DirectX11--深入理解HLSL常量缓冲区打包规则
HLSL常量缓冲区打包规则
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
尽管打包规则并不复杂,但是稍不留意就可能会导致因为打包规则的不理解而产生的数据错位问题。
下面会使用大量的例子来进行描述,并对有争议的部分使用图形调试器来反汇编着色器代码加以验证。
1. C++中的结构体数据是以字节流的形式传输给HLSL的
例1.1
若C++结构体和HLSL常量缓冲区如下:
// cpp
struct S1
{
XMFLOAT3 p1;
XMFLOAT3 p2;
};
// HLSL
cbuffer C1
{
float4 v1;
float4 v2;
}
则最终C1两个向量接收到的数据如下:
(p1.x, p1.y, p1.z, p2.x)
(p2.y, p2.z, empty, empty)
2. HLSL常量缓冲区中的向量不允许拆分
例2.1
// cpp
struct S1
{
XMFLOAT3 p1;
XMFLOAT3 p2;
};
// HLSL
cbuffer C1
{
float3 v1;
float4 v2;
}
v1将被单独打包成一个4D向量,确保常量缓冲区的内存按128位对齐。
C1的内存布局为:
(v1.x, v1.y, v1.z, empty)
(v2.x, v2.y, v2.z, v2.w)
这时用S1结构体的数据再传输给C1,结果如下:
(p1.x, p1.y, p1.z, p2.x)
(p2.y, p2.z, empty, empty)
例2.2
// HLSL
cbuffer C1
{
float2 v1;
float4 v2;
float2 v3;
}
v2无法拆分来填充v1的空位,而是单独起一行向量,这样C1的内存布局为:
(v1.x, v1.y, empty, empty)
(v2.x, v2.y, v2.z, v2.w)
(v3.x, v3.y, empty, empty)
3. HLSL常量缓冲区中多个相邻的变量若有空缺则优先打包进同一个4D向量中
例3.1
// HLSL
cbuffer C1
{
float v1;
float2 v2;
float v3;
float2 v4;
float v5;
}
C1的内存布局为:
(v1.x, v2.x, v2.y, v3.x)
(v4.x, v4.y, v5.x, empty)
打包顺序是从最上面的变量开始往下的。
例3.2
// HLSL
cbuffer C1
{
float2 v1;
float v2;
float3 v3;
}
C1的内存布局为:
(v1.x, v1.y, v2.x, empty)
(v3.x, v3.y, v3.z, empty)
4. 对于在常量缓冲区的结构体,也会进行打包操作
通过几个例子来进行观察
例4.1
// HLSL
struct S1
{
float2 p1;
float3 p2;
float p3;
};
cbuffer C1
{
float v1;
S1 v2;
float3 v3;
}
C1的内存布局为:
(v1.x, empty, empty, empty)
(v2.p1.x, v2.p1.y, empty, empty)
(v2.p2.x, v2.p2.y, v2.p2.z, v2.p3.x)
(v3.x, v3.y, v3.z, empty)
