
专注于信号处理知识、高性能计算、现代处理器&计算机体系
技术成长 | 读书笔记 | 认知升级

幸会~
![]()
SIMD数据并行(二)——多媒体SIMD扩展指令集的更多相关文章
- SIMD数据并行(四)——三种结构的比较
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
- SIMD数据并行(三)——图形处理单元(GPU)
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
- SIMD数据并行(一)——向量体系结构
在计算机体系中,数据并行有两种实现路径:MIMD(Multiple Instruction Multiple Data,多指令流多数据流)和SIMD(Single Instruction Multip ...
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
- X86架构CPU常识(主频,外频,FSB,cpu位和字长,倍频系数,缓存,CPU扩展指令集,CPU内核和I/O工作电压,制造工艺,指令集,超流水线与超标量)
1.主频 主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度. CPU的主频=外频×倍频系数.很多人认为主频就决定着CPU的运行速度,这不仅是个片面的,而且对于服务器来讲,这个认识也出现了偏差. ...
- C#并行编程-PLINQ:声明式数据并行
目录 C#并行编程-相关概念 C#并行编程-Parallel C#并行编程-Task C#并行编程-并发集合 C#并行编程-线程同步原语 C#并行编程-PLINQ:声明式数据并行 背景 通过LINQ可 ...
- C#并行编程--命令式数据并行(Parallel.Invoke)---与匿名函数一起理解(转载整理)
命令式数据并行 Visual C# 2010和.NETFramework4.0提供了很多令人激动的新特性,这些特性是为应对多核处理器和多处理器的复杂性设计的.然而,因为他们包括了完整的新的特性,开 ...
- 深度神经网络DNN的多GPU数据并行框架 及其在语音识别的应用
深度神经网络(Deep Neural Networks, 简称DNN)是近年来机器学习领域中的研究热点,产生了广泛的应用.DNN具有深层结构.数千万参数需要学习,导致训练非常耗时.GPU有强大的计算能 ...
- 【深度学习系列2】Mariana DNN多GPU数据并行框架
[深度学习系列2]Mariana DNN多GPU数据并行框架 本文是腾讯深度学习系列文章的第二篇,聚焦于腾讯深度学习平台Mariana中深度神经网络DNN的多GPU数据并行框架. 深度神经网络( ...
随机推荐
- May 14th 2017 Week 20th Sunday
A smooth sea never made a skillful mariner. 平静的海洋练不出熟练的水手. A smooth sea never made a skillful marine ...
- March 27 2017 Week 13 Monday
A book that remains shut is but a block. 有书闭卷不阅读,无异于一块木头. I had planned to buy a book and read it ev ...
- Python3基本数据类型(三、列表)
序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字-它的位置,或索引,第一个索引是0,第二个索引是1,以此类推.Python有6个序列的内置类型,但最常见的是列表和元组.序列都可以进 ...
- 我的HTML总结之常用基础便签
HTML:是Hyper Text Markup Language(超级文本标记语言)的缩写,HTML不是一种程序,只是一种控制网页中数据显示的标识语言. HTML由一组标签组成. HTML的基本结构 ...
- python入门16 递归函数 高阶函数
递归函数:函数内部调用自身.(要注意跳出条件,否则会死循环) 高阶函数:函数的参数包含函数 递归函数 #coding:utf-8 #/usr/bin/python """ ...
- ftp免交互上传文件脚本
ftp -i -n <<! open .x.x.x user yourFtpAccount yourPasswd cd /root/DailyBuild/webapps/ delete x ...
- ubuntu桌面
gnome-desktop-item-edit ~/Desktop/ --create-new
- A potentially dangerous Request.Form value was detected from the client的解决办法
网上找了这么多,这条最靠谱,记录下来,以备后用 <httpRuntime requestValidationMode="2.0"/> <pages validat ...
- CF498D Traffic Jams in the Land
嘟嘟嘟 题面:有n条公路一次连接着n + 1个城市,每一条公路有一个堵塞时刻a[i],如果当前时间能被a[i]整除,那么通过这条公路需要2分钟:否则需要1分钟. 现给出n条公路的a[i],以及m次操作 ...
- html上传图片(进度条变化)、音乐
<html> <head> <title>$Title$</title> </head> <link href="css/b ...