java爬虫案例学习
最近几天很无聊,学习了一下java的爬虫,写一些自己在做这个案例的过程中遇到的问题和一些体会
1.学习目标
练习爬取京东的数据,图片+价格+标题等等
2.学习过程
1·开发工具
JDK1.8
IntelliJ IDEA
IDEA自带的Maven
2.使用技术
Spring Boot+Spring Data JPA
3.数据库准备
CREATE TABLE `jd_item` ( `id` ) NOT NULL AUTO_INCREMENT COMMENT '主键id', `spu` ) DEFAULT NULL COMMENT '商品集合id', `sku` ) DEFAULT NULL COMMENT '商品最小品类单元id', `title` ) DEFAULT NULL COMMENT '商品标题', `price` ) DEFAULT NULL COMMENT '商品价格', `pic` ) DEFAULT NULL COMMENT '商品图片', `url` ) DEFAULT NULL COMMENT '商品详情地址', `created` datetime DEFAULT NULL COMMENT '创建时间', `updated` datetime DEFAULT NULL COMMENT '更新时间', PRIMARY KEY (`id`), KEY `sku` (`sku`) USING BTREE ) ENGINE DEFAULT CHARSET=utf8 COMMENT='京东商品表';
4.添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.2.RELEASE</version>
</parent>
<groupId>cn.itcast.crawler</groupId>
<artifactId>itcast-crawler-jd</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--SpringMVC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--SpringData Jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--MySQL连接包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- HttpClient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
<!--Jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!--工具包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
</dependencies>
</project>
5.添加配置文件
#DB Configuration: spring.datasource.driverClassName=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://127.0.0.1:3306/crawler spring.datasource.username=root spring.datasource.password=root #JPA Configuration: spring.jpa.database=MySQL spring.jpa.show-sql=true
6.代码实现
1.pojo
@Entity
@Table(name = "jd_item")
public class Item {
//主键
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
//标准产品单位(商品集合)
private Long spu;
//库存量单位(最小品类单元)
private Long sku;
//商品标题
private String title;
//商品价格
private Double price;
//商品图片
private String pic;
//商品详情地址
private String url;
//创建时间
private Date created;
//更新时间
private Date updated;
set/get
}
2.编写dao
public interface ItemDao extends JpaRepository<Item,Long> {
}
3.编写service接口
public interface ItemService {
//根据条件查询数据
public List<Item> findAll(Item item);
//保存数据
public void save(Item item);
}
4.ItemServiceImpl实现类
@Service
public class ItemServiceImpl implements ItemService {
@Autowired
private ItemDao itemDao;
@Override
public List<Item> findAll(Item item) {
Example example = Example.of(item);
List list = this.itemDao.findAll(example);
return list;
}
@Override
@Transactional
public void save(Item item) {
this.itemDao.save(item);
}
}
5.编写引导类
@SpringBootApplication
//设置开启定时任务
@EnableScheduling
