Django自定义分页
分页
自定义分页
稳扎稳打版
def book(request):
# 从URL取参数(访问的页码)
page_num = request.GET.get("page")
try:
# 将取出的page转换为int类型
page_num = int(page_num)
except Exception as e:
# 当输入的页码不是正经数字的时候 默认返回第一页的数据
page_num = 1 # 数据库总数据是多少条
total_count = models.Book.objects.all().count() # 每一页显示多少条数据
per_page = 10 # 总共需要多少页码来展示
total_page, m = divmod(total_count, per_page)
if m:
total_page += 1 # 如果输入的页码数超过了最大的页码数,默认返回最后一页
if page_num > total_page:
page_num = total_page # 定义两个变量从哪里开始到哪里结束
data_start = (page_num - 1) * 10
data_end = page_num * 10 # 页面上总共展示多少页码
max_page = 11
if total_page < max_page:
max_page = total_page # 把从URL中获取的page_num 当做是显示页面的中间值, 那么展示的便是当前page_num 的前五页和后后五页
half_max_page = max_page // 2
# 根据展示的总页码算出页面上展示的页码从哪儿开始
page_start = page_num - half_max_page
# 根据展示的总页码算出页面上展示的页码到哪儿结束
page_end = page_num + half_max_page # 如果当前页减一半 比1还小, 不然页面上会显示负数的页码
if page_start <= 1:
page_start = 1
page_end = max_page
# 如果 当前页 加 一半 比总页码数还大, 不然页面上会显示比总页码还大的多余页码
if page_end >= total_page:
page_end = total_page
page_start = total_page - max_page + 1 # 从数据库取值, 并按照起始数据到结束数据展示
all_book = models.Book.objects.all()[data_start:data_end] # 自己拼接分页的HTML代码
html_str_list = [] # # 加上首页
html_str_list.append('<li><a href="/book/?page=1">首页</a></li>') # 断一下 如果是第一页,就没有上一页
if page_num <= 1:
html_str_list.append('<li class="disabled"><a href="#"><span aria-hidden="true">«</span></a></li>')
else:
# 不是第一页,就加一个上一页的标签
html_str_list.append('<li><a href="/book/?page={}"><span aria-hidden="true">«</span></a></li>'.format(page_num - 1)) for i in range(page_start, page_end + 1):
# 如果是当前页就加一个active样式类
if i == page_num:
tmp = '<li class="active"><a href="/book/?page={0}">{0}</a></li>'.format(i)
else:
tmp = '<li><a href="/book/?page={0}">{0}</a></li>'.format(i) html_str_list.append(tmp) # 判断,如果是最后一页,就没有下一页
if page_num >= total_page:
html_str_list.append('<li class="disabled"><a href="#"><span aria-hidden="true">»</span></a></li>')
else:
# 不是最后一页, 就加一个下一页标签
html_str_list.append('<li><a href="/book/?page={}"><span aria-hidden="true">»</span></a></li>'.format(page_num + 1)) # 加上尾页
html_str_list.append('<li><a href="/book/?page={}">尾页</a></li>'.format(total_page)) page_html = "".join(html_str_list)
return render(request, "book.html", {"all_book":all_book, "page_html":page_html})
稳扎稳打版
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>书籍列表</title>
<link rel="stylesheet" href="/static/bootstrap/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<table class="table table-bordered">
<thead>
<tr>
<th>序列号</th>
<th>ID值</th>
<th>书名</th>
<th>时间</th>
</tr>
{% for book in all_book %}
<tr>
<td>{{ forloop.counter }}</td>
<td>{{ book.id }}</td>
<td>{{ book.name }}</td>
<td>{{ book.date }}</td>
</tr>
{% endfor %}
</thead>
</table>
<nav aria-label="Page navigation">
<ul class="pagination">
{{ page_html|safe }}
</ul>
</nav>
</div>
</body>
</html>
book.html
封装保存版
class Page(object):
def __init__(self, page_num, total_count, url_prefix, per_page=10, max_page=11):
"""
:param page_num: 当前页码数
:param total_count: 数据总数
:param url_prefix: a标签href的前缀
:param per_page: 每页显示多少条数据
:param max_page: 页面上最多显示几个页码
"""
self.url_prefix = url_prefix
self.max_page = max_page
# 总共需要多少页码来展示
total_page, m = divmod(total_count, per_page)
if m:
total_page += 1
self.total_page = total_page try:
# 将取出的page转换为int类型
page_num = int(page_num)
except Exception as e:
# 当输入的页码不是正经数字的时候 默认返回第一页的数据
page_num = 1
# 如果输入的页码数超过了最大的页码数,默认返回最后一页
if page_num > total_page:
page_num = total_page
self.page_num = page_num # 定义两个变量保存数据从哪儿取到哪儿
self.data_start = (page_num - 1) * 10
self.data_end = page_num * 10 # 页面上总共展示多少页码
if total_page < self.max_page:
self.max_page = total_page half_max_page = self.max_page // 2
# 页面上展示的页码从哪儿开始
page_start = page_num - half_max_page
# 页面上展示的页码到哪儿结束
page_end = page_num + half_max_page
# 如果当前页减一半 比1还小, 不然页面上会显示负数的页码
if page_start <= 1:
page_start = 1
page_end = self.max_page
# 如果 当前页 加 一半 比总页码数还大, 不然页面上会显示比总页码还大的多余页码
if page_end >= total_page:
page_end = total_page
page_start = total_page - self.max_page + 1
self.page_start = page_start
self.page_end = page_end @property
def start(self):
return self.data_start @property
def end(self):
return self.data_end def page_html(self):
# 自己拼接分页的HTML代码
html_str_list = []
# # 加上首页
html_str_list.append('<li><a href="{}?page=1">首页</a></li>'.format(self.url_prefix))
# 断一下 如果是第一页,就没有上一页
if self.page_num <= 1:
html_str_list.append('<li class="disabled"><a href="#"><span aria-hidden="true">«</span></a></li>')
else:
# 不是第一页,就加一个上一页的标签
html_str_list.append('<li><a href="{}?page={}"><span aria-hidden="true">«</span></a></li>'.format(self.url_prefix, self.page_num - 1)) for i in range(self.page_start, self.page_end + 1):
# 如果是当前页就加一个active样式类
if i == self.page_num:
tmp = '<li class="active"><a href="{0}?page={1}">{1}</a></li>'.format(self.url_prefix, i)
else:
tmp = '<li><a href="{0}?page={1}">{1}</a></li>'.format(self.url_prefix, i) html_str_list.append(tmp) # 判断,如果是最后一页,就没有下一页
if self.page_num >= self.total_page:
html_str_list.append('<li class="disabled"><a href="#"><span aria-hidden="true">»</span></a></li>')
else:
# 不是最后一页, 就加一个下一页标签
html_str_list.append('<li><a href="{}?page={}"><span aria-hidden="true">»</span></a></li>'.format(self.url_prefix, self.page_num + 1)) # 加上尾页
html_str_list.append('<li><a href="{}?page={}">尾页</a></li>'.format(self.url_prefix, self.total_page)) page_html = "".join(html_str_list)
return page_html
封装保存版
def publisher(request):
page_num = request.GET.get("page")
total_count = models.Publisher.objects.all().count()
# 调用封装的Page类,传入相应的参数
page_obj = Page(page_num, total_count, url_prefix="/publisher/", per_page=10, max_page=11)
all_publisher = models.Publisher.objects.all()[page_obj.start:page_obj.end]
page_html = page_obj.page_html()
return render(request, "publisher.html", {"publisher": all_publisher, "page_html": page_html})
封装版使用指南
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>图书列表</title>
<link rel="stylesheet" href="/static/bootstrap/css/bootstrap.min.css">
</head>
<body>
<div class="container">
<table class="table table-bordered">
<thead>
<tr>
<td>序列号</td>
<td>ID值</td>
<td>出版社</td>
<td>时间</td>
</tr>
</thead>
<tbody>
{% for pub in publisher %}
<tr>
<th>{{ forloop.counter }}</th>
<th>{{ pub.id }}</th>
<th>{{ pub.name }}</th>
<th>{{ pub.date }}</th>
</tr>
{% endfor %}
</tbody>
</table>
<nav aria-label="Page navigation">
<ul class="pagination">
{{ page_html|safe }}
</ul>
</nav>
</div>
</body>
</html>
封装版对应的HTML参考
效果图如下:
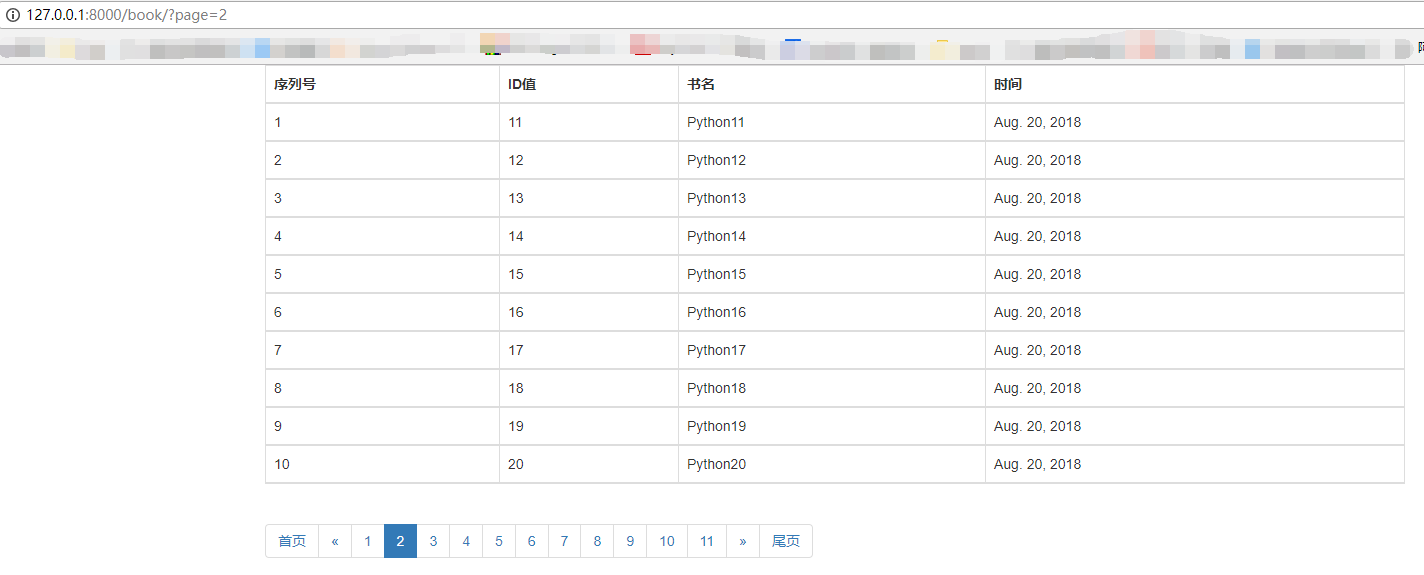
Django自定义分页的更多相关文章
- Django自定义分页并保存搜索条件
Django自定义分页并保存搜索条件 1.自定义分页组件pagination.py import copy class Pagination: def __init__(self, current_p ...
- Django自定义分页、bottle、Flask
一.使用django实现之定义分页 1.自定义分页在django模板语言中,通过a标签实现; 2.前段a标签使用<a href="/user_list/?page=1"> ...
- Django 自定义分页类
分页类代码: class Page(object): ''' 自定义分页类 可以实现Django ORM数据的的分页展示 输出HTML代码: 使用说明: from utils import mypag ...
- Django—自定义分页
分页功能在每个网站都是必要的,对于分页来说,其实就是根据用户的输入计算出应该显示在页面上的数据在数据库表中的起始位置. 确定分页需求: 1. 每页显示的数据条数 2. 每页显示页号链接数 3. 上一页 ...
- Django - 自定义分页、FBV和CBV
一.自定义分页(优势在于能够保存搜索条件) """ 分页组件使用示例: 1) 先取出所有数据USER_LIST 2) 实例化: obj = Pagination(requ ...
- Django——自定义分页(可调用)
1.view from django.shortcuts import render,HttpResponse # Create your views here. from app01.models ...
- django 自定义分页,网址存储缓存,CBV
1. 通过切片控制分页 自定义分页: from django.shortcuts import render # Create your views here. from app01.models i ...
- django自定义分页控件
1.准备数据 在models创建测试表 from django.db import models class Host(models.Model): hostname = models.CharFie ...
- Django 自定义分页
1.路由 urls.py url(r'^index2.html/', views.index2), 2.views.py def index2(request): # 数据总条数 当前页 每页显示条数 ...
随机推荐
- 或许,挂掉的点总是出人意料(hw其实蛮有好感的公司)
1:问了有没有考研的打算,为什么: ` 实验室指导自己的两个学长, 他们两个都是不考研党派,当然两个学长本科都进入了不错的公司hw,xm,耳濡目染就自己也就不想去考研了: 跟一些已经工作的程序员聊天, ...
- C#学习笔记---C#操作SQL数据库
C#操作SQL数据库 Connection(连接)对象 连接字符串: 形式1.”server=;uid=;pwd=;database=” 形式2.”server=;Intergrated Securi ...
- 电脑出现问题如何修复Windows 10
也许Windows 10无法启动.或者它可能会靴子,但会崩溃很多.在任何一种情况下,您都需要在使用PC之前解决问题.以下是修复Windows 10的几种方法. 方法1:使用Windows启动修复 如果 ...
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- uml类图关系
原文地址http://www.jfox.info/uml-lei-tu-guan-xi-fan-hua-ji-cheng-shi-xian-yi-lai-guan-lian-ju-he-zu-he 在 ...
- Flink Pre-defined Timestamp Extractors / Watermark Emitters(预定义的时间戳提取/水位线发射器)
https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/event_timestamp_extractors.html 根据官网 ...
- Koa 中 ejs 模板的使用
ejs的基本使用 安装 koa-views 和 ejs npm install --save koa-views/cnpm install --save koa-views npm install e ...
- 转://linux下的CPU、内存、IO、网络的压力测试工具与方法介绍
转载地址:http://wushank.blog.51cto.com/3489095/1585927 一.对CPU进行简单测试: 1.通过bc命令计算特别函数 例:计算圆周率 echo "s ...
- 12-tinyMCE文本编辑器+图片上传预览+页面倒计时自动跳转
文本编辑器插件:1.将tinymce文件夹全部复制到webContent下2.tinymce/js目录下放 jquery等三个js文件3.语言包:tinymce/js/tinymce/langs目录下 ...
- Linux下Power Management开发总结
本文作为一个提纲挈领的介绍性文档,后面会以此展开,逐渐丰富. 1. 前言 在 <开发流程>中介绍了PM开发的一般流程,重点是好的模型.简单有效的接口参数.可量化的测试环境以及可独性强的输出 ...