【转】Python——读取html的table内容
Python——python读取html实战,作业7(python programming)

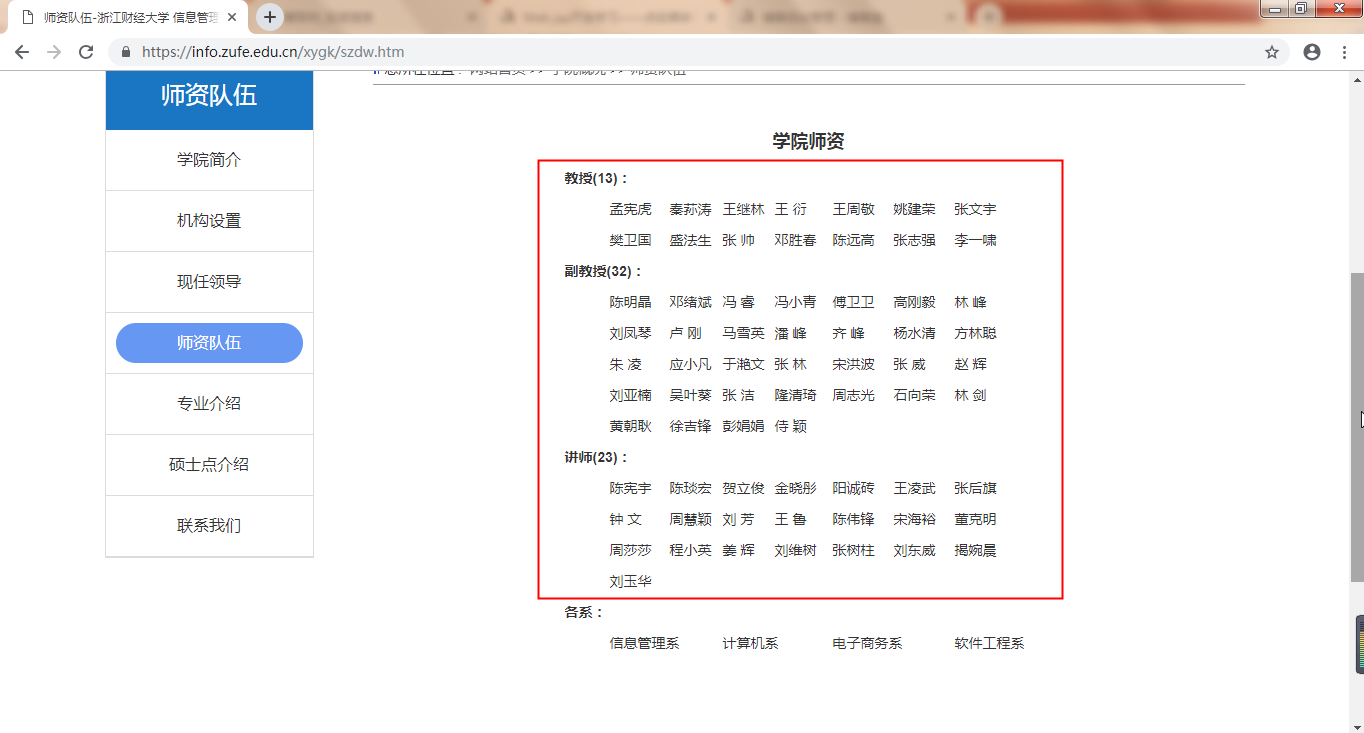
查看源码,观察html结构


# -*- coding: utf-8 -*-
from lxml.html import parse
from urllib.request import urlopen
import pandas as pd # 可能爬的这个网页比较特殊,需要写下面两句话
import ssl
ssl._create_default_https_context = ssl._create_unverified_context # 根据链接获得整个html放到doc中
parsed = parse(urlopen('https://info.zufe.edu.cn/xygk/szdw.htm'))
doc = parsed.getroot() #读取html中的table
# 用列表来存老师名字
all_teachers=[]
# 用字典保存主页链接
link_dic={}
# 用字典保存职称
zhicheng={} # 找到html中有<table></table>的所有table,以列表的形式返回给tables
tables = doc.findall('.//table')
# 我们要的是第一个table
content=tables[0].text_content()
tds = tables[0].findall('.//td') # 一条条遍历所有td里的内容
for td in tds:
# 判断当前属于哪个职称,再给zc赋值
zhi=td.findall('.//strong')
if len(zhi)!=0:
print(zhi[0].text_content())
