Hadoop学习笔记(1):概念和整体架构
- Hadoop简介和历史
- Hadoop架构体系
- Master和Slave节点
- 数据分析面临的问题和Hadoop思想
由于工作原因,必须学习和深入一下Hadoop,特此记录笔记。
什么是hadoop?
Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行实作而成。
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。它使应用程序与成千上万的独立计算的电脑和PB级的数据。
hadoop历史
Hadoop由 Apache Software Foundation 于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
- Hadoop Common:在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
- HDFS:Hadoop分布式文件系统(Distributed File System)-HDFS(Hadoop Distributed File System)
- MapReduce:并行计算框架,0.20前使用org.apache.hadoop.mapred旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API
- Apache HBase:分布式NoSQL列数据库,类似谷歌公司BigTable。
- Apache Hive:构建于hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能。Hive最初由Facebook贡献。
- Apache Mahout:机器学习算法软件包。
- Apache Sqoop:结构化数据(如关系数据库)与Apache Hadoop之间的数据转换工具。
- Apache ZooKeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
- Apache Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
hadoop平台子项目
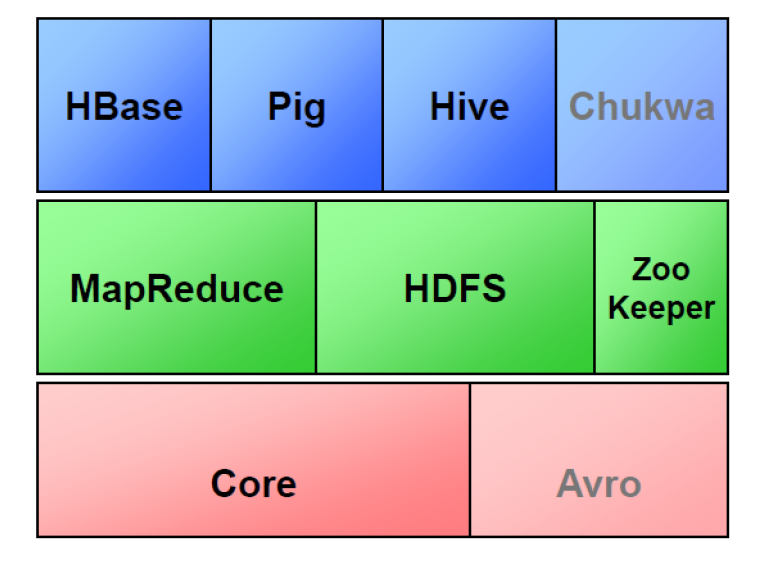
现在普遍认为整个Apache Hadoop“平台”包括Hadoop内核、MapReduce、Hadoop分布式文件系统(HDFS)以及一些相关项目,有Apache Hive和Apache HBase等等。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
如图,最下面一层就是hadoop的核心代码,核心代码之上实现了两个最核心的功能:MapReduce和HDFS,这是hadoop的两大支柱!因为hadoop是Java写的,为了方便其他对Java语言不熟悉的程序员,在这之上又有Pig,这是一个轻量级的语言,用户可以使用Pig用于数据分析和处理,系统会自动把它转化为MapReduce程序。
还有一个Hive,很重要!这是一个传统的SQL到MapReduce的映射器,面向传统的数据库工程师。但是不支持全部SQL。还有一个子项目叫HBase,一个非关系数据库,NoSQL数据库,数据是列存储的,提高响应速度,减少IO量,可以做成分布式集群。
ZooKeeper负责服务器节点和进程间的通信,是一个协调工具,因为Hadoop的几乎每个子项目都是用动物做logo,故这个协调软件叫动物园管理员。
Hadoop架构
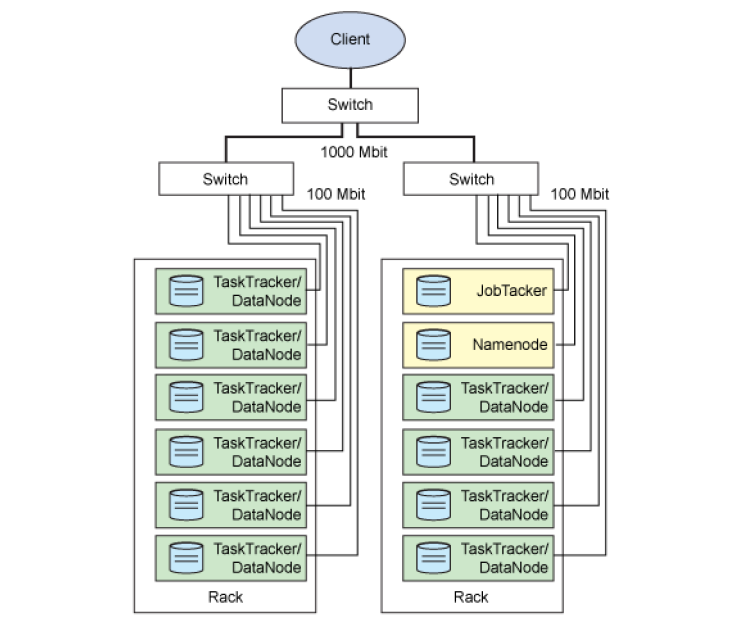
如图,两个服务器机柜,每个圆柱代表一个物理机,各个物理节点通过网线连接,连接到交换机,然后客户端通过互联网来访问。其中各个物理机上都运行着Hadoop的一些后台进程。
Namenode

也叫名称节点,是HDFS的守护程序(一个核心程序),对整个分布式文件系统进行总控制,会纪录所有的元数据分布存储的状态信息,比如文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,还有对内存和I/O进行集中管理,用户首先会访问Namenode,通过该总控节点获取文件分布的状态信息,找到文件分布到了哪些数据节点,然后在和这些节点打交道,把文件拿到。故这是一个核心节点。
不过这是个单点,发生故障将使集群崩溃。
Secondary Namenode
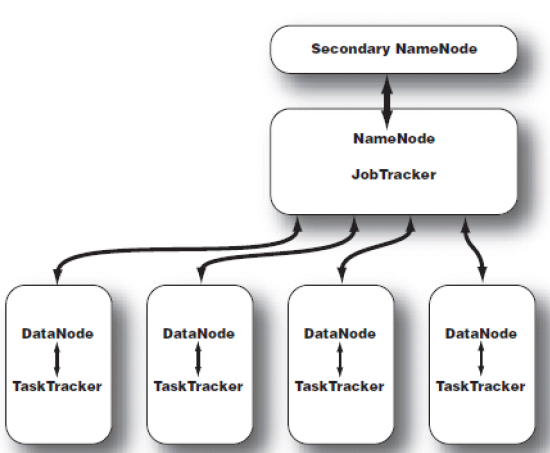
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。从它的名字上看,它给人的感觉就像是NameNode的备份,比如有人叫它第二名称节点,仿佛给人感觉还有后续……但它实际上却不完全是。