例4.2
// HLSL
struct S1
{
float4 p1;
float p2;
};
cbuffer C1
{
S1 v1;
float2 v2;
}
C1的内存布局为:
(v1.p1.x, v1.p1.y, v1.p1.z, v1.p1.w)
(v1.p2.x, v2.x, v2.y, empty)
所以,结构体常量前面的所有常量都会被打包成4D向量,但结构体常量的最后一个成员可能会和后续的常量打包成4D向量。
5. 对于在常量缓冲区的数组,需要特殊对待
数组中的每一个元素都会独自打包,但对于最后一个元素来说如果后续的变量不是数组、结构体且还有空缺,则可以进行打包操作。
例5.1
// HLSL
cbuffer C1
{
float v1[4];
}
C1的内存布局为:
(v1[0].x, empty, empty, empty)
(v1[1].x, empty, empty, empty)
(v1[2].x, empty, empty, empty)
(v1[3].x, empty, empty, empty)
可以看到,一个本应该是16字节的数组变量实际上变成了64字节的4个4D向量,造成内存的大量浪费。如果真的要使用这种数组,下面的声明方式通过强制转换,可以保证没有空间浪费(C++不允许这么做):
// HLSL
cbuffer C1
{
float4 v1;
}
static float packArray[4] = (float[4])v1;
例5.2
// HLSL
cbuffer C1
{
float2 v1[4];
float2 v2;
}
C1的内存布局实际上为:
(v1[0].x, v1[0].y, empty, empty)
(v1[1].x, v1[1].y, empty, empty)
(v1[2].x, v1[2].y, empty, empty)
(v1[3].x, v1[3].y, v2.x, v2.y)
例5.3
// HLSL
struct S1
{
float p1;
int p2;
};
cbuffer C1
{
S1 v1[4];
float v2;
float3 v3;
}
C1的内存布局实际上为:
(v1[0].p1, v1[0].p2, empty, empty)
(v1[1].p1, v1[1].p2, empty, empty)
(v1[2].p1, v1[2].p2, empty, empty)
(v1[3].p1, v1[3].p2, v2.x, empty)
(v3.x, v3.y, v3.z, empty)
例5.4
// HLSL
struct S1
{
float p1;
int p2;
};
cbuffer C1
{
float v1[2];
S1 v2;
}
C1的内存布局为:
(v1[0].x, empty, empty, empty)
(v1[1].x, empty, empty, empty)
(v2.p1, v2.p2, empty, empty)
使用VS的图形调试器来分析HLSL常量缓冲区的内存布局
首先确保着色器、常量缓冲区都已经绑定到渲染管线,如果该常量缓冲区被绑定到像素着色阶段,就应该在图形调试器中对像素着色器代码进行调试。
例4.1的验证
开启反汇编后,找到之前所放的常量缓冲区:
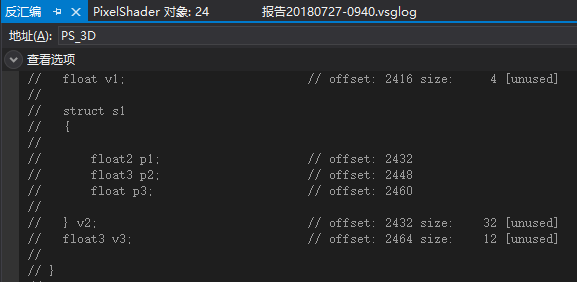
在这些样例中已经确保了常量缓冲区前面的所有值都已经打包好(16字节对齐)。
这里v1的偏移值为2416,然后可以看到结构体对象v2内的p1偏移值为2432,说明v1单独被打包成16字节向量。然后p1无法和p2打包,所以p1单独打包成16字节。
然后p2和p3被打包,因为v3的偏移值为2464,p2的偏移值为2448。
所以内存布局如下:
(v1.x, empty, empty, empty)
(v2.p1.x, v2.p1.y, empty, empty)
(v2.p2.x, v2.p2.y, v2.p2.z, v2.p3.x)
(v3.x, v3.y, v3.z, empty)
例4.2的验证
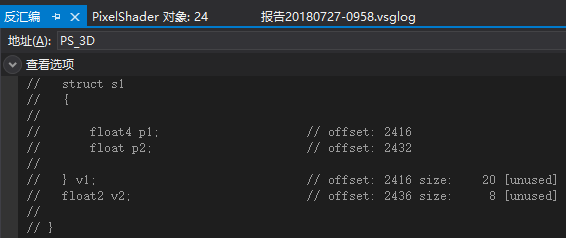
v1的偏移值为2416,p1构成单独的4D向量,p2会和后续的v2打包成新的4D向量,而不是单独打包。
所以内存布局如下:
(v1.p1.x, v1.p1.y, v1.p1.z, v1.p1.w)
(v1.p2.x, v2.x, v2.y, empty)
例5.2的验证
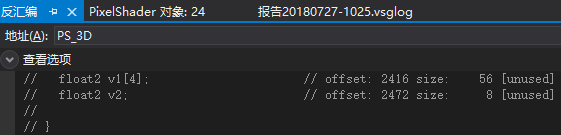
如果数组的每个元素都单独打包的话,理论上这个数组所占字节数为64,但这里数组的最后一个float2和下面的float2打包成一个4D向量。
所以内存布局如下:
(v1[0].x, v1[0].y, empty, empty)
(v1[1].x, v1[1].y, empty, empty)
(v1[2].x, v1[2].y, empty, empty)
(v1[3].x, v1[3].y, v2.x, v2.y)
例5.3的验证
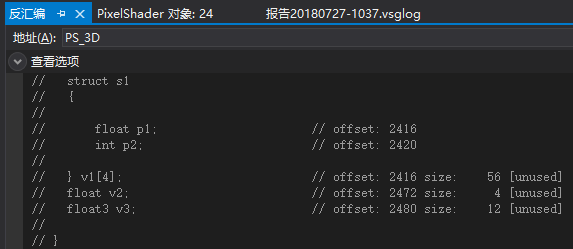
可以看到结构体数组的每个结构体元素都被单独打包成1个4D向量,但数组最后一个元素跟v2打包到一起。
内存布局如下:
(v1[0].p1, v1[0].p2, empty, empty)
(v1[1].p1, v1[1].p2, empty, empty)
(v1[2].p1, v1[2].p2, empty, empty)
(v1[3].p1, v1[3].p2, v2.x, empty)
(v3.x, v3.y, v3.z, empty)
例5.4的验证
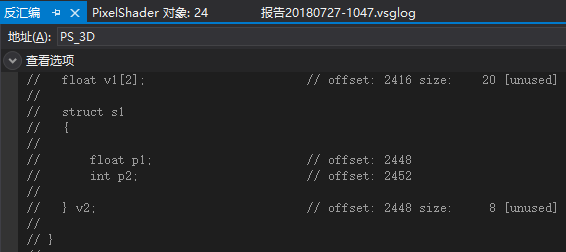
因为数组的后面是结构体,而结构体要求前面的所有变量都要先打包好,所以数组的2个元素分别单独打包。
内存布局如下:
(v1[0].x, empty, empty, empty)
(v1[1].x, empty, empty, empty)
(v2.p1, v2.p2, empty, empty)
记一次打包问题引发的错误
在一次进行图形调试的时候,发现原本设置平行光和点光灯的数目为1,到了图形调试器却变成了点光灯和聚光灯的数目为1
C++代码如下:
struct CBNeverChange
{
DirectionalLight dirLight[10]; // 已按16字节对齐
PointLight pointLight[10]; // 已按16字节对齐
SpotLight spotLight[10]; // 已按16字节对齐
int numDirLight;
int numPointLight;
int numSpotLight;
int pad;
};
// ...
mCBNeverChange.numDirLight = 1;
mCBNeverChange.numPointLight = 1;
mCBNeverChange.numSpotLight = 0;
HLSL代码如下:
cbuffer CBNeverChange : register(b3)
{
DirectionalLight gDirLight[10];
PointLight gPointLight[10];
SpotLight gSpotLight[10];
int gNumDirLight;
int gNumPointLight;
int gNumSpotLight;
}
在图形调试器查看C++提供的字节数据,可以看到最后四个32位的传入是没有问题的
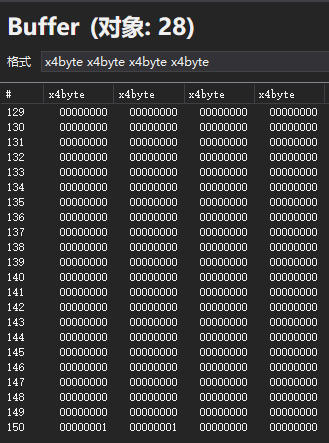
经过一番折腾,翻到像素着色器的反编译,发现里面有常量缓冲区数据偏移信息:
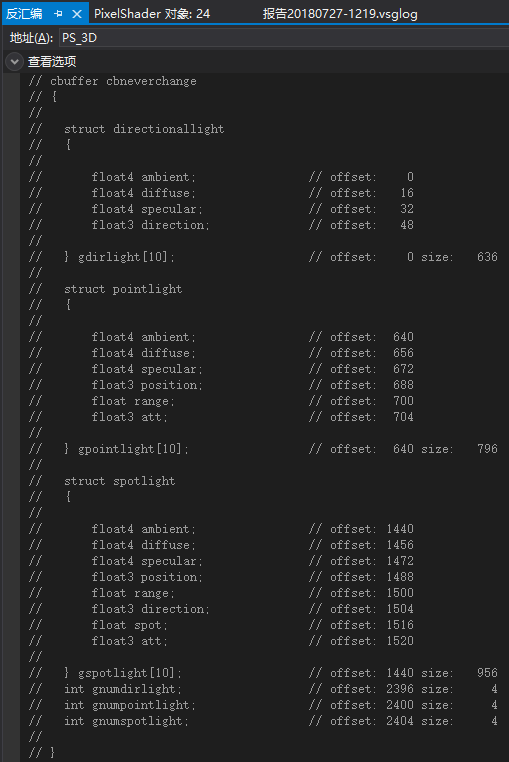
仔细比对的话可以发现从gNumDirLight开始的字节偏移量出现了不是我想要的结果,本应该是2400的值,结果却是2396,导致原本赋给gNumDirLight和gNumPointLight为1的值,却赋给了gNumPointLight和gNumSpotLight。这也是我为什么要写出这篇文章的原因。
常量缓冲区声明技巧
首先重新总结之前的打包规则:
1. C++中的结构体数据是以字节流的形式传输给HLSL的;
2. HLSL常量缓冲区中的向量不允许拆分;
3. HLSL常量缓冲区中多个相邻的变量若有空缺则优先打包进同一个4D向量中;
4. HLSL常量缓冲区中,结构体常量前面的所有常量都会被打包成4D向量,内部也进行打包操作,但结构体的最后一个成员可能会和后续的常量打包成4D向量;
5. 数组中的每一个元素都会独自打包,但对于最后一个元素来说如果后续的变量不是数组、结构体且还有空缺,则可以进行打包操作。
所以避免出现潜在问题的办法如下:
1. 若要使用数组,数组的类型最好能按16字节对齐
2. 结构体的总大小也需要按16字节对齐。
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
DirectX11--深入理解HLSL常量缓冲区打包规则的更多相关文章
- DirectX11 With Windows SDK--03 索引缓冲区、常量缓冲区
前言 一个立方体有8个顶点,然而绘制一个立方体需要画12个三角形,如果按照前面的方法绘制的话,则需要提供36个顶点,而且这里面的顶点数据会重复4次甚至5次.这样的绘制方法会占用大量的内存空间. 接下来 ...
- DirectX11--深入理解与使用缓冲区资源
前言 在Direct3D 11中,缓冲区属于其中一种资源类型,它在内存上的布局是一维线性的.根据HLSL支持的类型以及C++的使用情况,缓冲区可以分为下面这些类型: 顶点缓冲区(Vertex Buff ...
- Direct3D 11 Tutorial 7:Texture Mapping and Constant Buffers_Direct3D 11 教程7:纹理映射和常量缓冲区
概述 在上一个教程中,我们为项目引入了照明. 现在我们将通过向我们的立方体添加纹理来构建它. 此外,我们将介绍常量缓冲区的概念,并解释如何使用缓冲区通过最小化带宽使用来加速处理. 本教程的目的是修改中 ...
- 【转】Directx11 HelloWorld之HLSL的Effect框架的使用
最近尝试用了下Directx下的Effect框架,作为一初学者初学者,说下为什么我们要使用Effect框架及其好处吧. 首先Effect最大好处的就是简单,使得编写Shader绘制的程序工作量大大下降 ...