zc=zhi[0].text_content() print(td.text_content())
link=td.findall('.//a')
if len(link)!=0:
print("link",link[0].get('href'))
# td.text_content()存的就是姓名
# 保存链接
link_dic[td.text_content()]=link[0].get('href')
# 保存老师姓名
all_teachers.append(str(td.text_content()))
# 保存职称
zhicheng[td.text_content()]=zc print("张 帅的主页链接是:",link_dic["张 帅"])
print("张 帅的职称链接是:",zhicheng["张 帅"]) # 后面的各系不属于老师去掉
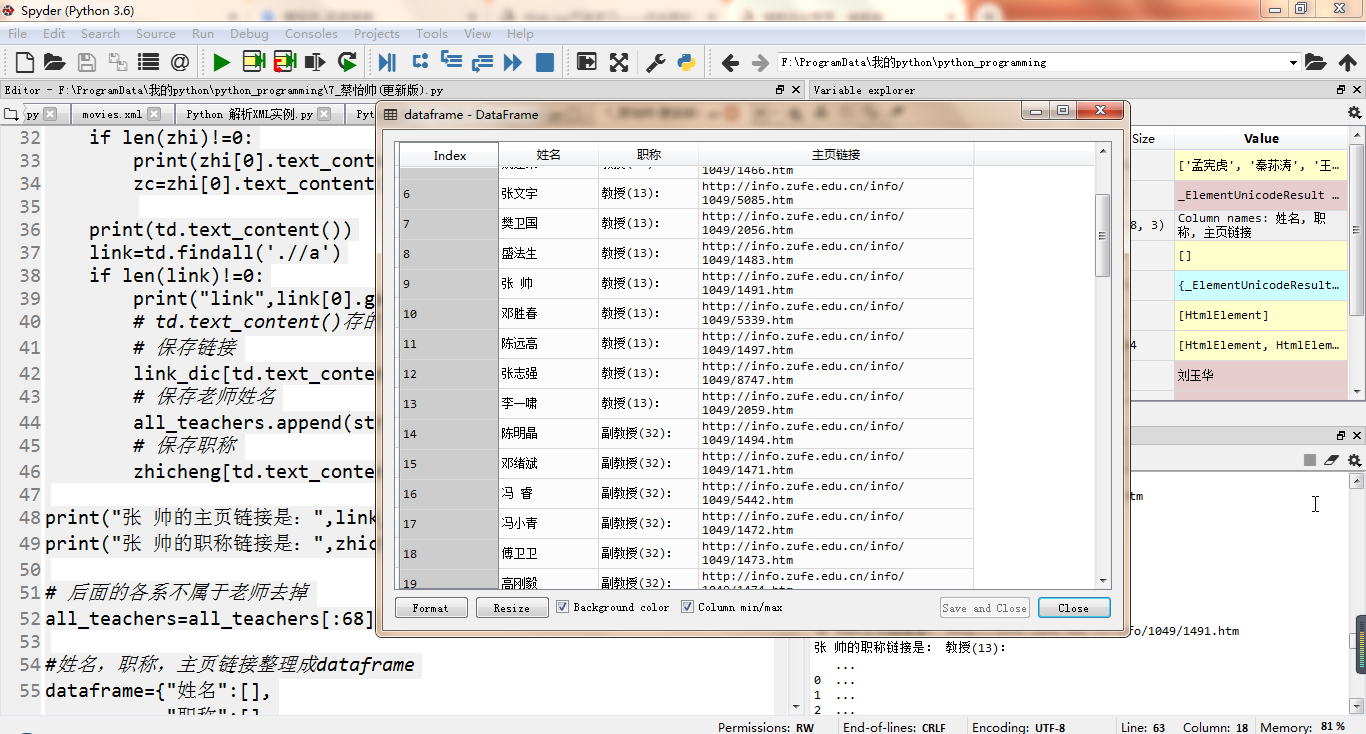
all_teachers=all_teachers[:68] #姓名,职称,主页链接整理成dataframe
dataframe={"姓名":[],
"职称":[],
"主页链接":[]}
for teacher in all_teachers:
dataframe["姓名"].append(teacher)
dataframe["职称"].append(zhicheng[teacher])
dataframe["主页链接"].append(link_dic[teacher])
dataframe=pd.DataFrame(dataframe)
print(dataframe)

【转】Python——读取html的table内容的更多相关文章
- Python读取文件编码及内容
Python读取文件编码及内容 最近做一个项目,需要读取文件内容,但是文件的编码方式有可能都不一样.有的使用GBK,有的使用UTF8.所以在不正确读取的时候会出现如下错误: UnicodeDecode ...
