【转】Python——读取html的table内容
Python——python读取html实战,作业7(python programming)

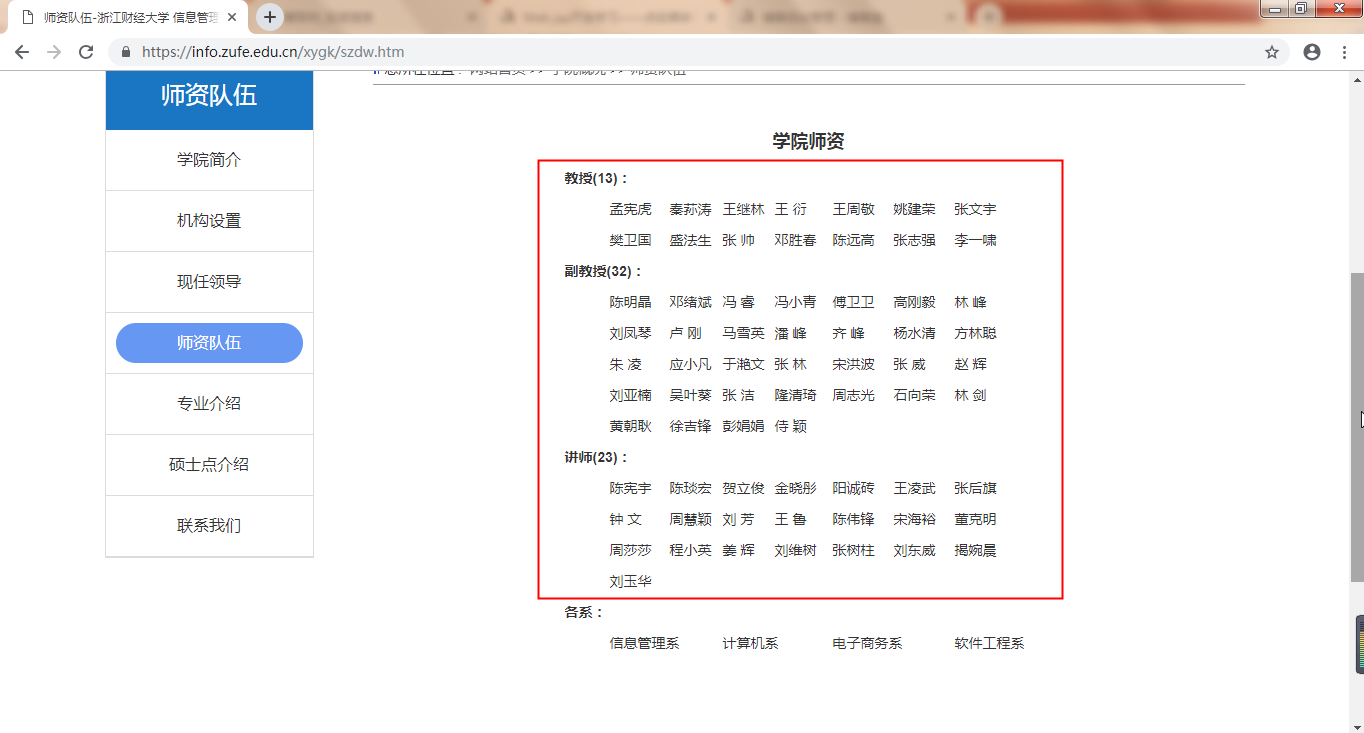
查看源码,观察html结构


# -*- coding: utf-8 -*-
from lxml.html import parse
from urllib.request import urlopen
import pandas as pd # 可能爬的这个网页比较特殊,需要写下面两句话
import ssl
ssl._create_default_https_context = ssl._create_unverified_context # 根据链接获得整个html放到doc中
parsed = parse(urlopen('https://info.zufe.edu.cn/xygk/szdw.htm'))
doc = parsed.getroot() #读取html中的table
# 用列表来存老师名字
all_teachers=[]
# 用字典保存主页链接
link_dic={}
# 用字典保存职称
zhicheng={} # 找到html中有<table></table>的所有table,以列表的形式返回给tables
tables = doc.findall('.//table')
# 我们要的是第一个table
content=tables[0].text_content()
tds = tables[0].findall('.//td') # 一条条遍历所有td里的内容
for td in tds:
# 判断当前属于哪个职称,再给zc赋值
zhi=td.findall('.//strong')
if len(zhi)!=0:
print(zhi[0].text_content())