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
6. 封装HttpClient
@Component
public class HttpUtils {
private PoolingHttpClientConnectionManager cm;
public HttpUtils() {
this.cm = new PoolingHttpClientConnectionManager();
// 设置最大连接数
cm.setMaxTotal(200);
// 设置每个主机的并发数
cm.setDefaultMaxPerRoute(20);
}
//获取内容
public String getHtml(String url) {
// 获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
// 声明httpGet请求对象
HttpGet httpGet = new HttpGet(url);
// 设置请求参数RequestConfig
httpGet.setConfig(this.getConfig());
CloseableHttpResponse response = null;
try {
// 使用HttpClient发起请求,返回response
response = httpClient.execute(httpGet);
// 解析response返回数据
if (response.getStatusLine().getStatusCode() == 200) {
String html = "";
// 如果response。getEntity获取的结果是空,在执行EntityUtils.toString会报错
// 需要对Entity进行非空的判断
if (response.getEntity() != null) {
html = EntityUtils.toString(response.getEntity(), "UTF-8");
}
return html;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (response != null) {
// 关闭连接
response.close();
}
// 不能关闭,现在使用的是连接管理器
// httpClient.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
//获取图片
public String getImage(String url) {
// 获取HttpClient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
// 声明httpGet请求对象
HttpGet httpGet = new HttpGet(url);
// 设置请求参数RequestConfig
httpGet.setConfig(this.getConfig());
CloseableHttpResponse response = null;
try {
// 使用HttpClient发起请求,返回response
response = httpClient.execute(httpGet);
// 解析response下载图片
if (response.getStatusLine().getStatusCode() == 200) {
// 获取文件类型
String extName = url.substring(url.lastIndexOf("."));
// 使用uuid生成图片名
String imageName = UUID.randomUUID().toString() + extName;
// 声明输出的文件
OutputStream outstream = new FileOutputStream(new File("D:/images/" + imageName));
// 使用响应体输出文件
response.getEntity().writeTo(outstream);
// 返回生成的图片名
return imageName;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (response != null) {
// 关闭连接
response.close();
}
// 不能关闭,现在使用的是连接管理器
// httpClient.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
//获取请求参数对象
private RequestConfig getConfig() {
RequestConfig config = RequestConfig.custom().setConnectTimeout(1000)// 设置创建连接的超时时间
.setConnectionRequestTimeout(500) // 设置获取连接的超时时间
.setSocketTimeout(10000) // 设置连接的超时时间
.build();
return config;
}
}
7. 实现数据抓取
@Component
public class ItemTask {
@Autowired
private HttpUtils httpUtils;
@Autowired
private ItemService itemService;
public static final ObjectMapper MAPPER = new ObjectMapper();
//设置定时任务执行完成后,再间隔100秒执行一次
@Scheduled(fixedDelay = 1000 * 100)
public void process() throws Exception {
//分析页面发现访问的地址,页码page从1开始,下一页oage加2
