mysql_study_2
select
代码:
CREATE DATABASE mysql_shiyan; use mysql_shiyan; CREATE TABLE department
(
dpt_name CHAR(20) NOT NULL,
people_num INT(10) DEFAULT '',
CONSTRAINT dpt_pk PRIMARY KEY (dpt_name)
); CREATE TABLE employee
(
id INT(10) PRIMARY KEY,
name CHAR(20),
age INT(10),
salary INT(10) NOT NULL,
phone INT(12) NOT NULL,
in_dpt CHAR(20) NOT NULL,
UNIQUE (phone),
CONSTRAINT emp_fk FOREIGN KEY (in_dpt) REFERENCES department(dpt_name)
); CREATE TABLE project
(
proj_num INT(10) NOT NULL,
proj_name CHAR(20) NOT NULL,
start_date DATE NOT NULL,
end_date DATE DEFAULT '2015-04-01',
of_dpt CHAR(20) REFERENCES department(dpt_name),
CONSTRAINT proj_pk PRIMARY KEY (proj_num,proj_name)
);
插入的数据
#INSERT INTO department(dpt_name,people_num) VALUES('\u90e8\u95e8',\u4eba\u6570);
INSERT INTO department(dpt_name,people_num) VALUES('dpt1',11);
INSERT INTO department(dpt_name,people_num) VALUES('dpt2',12);
INSERT INTO department(dpt_name,people_num) VALUES('dpt3',10);
INSERT INTO department(dpt_name,people_num) VALUES('dpt4',15);
#INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(\u7f16\u53f7,'\u540d\u5b57',\u5e74\u9f84,\u5de5\u8d44,\u7535\u8bdd,'\u90e8\u95e8');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(01,'Tom',26,2500,119119,'dpt4');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(02,'Jack',24,2500,120120,'dpt2');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(03,'Rose',22,2800,114114,'dpt3');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(04,'Jim',35,3000,100861,'dpt1');
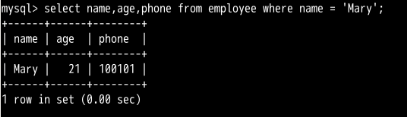
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(05,'Mary',21,3000,100101,'dpt2');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(06,'Alex',26,3000,123456,'dpt1');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(07,'Ken',27,3500,654321,'dpt1');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(08,'Rick',24,3500,987654,'dpt3');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(09,'Joe',31,3600,110129,'dpt2');
INSERT INTO employee(id,name,age,salary,phone,in_dpt) VALUES(10,'Mike',23,3400,110110,'dpt4');
INSERT INTO employee(id,name,salary,phone,in_dpt) VALUES(11,'Jobs',3600,019283,'dpt2');
INSERT INTO employee(id,name,salary,phone,in_dpt) VALUES(12,'Tony',3400,102938,'dpt3');
#INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(\u7f16\u53f7,'\u5de5\u7a0b\u540d','\u5f00\u59cb\u65f6\u95f4','\u7ed3\u675f\u65f6\u95f4','\u90e8\u95e8\u540d');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(01,'proj_a','2015-01-15','2015-01-31','dpt2');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(02,'proj_b','2015-01-15','2015-02-15','dpt1');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(03,'proj_c','2015-02-01','2015-03-01','dpt4');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(04,'proj_d','2015-02-15','2015-04-01','dpt3');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(05,'proj_e','2015-02-25','2015-03-01','dpt4');
INSERT INTO project(proj_num,proj_name,start_date,end_date,of_dpt) VALUES(06,'proj_f','2015-02-26','2015-03-01','dpt2');
SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;
简单限制条件
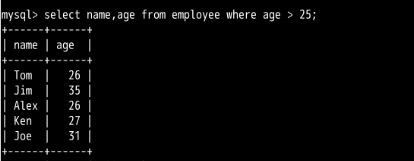
1........and || or || between and .....and
2........ in || not in
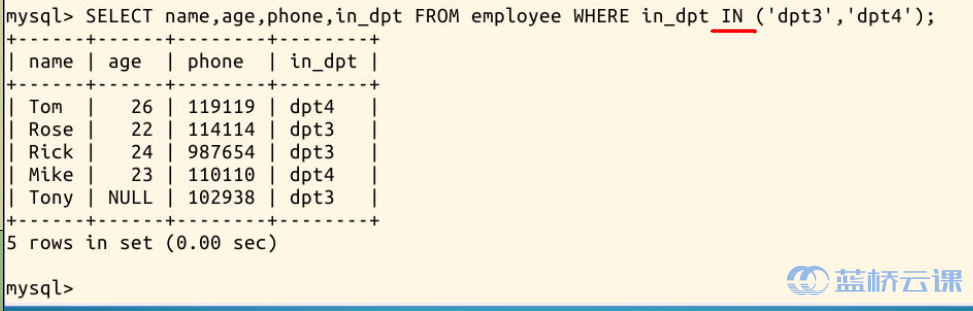
关键词 IN 和 NOT IN 的作用和它们的名字一样明显,用于筛选“在”或“不在”某个范围内的结果,比如说我们要查询在 dpt3 或 dpt4 的人:
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt IN ('dpt3','dpt4');
而 NOT IN 的效果则是,如下面这条命令,查询出了不在 dpt1 也不在 dpt3 的人:
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt NOT IN ('dpt1','dpt3');

通配符
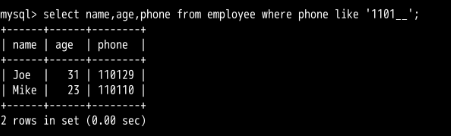
关键字 LIKE 可用于实现模糊查询,常见于搜索功能中。
和 LIKE 联用的通常还有通配符,代表未知字符。 SQL中的通配符是 _ 和 % 。其中 _ 代表一个未指定字符,% 代表不定个未指定字符

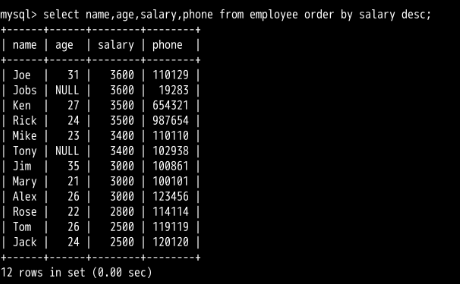
排序:
order by XXX desc 降序|| asc 升序 不过 也可以不加表示 升序
内置函数和计算

其中 COUNT 函数可用于任何数据类型(因为它只是计数),而 SUM 、AVG 函数都只能对数字类数据类型做计算,MAX 和 MIN 可用于数值、字符串或是日期时间数据类型。
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee;
有一个细节你或许注意到了,使用 AS 关键词可以给值重命名,比如最大值被命名为了 max_salary:

子查询
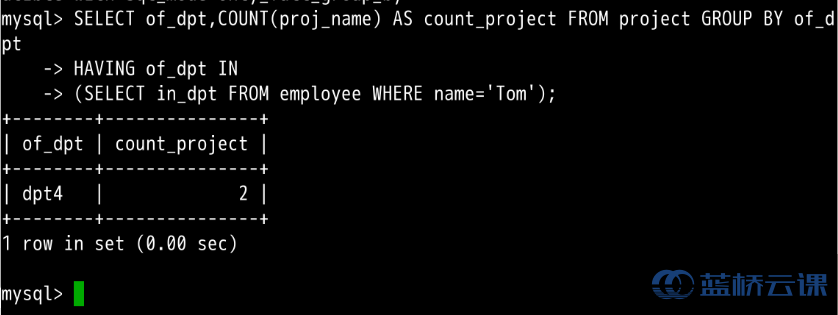
想要知道名为 "Tom" 的员工所在部门做了几个工程。员工信息储存在 employee 表中,但工程信息储存在 project 表中。
对于这样的情况,我们可以用子查询:
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project GROUP BY of_dpt
HAVING of_dpt IN
(SELECT in_dpt FROM employee WHERE name='Tom');
上面代码包含两个 SELECT 语句,第二个 SELECT 语句将返回一个集合的数据形式,然后被第一个 SELECT 语句用 in 进行判断。
HAVING 关键字可以的作用和 WHERE 是一样的,都是说明接下来要进行条件筛选操作。
区别在于 HAVING 用于对分组后的数据进行筛选
group by .....having......
连接查询
SELECT id,name,people_num
FROM employee,department
WHERE employee.in_dpt = department.dpt_name
ORDER BY id;
等同于
SELECT id,name,people_num
FROM employee JOIN department
ON employee.in_dpt = department.dpt_name
ORDER BY id;
mysql_study_2的更多相关文章
随机推荐
- Oracle 去特殊字符
Create Or Replace Function Zl_Fun_去特殊字符(内容_In In Varchar2) Return Varchar2 IsBegin Return Replace(Re ...
- [转] Ramda 函数库参考教程
学习函数式编程的过程中,我接触到了 Ramda.js. 我发现,这是一个很重要的库,提供了许多有用的方法,每个 JavaScript 程序员都应该掌握这个工具. 你可能会问,Underscore 和 ...
- CSS(Cascading Style Sheet)简述
CSS(Cascading Style Sheet)简述 什么是CSS? css是指层叠样式表 css定义了如何显示HTML元素 css的诞生是为了解决内容与表现分离的问题,可以极大地提高工作效率 样 ...
- VIM懒人配置
VIM懒人配置 VIM配置起来,是很折腾人的.所以为了方便,直接使用前人的配置.重在用不在折腾. 1 VIM安装 一行命令. # sudo apt-get install vim 2 配置 vim的个 ...
- SharePoint修改左上角文字的命令行
$webapp = Get-SPWebApplication “http://test-spweb1” --需要修改的站点$webapp.SuiteNavBrandingText = “XXXXXX” ...
- hdu6489 2018 黑龙江省大学生程序设计竞赛j题
Problem Description Kayaking is playing a puzzle game containing n different blocks. He marks the bl ...
- Pytorch
torch.nn.utils.rnn: pack_padded_sequence() pad_packed_sequence() Notice: The padded embedding metrix ...
- DWM1000 帧过滤代码实现
帧过滤功能可以在同一个环境内组建多个网络而不干扰(非频段不同),可以通过PANID(网络ID)区分不同网络,不同网络中的模块无法直接通信, 再之,利用短地址,网络中可以同时有多个模块发送信息,而接收端 ...
- ARTS Challenge- Week 1 (2019.03.25~2019.03.31)
1.Algorithm - at least one leetcode problem per week(Medium+) 986. Interval List Intersections https ...
- pip离线安装依赖包
pip安装离线本地包 导出本地已有的依赖包 pip freeze > requirements.txt 将依赖包下载到本地 # 下载到当前目录,指定pip源 pip download -r re ...