(六) 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法。大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层中每个参数的偏导数,BP算法正是用来求解网络中参数的偏导数问题的。
先上一张吊炸天的图,可以看到BP的工作原理:
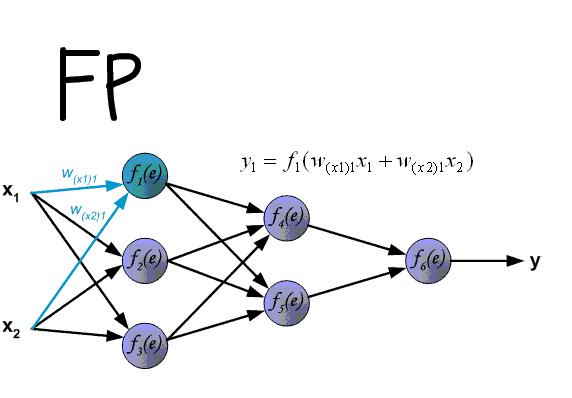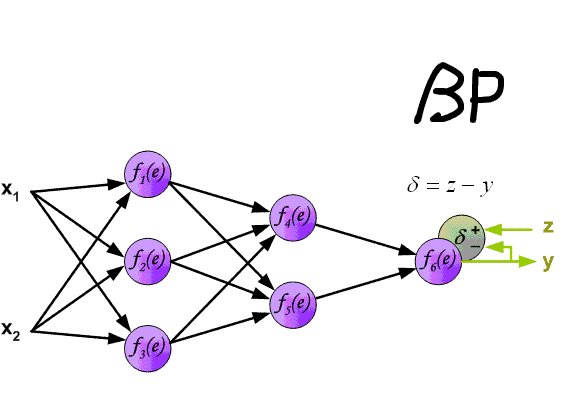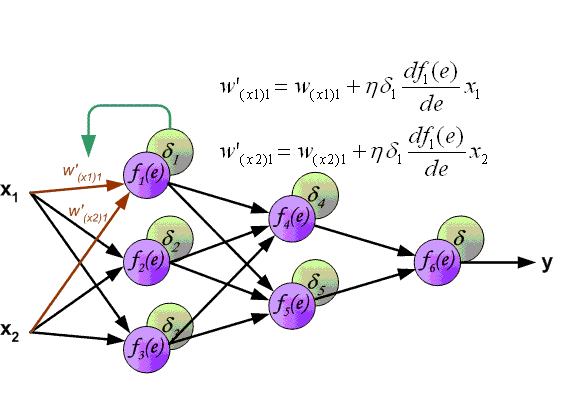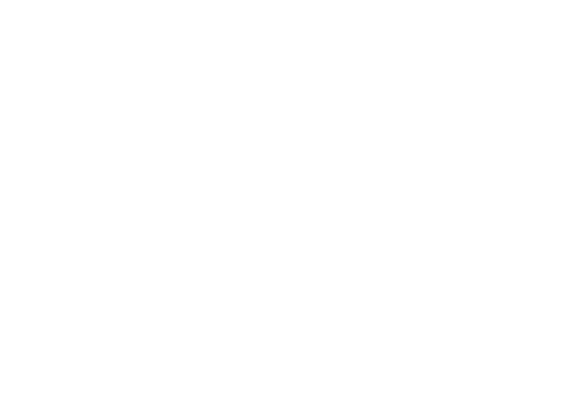
下面来看BP算法,用m个训练样本集合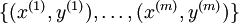 来train一个神经网络,对于该模型,首先需要定义一个代价函数,常见的代价函数有以下几种:
来train一个神经网络,对于该模型,首先需要定义一个代价函数,常见的代价函数有以下几种:
1)0-1损失函数:(0-1 loss function)

2)平方损失函数:(quadratic loss function)
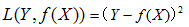
3)绝对值损失函数:(absolute loss function)
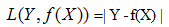
4)负log损失函数(log loss function)
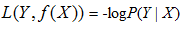
损失函数的意义在于,假设函数(hypothesis function,即模型)的输出与数据标签的值月接近,损失函数越小。反之损失函数越大,这样减小损失函数的值,来求得最优的参数即可,最后将最优的参数带入带假设函数中,即可求得最终的最优的模型。
在Neurons Network中,对于一个样本(x,y),其损失函数可表示为
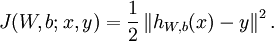
上式这种形式是平方损失函数(注意若采用交叉熵损失则与此损失形式不一样),对于所有的m个样本,对于所有训练数据,总的损失函数为:
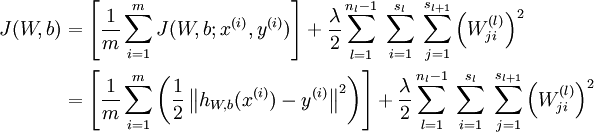
上式中第一项为均方误差项,第二项为正则化项,用来限制权重W的大小,防止over-fitting,也即贝叶斯学派所说的给参数引入一个高斯先验的MAP(极大化后验)方法。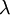 为正则项的参数,用来控制两项的相对重要性, 比如若很大时,参数W,b必须很小才能使得最终的损失函数J(W,b) 很小。
为正则项的参数,用来控制两项的相对重要性, 比如若很大时,参数W,b必须很小才能使得最终的损失函数J(W,b) 很小。
常见的分类或者回归问题,都可以用这个损失函数,注意分类时标签y是离散值,回归时对于sigmod函数y为(0,1)之间的连续值。对于tanh为(-1,1)之间的值。
BP算法的目标就是求得一组最优的W、b ,使得损失函数 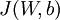 的值最小
的值最小
首先将每个参数 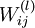 和
和 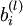 初始化为一个很小的随机值(比如说,使用正态分布
初始化为一个很小的随机值(比如说,使用正态分布 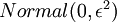 生成的随机值,其中
生成的随机值,其中 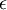 设置为
设置为 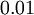 ),然后使用批梯度下降算法来优化 和 的值,因为 是非凸函数,即存在不止一个极值点,梯度下降算法很可能会收敛到局部极值处,但通常效果很不错(在浅层网络中,比如说三层),需要强调的是要将参数随机初始化,而不是全部置0,如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有hidden unit