String url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&s=5760&click=0&page=";
//遍历执行,获取所有的数据
for (int i = 1; i < 10; i = i + 2) {
//发起请求进行访问,获取页面数据,先访问第一页
String html = this.httpUtils.getHtml(url + i);
//解析页面数据,保存数据到数据库中
this.parseHtml(html);
}
System.out.println("执行完成");
}
//解析页面,并把数据保存到数据库中
private void parseHtml(String html) throws Exception {
//使用jsoup解析页面
Document document = Jsoup.parse(html);
//获取商品数据
Elements spus = document.select("div#J_goodsList > ul > li");
//遍历商品spu数据
for (Element spuEle : spus) {
//获取商品spu
Long spuId = Long.parseLong(spuEle.attr("data-spu"));
//获取商品sku数据
Elements skus = spuEle.select("li.ps-item img");
for (Element skuEle : skus) {
//获取商品sku
Long skuId = Long.parseLong(skuEle.attr("data-sku"));
//判断商品是否被抓取过,可以根据sku判断
Item param = new Item();
param.setSku(skuId);
List<Item> list = this.itemService.findAll(param);
//判断是否查询到结果
if (list.size() > 0) {
//如果有结果,表示商品已下载,进行下一次遍历
continue;
}
//保存商品数据,声明商品对象
Item item = new Item();
//商品spu
item.setSpu(spuId);
//商品sku
item.setSku(skuId);
//商品url地址
item.setUrl("https://item.jd.com/" + skuId + ".html");
//创建时间
item.setCreated(new Date());
//修改时间
item.setUpdated(item.getCreated());
//获取商品标题
String itemHtml = this.httpUtils.getHtml(item.getUrl());
String title = Jsoup.parse(itemHtml).select("div.sku-name").text();
item.setTitle(title);
//获取商品价格
String priceUrl = "https://p.3.cn/prices/mgets?skuIds=J_"+skuId;
String priceJson = this.httpUtils.getHtml(priceUrl);
//解析json数据获取商品价格
double price = MAPPER.readTree(priceJson).get(0).get("p").asDouble();
item.setPrice(price);
//获取图片地址
String pic = "https:" + skuEle.attr("data-lazy-img").replace("/n9/","/n1/");
System.out.println(pic);
//下载图片
String picName = this.httpUtils.getImage(pic);
item.setPic(picName);
//保存商品数据
this.itemService.save(item);
}
}
}
}
3.结果
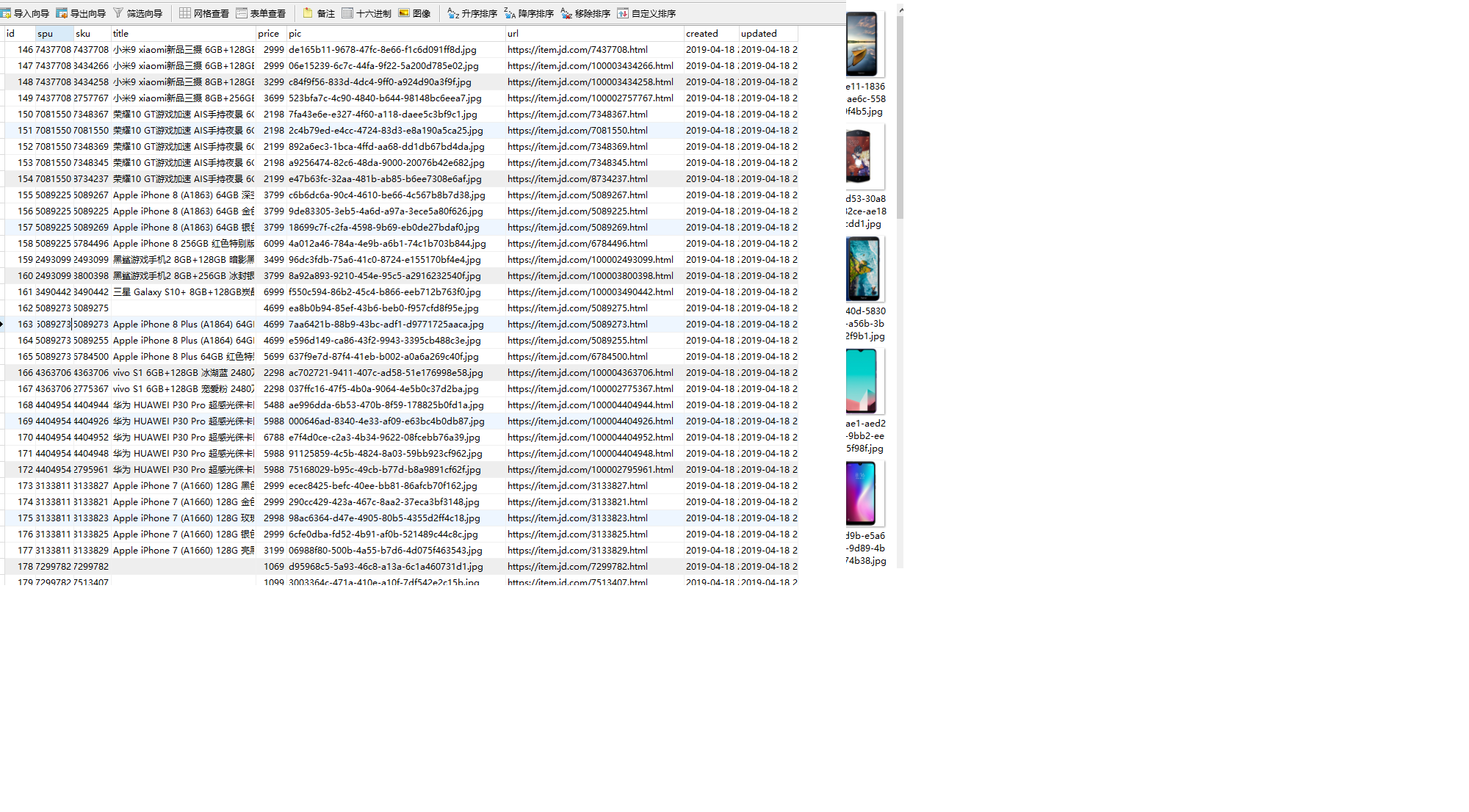

4.总结全文
在写代码代码的时候遇到一下的错误,首先打开了京东的要抓取的页面url="xxxxxx",但是在抓取的时候总是抓取不到数据 循环里面的spus总是为0,经过我多方查找信息,把上面的数据修改为一下代码,就成功了
package cn.itboxue.jd.task;
import cn.itboxue.jd.pojo.Item;
import cn.itboxue.jd.serivce.ItemService;
import cn.itboxue.jd.util.HttpUtils;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Date;
import java.util.List;
@Component
public class ItemTask {
@Autowired
private HttpUtils httpUtils;
@Autowired
private ItemService itemService;
private static final ObjectMapper MAPPER = new ObjectMapper();
//当下载任务完成后,间隔多长时间进行下一次的任务。
@Scheduled(fixedDelay = 100 * 1000)
public void itemTask() throws Exception {
//声明需要解析的初始地址
/*
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq%22%20+%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%22=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&s=113&click=0&page=
