kafka笔记9(监控)
Kafka提供的所有度量指标都是通过JMX(Java Management Extensions)接口访问
JMX端口查询: zookeeper上获取端口信息 /brokers/ids/<ID>节点包含json格式的broker信息,里面含有JMX对应的主机名和端口
JMX接口提供的是内部度量指标,第三方程序提供的则是外部度量指标
应用程序健康检测:
使用外部进程来报告broker的运行状态(健康检测)
在broker停止发送度量指标时发出告警(stale度量指标)
broker度量指标
非同步分区数量: 作为首领的broker有多少个分区处于非同步状态

该值大于0就要采取措施,首先建议重新选举首领,看看能否解决问题
问题排查步骤:

集群级别的问题:
不均衡的负载 资源过度消耗
问题定位: 用到以下度量指标
分区数量 首领分区数量 主题流入字节速率 主题流入消息速率
在一个均衡集群里,度量指标的数值在整个集群范围内均等的
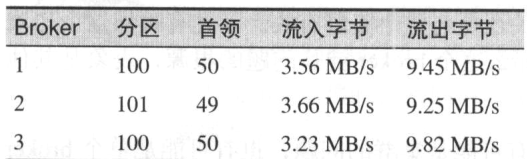
以下资源出现过度消耗会导致分区不同步

主机级别问题:
硬件问题
磁盘问题是常见的故障,导致分区不同步,拖慢整个集群broker请求
进程冲突
本地配置的不一致
活跃控制器数量:
表示broker是否就是当前的集群控制器,1代表是,任何时候集群应该只有一个集群控制器

请求处理器空闲率

空闲率低于20%说明存在潜在问题,低于10%说明存在性能问题
主题流入字节

主题流出字节

主题流入消息

分区数量:

首领数量:
该度量指标表示broker拥有的首领分区数量,与其他度量一样,该度量指标也应该在整个集群的broker上保持均等

一个均衡集群如果复制系数是N,则该百分比应该为1/N
离线分区: 显示集群里没有首领的分区数量
分区离线的主要原因: 包含分区副本的broker都关闭了; 消息不匹配,没有同步副本可以拿到首领身份(并且禁用了不完全的首领选举)

请求度量指标:


主题和分区的度量指标:(指定某个主题)
主题实例的度量指标: 取决于集群主题数量

分区实例的度量指标


JAVA虚拟机监控
垃圾回收:

Java操作系统监控

日志:
Kafka.controller 记录集群控制器的消息
kafka.server.ClientQuotaManager 记录与生产和消费配额活动相关的信息
启用kafka.log.LogCleaner kafka.log.Cleaner kafka.log.LogCleanerManager这些日志,并设置为DEBUG级别,就可以输出日志压缩线程的运行状态
客户端监控
生产者度量指标

record-error-rate 是一个完全有必要对其设置告警的属性,一般情况下是0,大于0,说明生产者正在丢弃无法发送的消息
record-retry-rate 重试次数
request-latency-avg 设置告警,表示发送一个生产者请求到broker所需的平均时间
3种不同视图: outgoing-byte-rate 每秒钟消息的字节数 record-send-rate 每秒消息的数量 request-rate 每秒钟生产者发送给broker的请求数
Per-broker和Per-topic 度量指标
消费者度量指标:

Fetchmanager度量指标
fetch-latency-avg 表示消费者向Broker发送请求所需要的时间


Coordinator度量指标

配额

延迟监控
端到端监控
:
kafka笔记9(监控)的更多相关文章
- Kafka 集群消息监控系统:Kafka Eagle
Kafka Eagle 1.概述 在开发工作当中,消费 Kafka 集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提下,我们可以使用 Kafka 提供的命令工具,配合 Zookeeper ...
- kafka集群监控之kafka-manager部署(kafka-manager的进程为:ProdServerStart)
kafka集群监控之kafka-manager部署(ProdServerStart) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 雅虎官网GitHub项目:https://git ...
- Kafka笔记整理(三):消费形式验证与性能测试
Kafka消费形式验证 前面的<Kafka笔记整理(一)>中有提到消费者的消费形式,说明如下: .每个consumer属于一个consumer group,可以指定组id.group.id ...
- kafka笔记博客
大数据数据流组件选择: https://www.cnblogs.com/yinzhengjie/articles/11155051.html 初识Apache Kafka 核心概念: https:// ...
- 完整的ELK+filebeat+kafka笔记
之前有写过elasticsearch集群和elk集群的博客, 都是基于docker的,使用docker-compose进行编排(K8S暂未掌握) 三台服务器搭建es集群:https://www.cnb ...
- Kafka笔记--监控系统KafkaOffsetMonitor
KafkaOffsetMonitor下载链接: http://download.csdn.net/detail/changong28/7930337github官方:https://github.co ...
- 【转载】apache kafka系列之-监控指标
原文地址:http://blog.csdn.net/lizhitao/article/details/24581907 1.监控目标 1.当系统可能或处于亚健康状态时及时提醒,预防故障发生 2.报警提 ...
- apache kafka系列之-监控指标
apache kafka中国社区QQ群:162272557 1.监控目标 1.当系统可能或处于亚健康状态时及时提醒,预防故障发生 2.报警提示 a.短信方式 b.邮件 2.监控内容 2.1 机器监控 ...
- Kafka OffsetMonitor:监控消费者和延迟的队列
一个小应用程序来监视kafka消费者的进度和它们的延迟的队列. KafkaOffsetMonitor是用来实时监控Kafka集群中的consumer以及在队列中的位置(偏移量). 你可以查看当前的消费 ...
随机推荐
- Metaphor of topological basis and open set
The definition of topological basis for a space $X$ requires that each point $x$ in $X$ is contained ...
- Linux安装Tomcat-Nginx-FastDFS-Redis-Solr-集群——【第六集之基本命令使用】
学习命令的方法:linux中所有操作都是命令操作,可想而知命令有多少,更严重的是每个命令有很多参数,记命令容易,记参数就难了,所以建议: 自己准备一个博客,把通常用到的命令及其功能记载下来,用到的时候 ...
- 在'for'循环中获取索引
ints = [8, 23, 45, 12, 78] 当使用循环遍历它时,在这种情况下如何访问循环索引,从1到5? 最普遍的办法是设置索引变量(通常在C或PHP等语言中使用),但这被认为是非pytho ...
- eclipse 下载安装单元测试log4j的配置与搭建
搭建log4j的具体步骤 1.下载jar包放在lib 拓展库中 百度云下载 地址 链接:https://pan.baidu.com/s/1Cvb22kCJcymORehwhKnCrQ 提取码:b55m ...
- win10安装Oracle11g-出现INS-13001环境不满足最低要求问题
今天安装Oracle11g,出现INS-13001环境不满足最低要求问题: 解决方法 在安装时点击setup.exe之后,出现了:[INS-13001]环境不满足最低要求 这时,打开你的解压后的dat ...
- leetcode算法题整理
一.线性表,如数组,单链表,双向链表 线性表.数组 U1.有序数组去重,返回新数组长度 A = [1,1,2] -> [1,2] 返回2 分析:其实一般数组的问题都可以用两个指针解决,一个指 ...
- (61)Wangdao.com第十天_JavaScript 立即执行函数
1. 立即执行函数 创建完了就执行,只执行完就不再执行了. ( function(){} )(); 例 ( function(a,b){ alert("Hello ,我是一个匿名函数!&qu ...
- PHP使用 strpos() 注意事项
返回字符出现的第一个位置, 如果字符在被搜索字符串的开头, 则会返回 ‘0’ 因此, 在使用此函数判断 字符串是否包含 某一个字符时 使用: if(strpos('string','str') != ...
- cmd 命令 net start mongodb 启动不了,提示 net 不是内部命令或者外部命令
1.要管理员的身份进入 cmd 2.右击我的电脑-->属性-->高级系统设置 3.选择高级-->环境变量 4.找到系统变量-->Path-->编辑 5.把 C:\wind ...
- Java代码导入导出 Excel 表格最简单的方法
import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStrea ...