论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题。所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示)。这里的难点是,由于不同场景下的角度、背景亮度等等因素的差异,同一个人的图像变化非常大,因而不能使用一般的图像分类的方法。论文采用了一种相似性度量的方法来促使神经网络学习出图像的特征,并根据特征向量的欧式距离来确定相似性。除此之外,论文通过对网络的训练过程进行分析,提出了一种计算效率更高的模型训练方法。

论文方法
相似性模型
论文采用的度量相似性的方法基于一个简单的想法:相同类型图片(同一个人)的特征之间的距离要小于不同类型的特征。假设我们有一些训练样本,现在把它们组织成三元组的形式 \({O_i}=<O_i^1,O_i^2,O_i^3>\),其中 \(O_i^1\) 和 \(O_i^2\) 表示属于同一类(匹配)的样本,\(O_i^1\) 和 \(O_i^3\) 表示不匹配的样本。设网络的参数为 \(W=\{W_j\}\),\(F_W(I)\) 表示图像 \(I\) 的特征向量,则我们的目标是使下面的不等式成立:
\[
\begin{align}
||F_W(O_i^1)-F_W(O_i^2)||^2<||F_W(O_i^1)-F_W(O_i^3)||^2 \tag{2}
\end{align}
\]
基于此,论文给出如下目标函数:
\[
\begin{align}
f(W,O)=\sum_{i=1}^n{\max{\{||F_W(O_i^1)-F_W(O_i^2)||^2-||F_W(O_i^1)-F_W(O_i^3)||^2, C \}}} \tag{3}
\end{align}
\]
其中,\(C\) 被设为 -1。
网络结构
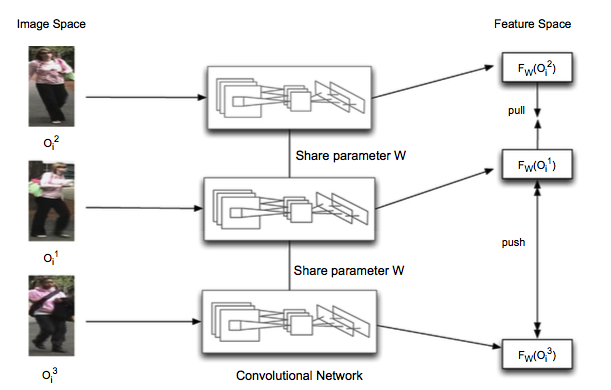
这三个子网络是共享参数的,目标函数是要让 \(F_W(O_i^2)\) 和 \(F_W(O_i^1)\) 靠近,而 \(F_W(O_i^3)\) 远离前两个特征向量。
训练算法
设 \(d(W,O_i)=||F_W(O_i^1)-F_W(O_i^2)||^2-||F_W(O_i^1)-F_W(O_i^3)||^2\),基于 (3) 式,我们可以得到梯度下降的导数公式:
\[
\begin{align}
& \frac{\partial f}{\partial W_j}=\sum_{O_i}{h(O_i)} \tag{7} \\
& h(O_i)=\begin{cases} \frac{\partial d(W,O_i)}{\partial W_j} & if\ d(W,O_i)>C \\ 0 & otherwise \end{cases} \tag{8}
\end{align}
\]
\[
\begin{align}
\frac{\partial d(W,O_i)}{\partial W_j}=&2(F_W(O_i^1)-F_W(O_i^2))\frac{\partial F_W(O_i^1)- \partial F_W(O_i^2)}{\partial W_j} \notag \\
&-2(F_W(O_i^1)-F_W(O_i^3))\frac{\partial F_W(O_i^1)- \partial F_W(O_i^3)}{\partial W_j} \tag{9}
\end{align}
\]
由此可知,每次梯度下降时,我们只需要计算出每个 triplet 的 \(F_W(O_i^1)\)、\(F_W(O_i^2)\)、\(F_W(O_i^3)\) 和 \(\frac{\partial F_W(O_i^1)}{\partial W_j}\)、\(\frac{\partial F_W(O_i^2)}{\partial W_j}\)、\(\frac{\partial F_W(O_i^3)}{\partial W_j}\),就可以得到 \(W_j\) 的导数。这种导数计算方式是基于 triplet 的,每对样本需要计算三次前向和三次后向。由此可以得到论文中的算法 1:

然而,在实际训练时,一张图片可能在一个 batch 的多个 triplet 中出现,因此可以用一些技巧来减少一些重复计算的工作。重新审视导数的计算流程:
\[
\begin{align}
\frac{\partial f}{\partial W}=\sum_{O_i}(\frac{\partial f}{\partial F_W(O_i^1)}\frac{\partial F_W(O_i^1)}{\partial W_j} + \frac{\partial f}{\partial F_W(O_i^2)}\frac{\partial F_W(O_i^2)}{\partial W_j} + \frac{\partial f}{\partial F_W(O_i^3)}\frac{\partial F_W(O_i^3)}{\partial W_j}) \notag
\end{align}
\]
可以发现,重复计算的地方在于 \(\frac{\partial F_W(O_i^1)}{\partial W_j}\)、\(\frac{\partial F_W(O_i^2)}{\partial W_j}\)、\(\frac{\partial F_W(O_i^3)}{\partial W_j}\) 这些项,而且这些项也只跟对应的输入图像有关,所以,我们的想法是把这些可以重复使用的项提取出来。
假设一个训练 batch 中的图片集合为 \(\{I_k^{'}\}=\{O_i^1\} \cup \{O_i^2\} \cup \{O_i^3\}\),\(m\) 为图片数量,则针对一张图片的导数计算公式为:
\[
\begin{align}
\sum_{O_i}\frac{\partial f}{\partial F_W(I_i)}\frac{\partial F_W(I_i)}{W_j}=\frac{\partial F_W(I_i)}{W_j}\sum_{O_i}\frac{\partial f}{\partial F_W(I_i)}\notag
\end{align}
\]
因此整个 batch 上的导数如下:
\[
\begin{align}
\frac{\partial f}{\partial W}=\sum_{i=1}^m\{\frac{\partial F_W(I_i)}{W_j}\sum_{O_i}\frac{\partial f}{\partial F_W(I_i)}\} \tag{18}
\end{align}
\]
\(\frac{\partial F_W(I_i)}{W_j}\) 只跟输入 \(I_i\) 有关,因此接下来要解决 \(\sum_{O_i}\frac{\partial f}{\partial F_W(I_i)}\) 的计算问题。后者的计算是跟 triplet 相关的:
\[
\begin{align}
\frac{\partial f}{\partial F_W(I_K^{'})}=\sum_{i=1}^{n}\frac{\partial \max\{||F_W(O_i^1)-F_W(O_i^2)||^2-||F_W(O_i^1)-F_W(O_i^3)||^2,C\}}{\partial F_W(I_K^{'})} \tag{19}
\end{align}
\]
由此我们可以得出论文中的算法 3:

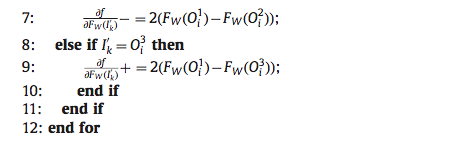
在此基础上,将 \(\frac{\partial f}{\partial F_W(I_K^{'})}\) 代入到 (18) 式,就得到了一个 batch 上的导数计算公式,即论文中的算法 2:

注意到,我们已经把原来基于 triplet 的计算方式转变为基于 image 的方式。后者可以大大减少计算量,我们只需要先计算出每张图片对应的 \(F_W(I_K^{'})\) 和 \(\frac{\partial F_W{I_K^{'}}}{\partial W_j}\),剩下的工作就是根据算法 2 计算出最终的导数。因此,这种计算方式使得整体的运算量只跟图片的数量有关。
最后要考虑的是样本生成的问题。最简单的想法是从所有可能的 triplet 组合中,随机挑选出若干的 triplet用于训练,但这种做法存在一个问题,考虑到数据集中的类别可能很大,因此所有 triplet 中包含的图片类别可能都是不同的,换句话说,网络在每次迭代时,处理的图片可能都是完全不同的,论文认为这种方式不利于参数的收敛。因此论文采用如下的 triplet 生成策略:在每轮迭代中,首先挑选出若干的类别(每个类别代表一个人),然后,对每个类别中的图片,从同类别的其他图片中随机选一张组成正样本对,从不同类别的图片中随机选一张组成负样本对。这种做法的优点在于,它的训练样本是梯度下降的时候动态生成的,假设显存中可以存放 300 张图片,那么对于最简单的 triplet 生成方法,可能只能放 100 对训练样本,但论文采用的生成策略,可以先从选定的几个类别中选出 300 张图片,然后进行 triplet 组合,等一次迭代训练完成后,再根据这 300 张图片随机生成另一种 triplet 组合。所以,这种方法不仅可以让网络更好地学习出样本对之间的距离约束关系,而且减少了频繁的 IO 操作。
下面给出完整的算法:

参考
论文笔记:Deep feature learning with relative distance comparison for person re-identification的更多相关文章
- 论文笔记——Deep Residual Learning for Image Recognition
论文地址:Deep Residual Learning for Image Recognition ResNet--MSRA何凯明团队的Residual Networks,在2015年ImageNet ...
- Note for Reidentification by Relative Distance Comparison
link Reidentification by Relative Distance Comparison Challenge: large visual appearance changes cau ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- [论文阅读] Deep Residual Learning for Image Recognition(ResNet)
ResNet网络,本文获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名. 本篇文章解决了深度神经网络中产生的退化问题(degradation problem). ...
- [论文理解]Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition 简介 这是何大佬的一篇非常经典的神经网络的论文,也就是大名鼎鼎的ResNet残差网络,论文主要通过构建了一种新 ...
- 论文笔记之:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection
Learning Cross-Modal Deep Representations for Robust Pedestrian Detection 2017-04-11 19:40:22 Moti ...
- 深度学习论文笔记-Deep Learning Face Representation from Predicting 10,000 Classes
来自:CVPR 2014 作者:Yi Sun ,Xiaogang Wang,Xiaoao Tang 题目:Deep Learning Face Representation from Predic ...
- 论文笔记-Deep Affinity Network for Multiple Object Tracking
作者: ShijieSun, Naveed Akhtar, HuanShengSong, Ajmal Mian, Mubarak Shah 来源: arXiv:1810.11780v1 项目:http ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
随机推荐
- Mac下MySql初始密码设置及mysql数据库操作
1. 首先 点击系统偏好设置 -> 点击MySQL, 在弹出的页面中,关闭服务.2. 进入终端命令输出: cd /usr/local/mysql/bin/ 命令,回车.3. 回车后,输入命令:s ...
- Lepus搭建企业级数据库全方位监控系统
前言 Lepus(天兔)数据库企业监控系统是一套由专业DBA针对互联网企业开发的一款专业.强大的企业数据库监控管理系统,企业通过Lepus可以对数据库的实时健康和各种性能指标进行全方位的监控.目前已经 ...
- Python Revisited Day 13 (正则表达式)
目录 13.1 Python的正则表达式语言 13.1.1 字符与字符类 13.1.2 量词 {m, n} ? + * 组与捕获 ?:可以关闭捕获 断言与标记 13.2 正则表达式模块 正则表达式模块 ...
- Airflow Python工作流引擎的重要概念介绍
Airflow Python工作流引擎的重要概念介绍 - watermelonbig的专栏 - CSDN博客https://blog.csdn.net/watermelonbig/article/de ...
- Linux 默认连接数
Linux 默认连接数 - 国内版 Binghttps://cn.bing.com/search?FORM=U227DF&PC=U227&q=Linux+%E9%BB%98%E8%AE ...
- 原生js设置rem
使用rem是为了界面响应不同尺寸的手机,引入下面的方法就可以使用rem了. setFontSize: function (doc, win) { var docEl = doc.documentEle ...
- svn 服务器部署
系统环境:CentOS 7.x安装方式:yum install (源码安装容易产生版本兼容的问题)安装软件:系统自动下载SVN软件 #检查是否安装了低版本的SVN[root@localhost /]# ...
- vue组件之前嵌套
https://www.cnblogs.com/chengduxiaoc/p/7099552.html <!DOCTYPE html> <html lang="en&quo ...
- vue独立构建和运行构建
有两种构建方式,独立构建和运行构建.它们的区别在于前者包含模板编译器而后者不包含. 模板编译器:模板编译器的职责是将模板字符串编译为纯 JavaScript 的渲染函数.如果你想要在组件中使用 tem ...
- 前端获取checkbox复选框的值 通过数组形式传递
html代码: <form role="form" class="select_people"> <div style="displ ...