*/
String url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq%22%20+%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%22=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&s=113&click=0&page=";
//按照页面对手机的搜索结果进行遍历解析
for (int i = 1; i < 100; i = i + 2) {
Document doc = Jsoup.connect(url+i).maxBodySize(0).get();
//doc获取整个页面的所有数据
Elements ulList = doc.select("ul[class='gl-warp clearfix']");
Elements liList = ulList.select("li[class='gl-item']");
this.parse(liList);
}
System.out.println("手机数据抓取完成!");
}
//解析页面,获取商品数据并存储
private void parse( Elements liList) throws Exception {
//解析html获取Document
// Document doc = Jsoup.parse(html);
//System.out.print(doc);
//获取spu信息
//Elements elements = doc.select("div#J_goodsList > ul > li");
//System.out.println(elements+"是否有数据");
for (Element spuEle : liList) {
//获取spu
long spu = Long.parseLong(spuEle.attr("data-spu"));
//获取sku信息
Elements skuEles = spuEle.select("li.ps-item");
for (Element skuEle : skuEles) {
//获取sku
long sku = Long.parseLong(skuEle.select("[data-sku]").attr("data-sku"));
//根据sku查询商品数据
Item item = new Item();
item.setSku(sku);
List<Item> list = this.itemService.findAll(item);
if(list.size()>0) {
//如果商品存在,就进行下一个循环,该商品不保存,因为已存在
continue;
}
//设置商品的spu
item.setSpu(spu);
//获取商品的详情的url
String itemUrl = "https://item.jd.com/" + sku + ".html";
item.setUrl(itemUrl);
//获取商品的图片
String picUrl ="https:"+ skuEle.select("img[data-sku]").first().attr("data-lazy-img");
picUrl = picUrl.replace("/n9/","/n1/");
String picName = this.httpUtils.doGetImage(picUrl);
item.setPic(picName);
//获取商品的价格
String priceJson = this.httpUtils.doGetHtml("https://p.3.cn/prices/mgets?skuIds=J_" + sku);
double price = MAPPER.readTree(priceJson).get(0).get("p").asDouble();
item.setPrice(price);
//获取商品的标题
String itemInfo = this.httpUtils.doGetHtml(item.getUrl());
String title = Jsoup.parse(itemInfo).select("div.sku-name").text();
item.setTitle(title);
item.setCreated(new Date());
item.setUpdated(item.getCreated());
//保存商品数据到数据库中
this.itemService.save(item);
}
}
}
}
今天的笔记就做到这里吧,希望以后的想学习java爬虫的爱好者少走弯路,谢谢。。。。。。。
2019-04-1921:07:56
作者:何秀好
java爬虫案例学习的更多相关文章
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- 【Python爬虫案例学习】Python爬取天涯论坛评论
用到的包有requests - BeautSoup 我爬的是天涯论坛的财经论坛:'http://bbs.tianya.cn/list.jsp?item=develop' 它里面的其中的一个帖子的URL ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- 【Python爬虫案例学习】python爬取淘宝里的手机报价并以价格排序
第一步: 先分析这个url,"?"后面的都是它的关键字,requests中get函数的关键字的参数是params,post函数的关键字参数是data, 关键字用字典的形式传进去,这 ...