zc=zhi[0].text_content() print(td.text_content())
link=td.findall('.//a')
if len(link)!=0:
print("link",link[0].get('href'))
# td.text_content()存的就是姓名
# 保存链接
link_dic[td.text_content()]=link[0].get('href')
# 保存老师姓名
all_teachers.append(str(td.text_content()))
# 保存职称
zhicheng[td.text_content()]=zc print("张 帅的主页链接是:",link_dic["张 帅"])
print("张 帅的职称链接是:",zhicheng["张 帅"]) # 后面的各系不属于老师去掉
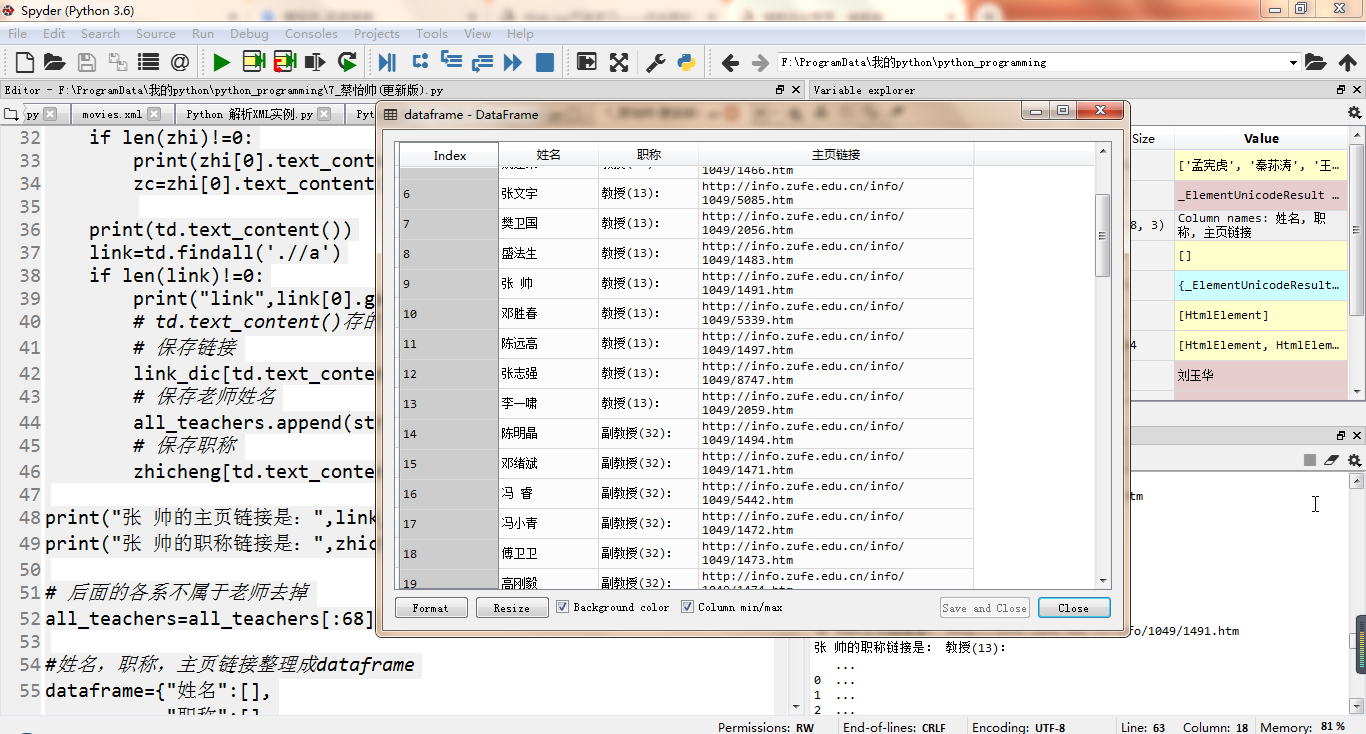
all_teachers=all_teachers[:68] #姓名,职称,主页链接整理成dataframe
dataframe={"姓名":[],
"职称":[],
"主页链接":[]}
for teacher in all_teachers:
dataframe["姓名"].append(teacher)
dataframe["职称"].append(zhicheng[teacher])
dataframe["主页链接"].append(link_dic[teacher])
dataframe=pd.DataFrame(dataframe)
print(dataframe)

【转】Python——读取html的table内容的更多相关文章
- Python读取文件编码及内容
Python读取文件编码及内容 最近做一个项目,需要读取文件内容,但是文件的编码方式有可能都不一样.有的使用GBK,有的使用UTF8.所以在不正确读取的时候会出现如下错误: UnicodeDecode ...