- Java语言基本语法(一)————关键字&标识符(Java语言标识符命名规范&Java语言的包名、类名、接口名、变量名、函数名、常量名命名规则 )
一.关键字 关键字的定义和特点 定义:被Java语言赋予特殊含义,用做专门用途的字符串(单词). 特点:关键字中所有字母均为小写 下面列举一些常用的关键字. 用于定义数据类型的关键字:byte.sho ...
- 理解SVG的图形填充规则
SVG的图形填充规则通过fill-rule属性来指定. 有效值: nonzero | evenodd | inherit 默认值: nonzero fill-rule属性用于指定使用哪一种算法 ...
- Java中包、类、方法、属性、常量的命名规则
1:包(package):用于将完成不同功能的类分门别类,放在不同的目录(包)下,包的命名规则:将公司域名反转作为包名.比如www.baidu.com 对于包名:每个字母都需要小写.比如:com.ba ...
- 理解JAVA常量池
下面是一些String相关的常见问题: String中的final用法和理解final StringBuffer a = new StringBuffer("111");final ...
- 从Java到C++——常量的使用规则
常量是一种标识符,它的值在执行期间恒定不变.C语言用 #define来定义常量(称为宏常量). C++ 语言除了 #define外还能够用const来定义常量(称为const常量). 一.为什么须要常 ...
随机推荐
- 使用jquery实现选项卡切换效果
几张简陋的框架效果图 页面加载时: 选项卡操作后: css样式: <style type="text/css"> *{margin:0px;padding:0px;} ...
- Redhat安装Oracle 11g (转)
1.1 安装前准备 1.1.1 修改操作系统核心参数 在Root用户下执行以下步骤: 1.1.1.1 修改/etc/security/limits.conf文件 输入命令:vi /et ...
- Docker: 构建Nginx,PHP,Tomcat基础镜像
Usage: docker build [OPTIONS] PATH | URL | - [flags] Options: -t, --tag list # 镜像名称 -f, --file strin ...
- 通过ip查询自己电脑的共享文件夹
查看电脑所有的共享文件或文件夹的三种方法如下: 方法一. 右键点击网上邻居,点击属性进入网上邻居属性页面. 选中本地连接,在窗口的左下方有详细信息,可以看到内网IP,记住IP地址. 直接在地址栏输入记 ...
- Python爬虫 selenium
库的安装 pip3 install selenium 声明浏览器对象 from selenium import webdriver browser = webdriver.Chrome() brows ...
- Vue项目中的RSA加解密
前后端使用rsa加密: 一般是客户端初始化时访问登录服务时,服务端面动态生成一对RSA对,公钥传给客户端,客户端拿到后,用户输入密码后,点登录时用公钥加密返回给服务端,服务端用私钥解就行了 一.安装 ...
- 货车运输-洛谷-1967-LCA+最大生成树(kruskal(并查集))
传送门 一道:LCA+最大生成树 个人认为把这两个的板子写好(并熟练掌握了之后)就没什么难的 (但我还是de了好久bug)qwq 最大生成树:其实就是最小生成树的变形 我用的是kruskal (个人觉 ...
- Linux内核入门到放弃-内核活动-《深入Linux内核架构》笔记
中断 中断类型 同步中断和异常.这些由CPU自身产生,针对当前执行的程序 异步中断.这是经典的中断类型,由外部设备产生,可能发生在任意时间. 在退出中断中,内核会检查下列事项. 调度器是否应该选择一个 ...
- Asible第三章:roles--小白博客
本节内容: 什么场景下会用roles? roles示例 一.什么场景下会用roles? 假如我们现在有3个被管理主机,第一个要配置成httpd,第二个要配置成php服务器,第三个要配置成MySQL服务 ...
- ASP.NET MVC系列:web.config中ConnectionString aspnet_iis加密与AppSettings独立文件
1. web.config中ConnectionString aspnet_iis加密 web.config路径:E:\Projects\Libing.Web\web.config <conne ...