),然后使用批梯度下降算法来优化 和 的值,因为 是非凸函数,即存在不止一个极值点,梯度下降算法很可能会收敛到局部极值处,但通常效果很不错(在浅层网络中,比如说三层),需要强调的是要将参数随机初始化,而不是全部置0,如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有hidden unit  ,
,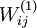 都会取相同的值,那么对于任何输入
都会取相同的值,那么对于任何输入  都会有:
都会有: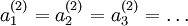 ),随机初始化会消除这种对称效果。
),随机初始化会消除这种对称效果。
批梯度下降算法中,每一次迭代都按照如下公式对参数 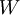 和
和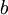 进行更新:
进行更新:
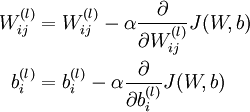
其中J(W,b)包含了所有的样本,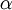 是学习速率,对于多层神经网络,如何计算每一层参数的偏导数是关键问题,BP算法正使用来计算每一项的偏导数的。
是学习速率,对于多层神经网络,如何计算每一层参数的偏导数是关键问题,BP算法正使用来计算每一项的偏导数的。
首先来看对于单个样例,参数 和 的偏导数分别为 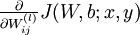 和
和 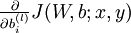
有了单个样例的偏导数后,根据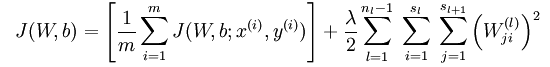 ,就可以很好求出损失函数 的偏导数:
,就可以很好求出损失函数 的偏导数:
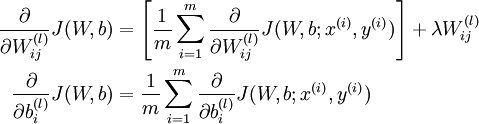
并不作用于bais unit b,所以第二个式子中没有第二项。
先看如下的式子,l+1层的输入等于l层的加权输出求和,即
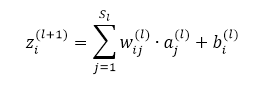
课件hidden layer的输入z为参数的方程,为了求解对每个样本中参数 和 的偏导数,可以用根据链式求导法则有:
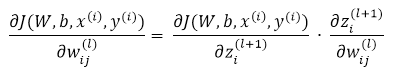

我们把上边的第一项称为残差,有了以上链式求导的思想,为了求得各个参数的偏导数,我们需要求得每一层的每个单元的残差。下面反向传播算法的思路:
1)给定 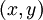 ,我们首先进行“前向传导”,计算出网络中所有的激活值,包括
,我们首先进行“前向传导”,计算出网络中所有的激活值,包括 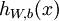 的输出值
的输出值
2)对第  层的每个节点 ,计算出其“残差”
层的每个节点 ,计算出其“残差” 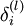 ,该残差表明节点对最终输出值的残差产生多少影响
,该残差表明节点对最终输出值的残差产生多少影响
3)对于最终的输出节点,直接算出网络产生的激活值与实际值之间的差距,将这个差距定义为 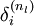
4)对于隐藏单元,将第 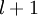 层节点的残差的加权平均值计算 ,这些节点以
层节点的残差的加权平均值计算 ,这些节点以 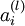 作为输入到 层
作为输入到 层
下面将给出反向传导算法的细节:
1)进行前馈传导计算,利用前向传导公式,得到 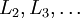 直到输出层
直到输出层 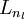 的激活值。
的激活值。
2)对于第 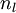 层(输出层)的每个输出单元 ,我们根据以下公式计算残差:
层(输出层)的每个输出单元 ,我们根据以下公式计算残差:
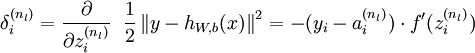
推倒:
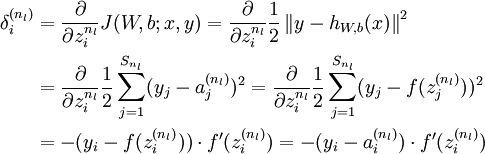
3)对 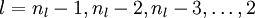 的各个层,第 层的第 个节点的残差计算方法如下:
的各个层,第 层的第 个节点的残差计算方法如下:
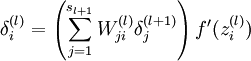
有了最后一层的层差,可以计算前一层的残差:
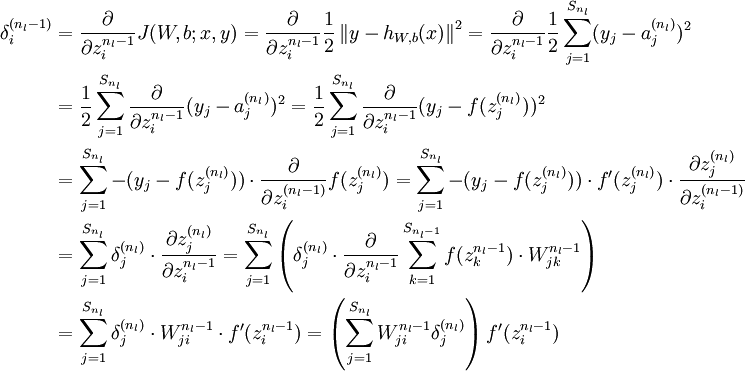
4)将上式中的 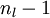 与 的关系替换为 与 的关系,就可以得到:
与 的关系替换为 与 的关系,就可以得到:
5)根据链式求导法则,计算方法如下:
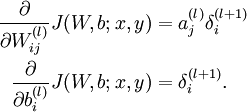
- 其中,第二项的计算公式如下:
- 根据
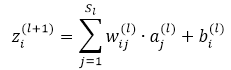 ,有:
,有: 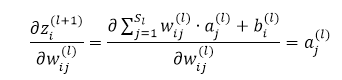

概括一下整个算法:
1)进行前馈传导计算,利用前向传导公式,得到 直到输出层 的激活值。
2)对输出层(第 层),计算:
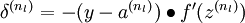
3)对于 的各层,计算:
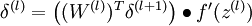
4)计算最终需要的偏导数值:
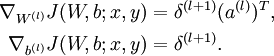
指的注意的是在以上的第2步和第3步中,我们需要为每一个 单元 值计算其 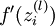 。假设
。假设 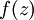 是sigmoid函数,f'(z)=f(z)*(1-f(z)),并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的
是sigmoid函数,f'(z)=f(z)*(1-f(z)),并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的 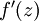 表达式,就可以计算得到
表达式,就可以计算得到 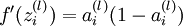 。
。
经过以上步骤,已经可以求出每个参数的偏导数,下一步就是更新参数,即使得参数沿梯度方向下降,下面给出梯度下降算法伪代码:
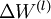 是一个与矩阵
是一个与矩阵 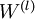 维度相同的矩阵,
维度相同的矩阵,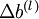 是一个与
是一个与 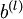 维度相同的向量。注意这里“”是一个矩阵,而不是“
维度相同的向量。注意这里“”是一个矩阵,而不是“ 与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
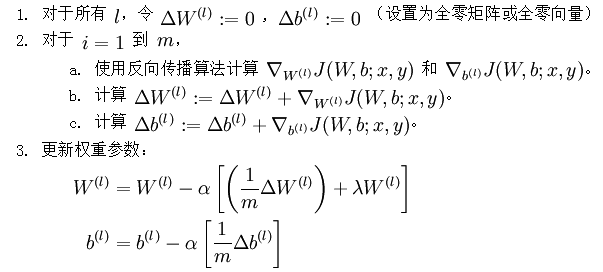
不断更新W,b的值,直到W,b不再变化为止,即网络达到收敛。
有机会再补上代码#24!!