最好翻译为辅助名称节点,或者检查点节点,它是监控HDFS状态的辅助后台程序,可以保存名称节点的副本,故每个集群都有一个,它与NameNode进行通讯,定期保存HDFS元数据快照。NameNode故障可以作为备用NameNode使用,目前还不能自动切换。但是功能绝不仅限于此。所谓后备也不是它的主要功能。后续详细解释。
DataNode

叫数据节点,每台从服务器节点都运行一个,负责把HDFS数据块读、写到本地文件系统。这三个东西组成了Hadoop平台其中一个支柱——HDFS体系。
再看另一个支柱——MapReduce,有两个后台进程。
JobTracker
叫作业跟踪器,运行到主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。
Hadoop的原则就是就近运行,数据和程序要在同一个物理节点里,数据在哪里,程序就跑去哪里运行。这个工作是JobTracker做的,监控task,还会重启失败的task(于不同的节点),每个集群只有唯一一个JobTracker,类似单点的nn,位于Master节点(稍后解释Master节点和slave节点)。
TaskTracker
叫任务跟踪器,MapReduce体系的最后一个后台进程,位于每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务,它与jobtracker交互通信,可以告知jobtracker子任务完成情况。
Master与Slave
Master节点:运行了Namenode、或者Secondary Namenode、或者Jobtracker的节点。还有浏览器(用于观看管理界面),等其它Hadoop工具。Master不是唯一的!
Slave节点:运行Tasktracker、Datanode的机器。
数据分析者面临的问题和Hadoop的思想
目前需要我们处理的数据日趋庞大,无论是入库和查询,都出现性能瓶颈,用户的应用和分析结果呈整合趋势,对实时性和响应时间要求越来越高。使用的模型越来越复杂,计算量指数级上升。
故,人们希望出现一种技术或者工具来解决性能瓶颈,在可见未来不容易出现新瓶颈,并且学习成本尽量低,使得过去所拥有的技能可以平稳过渡。比如SQL、R等,还有转移平台的成本能否控制最低,比如平台软硬件成本,再开发成本,技能再培养成本,维护成本等。
而Hadoop就能解决如上问题——分而治之,化繁为简。
Hadoop学习笔记(1):概念和整体架构的更多相关文章
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
随机推荐
- KMP算法求解
// KMP.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include<iostream> using namespac ...
- ABP文档 - Javascript Api
文档目录 本节内容: AJAX Notification Message UI Block & Busy Event Bus Logging Other Utility Functions A ...
- 在线浏览PDF之PDF.JS (附demo)
平台之大势何人能挡? 带着你的Net飞奔吧!:http://www.cnblogs.com/dunitian/p/4822808.html#skill 下载地址:http://mozilla.gith ...
- JavaScript 开发规范
本篇主要介绍JS的命名规范.注释规范以及框架开发的一些问题. 目录 1. 命名规范:介绍变量.函数.常量.构造函数.类的成员等等的命名规范 2. 注释规范:介绍单行注释.多行注释以及函数注释 3. 框 ...
- MyEclipse生成注册码
今天正在使用的MyEclipse出现了使用过期,在网上发现一个可以生成注册码的程序,现在分享给各位. /** * myEclipse生成注册码 * 点击顶部:MyEclipse --> subs ...
- Xamarin+Prism开发详解五:页面布局基础知识
说实在的研究Xamarin到现在,自己就没设计出一款好的UI,基本都在研究后台逻辑之类的!作为Xamarin爱好者,一些简单的页面布局知识还是必备的. 布局常见标签: StackLayout Abso ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- pdo的使用
PHP 数据对象 (PDO) 扩展为PHP访问数据库定义了一个轻量级的一致接口. PDO 提供了一个数据访问抽象层,这意味着,不管使用哪种数据库,都可以用相同的函数(方法)来查询和获取数据. PDO随 ...
- 在vim中使用查找命令查找指定字符串
要自当前光标位置向上搜索,请使用以下命令: /pattern Enter 其中,pattern 表示要搜索的特定字符序列. 要自当前光标位置 ...
- JavaScript中String对象的方法介绍
1.字符方法 1.1 charAt() 方法,返回字符串中指定位置的字符. var question = "Do you like JavaScript?"; alert(ques ...