- python读取文件指定行内容
python读取文件指定行内容 import linecache text=linecache.getline(r'C:\Users\Administrator\Desktop\SourceCodeo ...
- Python读取word文档内容
1,利用python读取纯文字的word文档,读取段落和段落里的文字. 先读取段落,代码如下: 1 ''' 2 #利用python读取word文档,先读取段落 3 ''' 4 #导入所需库 5 fro ...
- python 读取指定div的内容
# -*- coding:utf-8 -*- from bs4 import BeautifulSoup import urllib.request import re # 如果是网址,可以用这个办法 ...
- Python读取本地文档内容并发送邮件
当需要将本地某个路径下的文档内容读取后并作为邮件正文发送的时候可以参考该文,使用到的模块包括smtplib,email. #! /usr/bin/env python3 # -*- coding:ut ...
- Python 读取文件下所有内容、获取文件名、截取字符、写回文件
# coding=gbk import os import os.path #读取目录下的所有文件,包括嵌套的文件夹 def GetFileList(dir, fileList): newDir ...
- python读取指定内存的内容
import ctypes as ct t = ct.string_at(0x211000, 20) # (addr, size) print t 最好不要用解释性语言来开发底层,一般用C.
- Python读取文件内容与存储
Python读取与存储文件内容 一..csv文件 读取: import pandas as pd souce_data = pd.read_csv(File_Path) 其中File_path是文件的 ...
- python读取excel中单元格的内容返回的5种类型
(1) 读取单个sheetname的内容. 此部分转自:https://www.cnblogs.com/xxiong1031/p/7069006.html python读取excel中单元格的内容返回 ...
随机推荐
- Centos7 安装gitLab
我这里使用的是centos 7 64bit,我试过centos 6也是可以的! 1. 安装依赖软件 yum -y install policycoreutils openssh-server open ...
- Spring Boot 2.x 编写 RESTful API (六) 事务
用Spring Boot编写RESTful API 学习笔记 Transactional 判定顺序 propagation isolation 脏读 不可重复读 幻读 不可重复读是指记录不同 (upd ...
- spring整合junit进行测试
以下只是一个模板,大家记得改变配置文件 package cn.itcast.crm.dao; import org.junit.Test; import org.junit.runner.RunWit ...
- loj121-动态图连通性
Solution 线段树分治, 然后直接在线段树上dfs, 在进入/回溯的过程中维护并查集的merge/split. 对于split操作, 可以在merge时按秩合并, 然后利用栈记录, split时 ...
- 关于解决Tomcat服务器Connection reset by peer 导致的宕机
org.apache.catalina.connector.ClientAbortException: java.io.IOException: Connection reset by peer at ...
- zookeeper集群的简单搭建
zookeeper简单介绍 zookeeper是一个为分布式应用提供一致性服务的软件,它是开源的Hadoop项目的一个子项目,并根据google发表的一篇论文来实现的.zookeeper为分布式系统提 ...
- ShoppingCart
数据库设计 表结构 [dbo].[AdminInfo] AdminID, AdminName, AdminPassword, RoleID [dbo].[BK_Car] ID, CarID, ISBN ...
- git使用kdiff3合并乱码问题
https://blog.csdn.net/u011008029/article/details/72644515 在合并代码过程中发现kdiff打开的文件都是乱码,解决方案如下: 第一步:点击Set ...
- js的数组的一些操作
1 arr.reduce let xxx = arr.reduce( function (pv, cv, ci ,arr) { return }[, init_val] ) 对arr的每个元素,执行匿 ...
- 【linux】工作中linux系统常用命令操作整理
1.Linux如何查看端口 使用lsof(list open files)命令,lsof -i:端口号 用于查看某一端口的占用情况,比如查看8000端口使用情况,lsof -i:8000. 或者使用n ...