(六) 6.2 Neurons Networks Backpropagation Algorithm的更多相关文章
- CS229 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
- (六) 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- (六) 6.3 Neurons Networks Gradient Checking
BP算法很难调试,一般情况下会隐隐存在一些小问题,比如(off-by-one error),即只有部分层的权重得到训练,或者忘记计算bais unit,这虽然会得到一个正确的结果,但效果差于准确BP得 ...
- (六)6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- The Backpropagation Algorithm
https://page.mi.fu-berlin.de/rojas/neural/chapter/K7.pdf 7.1 Learning as gradient descent We saw in ...
- BP反向传播算法的工作原理How the backpropagation algorithm works
In the last chapter we saw how neural networks can learn their weights and biases using the gradient ...
- CS229 6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- CheeseZH: Stanford University: Machine Learning Ex4:Training Neural Network(Backpropagation Algorithm)
1. Feedforward and cost function; 2.Regularized cost function: 3.Sigmoid gradient The gradient for t ...
- CS229 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
随机推荐
- iOS数组和字符串的转化
NSMutableArray *components = [messageStr componentsSeparatedByString:@"*"] ; 反过来为 NSStrig ...
- Android屏幕适应详解(二)
android应用自适应多分辨率的解决方法 1. 首先是建立多个layout文件夹(drawable也一样). 在res目录下建立多个layout文件夹,文件夹名称为layout-800x480等. ...
- ExtJs之进度条实现
慢慢按书上的作. <!DOCTYPE html> <html> <head> <title>ExtJs</title> <meta h ...
- hdu 4768 Flyer 二分
思路:由于最多只有一个是奇数,所以二分枚举这个点,每次判断这个点的左边区间段所有点的和作为 二分的依据. 代码如下: #include<iostream> #include<cstd ...
- zoj 3513 Human or Pig 博弈论
思路:P态的所有后继全为H态,第一个格子为P态,第一行和第一列为H态. 代码如下: #include<iostream> #include<cstdio> #include&l ...
- unity Transform Find 的用法!!!
用法: Transform Find(String name) 1.查找名为name的(transform.gameObject)直接子物体并返回该子物体的Transform属性.不能是孙子物体或更低 ...
- iOS js oc相互调用(JavaScriptCore)(二)
下来我们使用js调用iOS js调用iOS分两种情况 一,js里面直接调用方法 二,js里面通过对象调用方法 首先我们看第一种,直接调用方法. 其中用到了iOS的block 上代码 -(void)we ...
- python urllib2的proxyhandler
1. 再a方法中新建了个opener,使用了代理: proxydict = {} proxydict['http'] = "http://%s:%s"%(ip,port) #pri ...
- Hibernate笔记——第一个简单实例
1. 首先进行框架配置 导包 hibernate配置xml文件 ======================= 2. 创建并配置POJO类 Hibernate是操作持久化层的框架,和数据库打交道,其 ...
- k近邻法
k近邻法(k nearest neighbor algorithm,k-NN)是机器学习中最基本的分类算法,在训练数据集中找到k个最近邻的实例,类别由这k个近邻中占最多的实例的类别来决定,当k=1时, ...