- python读取文件指定行内容
python读取文件指定行内容 import linecache text=linecache.getline(r'C:\Users\Administrator\Desktop\SourceCodeo ...
- Python读取word文档内容
1,利用python读取纯文字的word文档,读取段落和段落里的文字. 先读取段落,代码如下: 1 ''' 2 #利用python读取word文档,先读取段落 3 ''' 4 #导入所需库 5 fro ...
- python 读取指定div的内容
# -*- coding:utf-8 -*- from bs4 import BeautifulSoup import urllib.request import re # 如果是网址,可以用这个办法 ...
- Python读取本地文档内容并发送邮件
当需要将本地某个路径下的文档内容读取后并作为邮件正文发送的时候可以参考该文,使用到的模块包括smtplib,email. #! /usr/bin/env python3 # -*- coding:ut ...
- Python 读取文件下所有内容、获取文件名、截取字符、写回文件
# coding=gbk import os import os.path #读取目录下的所有文件,包括嵌套的文件夹 def GetFileList(dir, fileList): newDir ...
- python读取指定内存的内容
import ctypes as ct t = ct.string_at(0x211000, 20) # (addr, size) print t 最好不要用解释性语言来开发底层,一般用C.
- Python读取文件内容与存储
Python读取与存储文件内容 一..csv文件 读取: import pandas as pd souce_data = pd.read_csv(File_Path) 其中File_path是文件的 ...
- python读取excel中单元格的内容返回的5种类型
(1) 读取单个sheetname的内容. 此部分转自:https://www.cnblogs.com/xxiong1031/p/7069006.html python读取excel中单元格的内容返回 ...
随机推荐
- Vue实现树形下拉框
Vue自身并没有实现树形下拉框的组件,找了很多资料,最后在Github上找了个插件vue-treeselect,功能还是比较全的,模糊搜索.多选.延迟加载.异步搜索.排序,自定义.Vuex支持等等.这 ...
- gRPC源码分析(c++)
首先需要按照grpc官网上说的办法从github上下载源码,编译,然后跑一跑对应的测试代码.我分析的代码版本为v1.20.0. 在cpp的helloworld例子中,client端,第一个函数是创建c ...
- 2019-04-10 集成JasperReport
1. 报表的制作过程为 ① 制作.jrxml报表模板文件,并编译成.jasper ② 代码处理.jasper文件并填充数据进行输出 2. 一开始是打算使用iReport作为模板制作工具的,但是有以下局 ...
- 结巴分词出现AttributeError: 'float' object has no attribute 'decode'错误
将data转变为str格式 inputfile = 'comment2.csv'outputfile = 'comment2_cut.txt'datas = pd.read_csv(inputfile ...
- Luogu4492 [HAOI2018]苹果树 【动态规划】
题目分析: 思路不难想,考虑三个dp状态$f,g,d$. $g[i]$表示有$i$个点的堆的数量 $d[i]$表示有$i$个点的情况下所有的方案数中点到根的距离和 $f[i]$表示要求的答案. 不难发 ...
- ubuntu18.04安装mysql
ubuntu18.04中,默认情况下mysql默认包含在apt软件存储库中,要安装它只需要更新服务器上的包索引并安装默认包apt-get. 1.安装mysql sudo apt-get update ...
- zabbix模板化监控
zabbix模板化监控 1. 实验简述 在zabbix监控中,有很多组的概念,具体有以下几种: 1. 主机和主机组,相同类型/应用的主机,可以归属于同一个主机组 2. item和application ...
- Java 集合系列之一:JCF集合框架概述
容器,就是可以容纳其他Java对象的对象.Java Collections Framework(JCF)为Java开发者提供了通用的容器 java集合主要划分为四个部分: Collection(Lis ...
- Java IO系列之一:IO
1. 概述 Java IO一般包含两个部分: 1.java.io包中堵塞型IO: 2.java.nio包中的非堵塞型IO,通常称为New IO. java.io包下,分为四大块近80个类: 1.基于字 ...
- 半导体制造、Fab以及Silicon Processing的基本知识
本文转载自微信公众号 - 手机技术资讯 , 链接 https://mp.weixin.qq.com/s/602xLKXcIw4ccTnhvDP1xw