- 【Python爬虫案例学习2】python多线程爬取youtube视频
转载:https://www.cnblogs.com/binglansky/p/8534544.html 开发环境: python2.7 + win10 开始先说一下,访问youtube需要那啥的,请 ...
- 【Python爬虫案例学习】Python爬取淘宝店铺和评论
安装开发需要的一些库 (1) 安装mysql 的驱动:在Windows上按win+r输入cmd打开命令行,输入命令pip install pymysql,回车即可. (2) 安装自动化测试的驱动sel ...
- java网络爬虫基础学习(三)
尝试直接请求URL获取资源 豆瓣电影 https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort= ...
- java网络爬虫基础学习(一)
刚开始接触java爬虫,在这里是搜索网上做一些理论知识的总结 主要参考文章:gitchat 的java 网络爬虫基础入门,好像要付费,也不贵,感觉内容对新手很友好. 一.爬虫介绍 网络爬虫是一个自动提 ...
- Java 爬虫学习
Java爬虫领域最强大的框架是JSoup:可直接解析具体的URL地址(即解析对应的HTML),提供了一套强大的API,包括可以通过DOM.CSS选择器,即类似jQuery方式来取出和操作数据.主要功能 ...
随机推荐
- mysql性能优化分析 --- 上篇
概要 之前看过<高性能mysql>对mysql数据库有了系统化的理解,虽然没能达到精通,但有了概念,遇到问题时会有逻辑条理的分析; 问题 问题:公司xxx页面调用某个接口时,loading ...
- Charles+iPhone配置ssl证书
Charles+iPhone配置ssl证书 一.手机 1. 配置代理 设置->无线局域网->选和电脑同一网络的无线->配置代理->手动 服务器配置电脑的IP,端口设置为8888 ...
- JavaScript代码规范
变量名:驼峰命名法(首单词小写,后面每个单词首字母大写) firstName = "John"; lastName = "Doe"; price = 19.90 ...
- openwrt查看flash、RAM、CPU信息
1.查看Flash容量大小(存储空间,可以理解为电脑的硬盘) root@OpenWrt:/# dmesg |grep spi |grep Kbytes #查看Flash容量[ 0.660000 ...
- Java生日计算年龄工具
package com.web.backend.util; import java.util.Calendar;import java.util.Date; /** * @Author: SongZS ...
- 饮冰三年-人工智能-Python-29瀑布流
多适用于:整版以图片为主,大小不一的图片按照一定的规律排列的网页布局. 1:创建model类,并生成数据表 from django.db import models # Create your mod ...
- postgre 常用语法,如 group_concat用法
1.查询postgre的表所有字段列 select table_name, column_name from information_schema.columns where table_schema ...
- 关于DataTable 判断 列名是否存在的方法中英文符合不区分?
最近系统出现一个错误,排查了很久,发现判断DataTable 列名是否存在时,发现一个坑,居然不会区分中英文符合. 有谁知道其中的原理?先记录一下,免得以后忘记这个天坑. 一. 先初始化一个DataT ...
- Selenium自动化测试之元素定位
步骤: 1.通过前端工具,查看元素的属性 2.通过属性定位 iddriver.findElement(By.id("kw")) namedriver.findElement(By. ...
- (译)(function (window, document, undefined) {})(window, document); 真正的意思
由于非常感兴趣, 我查询了很多关于IIFE (immediately-invoked function expression)的东西, 如下: (function (window, document, ...